


|
JoeNotCharles posted:Absolutely - both wxPython and PyQT are fantastic GUI frameworks (I prefer PyQT). Google will find you lots of good stuff. Have you implemented any applications that bundle either framework? I downloaded wxPython's OS X framework and the disk image is around 33 MB. I don't know what that says about how much space it occupies in frozen form, but it definitely turned me off to messing around with it initially. I'd be curious to see if PyQt is any easier or harder to bundle with a frozen Python application.
|
 #
?
May 14, 2008 04:20
#
?
May 14, 2008 04:20
|
|


|

|
| # ? May 15, 2024 03:51 |
|
|
Milde posted:Have you implemented any applications that bundle either framework? I downloaded wxPython's OS X framework and the disk image is around 33 MB. I don't know what that says about how much space it occupies in frozen form, but it definitely turned me off to messing around with it initially. I'd be curious to see if PyQt is any easier or harder to bundle with a frozen Python application. No, I've never been responsible for the final packaging.
|
|
#
?
May 14, 2008 04:38
|
|

|
I'm having trouble coding some basic javascript form validation. Essentially I have a textfield, and a select-option-box in a form, and I would like ONLY one of these to have data in it before continuing. It's a game website, users either enter a specific game number they wish to play, or select from EASY, MEDIUM, or HARD which will randomnly pick a game from those categories. This was my attempt to simple check to make sure that at least one form field was specified, and it works. (code vv) code:code:
|
|
#
?
May 14, 2008 07:19
|
|

|
Rather than worry about it, why don't you just give one of them precedence? Like if the user select both options just take the one in the text field. If you really care about it, then what you want is the XOR operator. It returns true only when one of the options are selected. So you could do: code:
|
|
#
?
May 14, 2008 09:30
|
|


|
MEAT TREAT posted:XOR Thanks this has actually been helpful. While I don't think I need to use the actual XOR operator, the use of a boolean variable will be part of the solution I would think. I also think the problem I was having was the use of '!==' instead of '!=', but I'll try and write a better solution then what I had previously. This is part of an assignment I am doing so while it would make sense to assign some sort of priority to which field to use, I'm restricted to the assignment specification. Thanks for your help.
|
|
#
?
May 14, 2008 09:43
|
|
|
sc0tty posted:
code:
|
|
#
?
May 14, 2008 19:58
|
|

|
drcru posted:Do we have an Actionscript thread? My head is going to explode trying to sort out that language. There's a flash megathread.
|
|
#
?
May 14, 2008 20:08
|
|

|
mantaworks posted:There's a flash megathread. Thanks I see it now.
|
|
#
?
May 15, 2008 23:40
|
|


|
Can anyone familiar with manipulating resources in Windows explain why a successful call to UpdateResource would add a resource of the same name rather than replace it? The following code executes without error, but when I inspect the resource file with Resource Hacker, I see that there are now two entries under IMAGE for 872. This is an unmanaged resource by the way, and I hardcoded the language code, which is the same as the resource I want to replace, so I don't think that's the issue. code:
|
|
#
?
May 16, 2008 05:43
|
|

|
Okay, it's PHP time. I made a simply upload script for a site. It worked fine in the test directory I uploaded it to, but when I reconfigured it for the site root, I get the following error:quote:Warning: move_uploaded_file(): SAFE MODE Restriction in effect. The script whose uid/gid is 11299/500 is not allowed to access <siteroot> owned by uid/gid 99/99 in <siteroot>/fatcontroller/fileuploader.php on line 18 Line 18 is as follows: code:
|
|
#
?
May 16, 2008 15:51
|
|
|
You don't own the root directory, and so you can only put the file uploader in a subdirectory.
|
|
#
?
May 16, 2008 16:04
|
|

|
It was already in a subdirectory, but I solved the problem by, well, actually creating the target directory that the file was meant to be moved to. I forgot to copy the directory layout from the test area to the site root  EDIT:- In my defence, though, that error message was absolutely no loving use whatsoever. Rohaq fucked around with this message at 19:08 on May 16, 2008 |
|
#
?
May 16, 2008 16:15
|
|
|
I'm trying to move to GIT from SVN, but I'm having a hard time with my deployment scripts. I'm using capistrano to deploy the application, originally the repository setting was: set :repository, "http://svn.mydomain.com/svn/jonnii/project/trunk" I changed that to: set :repository, "ssh://mydomain.com:1337/home/jonnii/apps/ae.git" Which can get the latest revision locally, but when it logs into the remote machine and executes: git clone ssh://mydomain.com:1337/home/jonnii/apps/project.git /target/directory it falls over with: ** [out] ssh: pumpqin.com:1337: Name or service not known ** [out] fatal: ** [out] The remote end hung up unexpectedly ** [out] fetch-pack from 'ssh://pumpqin.com:1337/home/jonnii/apps/ae.git' failed. I've monkeyed around with the repository uri and nothing i try seems to work. pumpqin.com is in the hosts file pointing to 127.0.0.1. Any ideas?
|
|
#
?
May 17, 2008 00:49
|
|
|
jonnii posted:I've monkeyed around with the repository uri and nothing i try seems to work. pumpqin.com is in the hosts file pointing to 127.0.0.1. Any ideas? A lot of programs don't support specifying SSH port numbers, and I don't think OpenSSH even supports it that way (it has a command line flag for it). I usually just sidestep the issue entirely and add a Host entry to my SSH config. You'll need the config wherever you're running ssh or ssh-based utilities (it sounds like you'll need it on more than one machine in this case). Add something like this to ~/.ssh/config: code:
|
|
#
?
May 17, 2008 00:55
|
|
|
Factor Mystic posted:
After some investigation, it seems resource names are actually numbers, not strings. So when I updated the resource, I added a new resource named "872", which of course isn't the same as #872, hence the apparent duplication in Resource Hacker, which doesn't differentiate the data type of the resource name. What happened was, the signature on PInvoke.net has string type for that parameter. Welp.
|
|
#
?
May 17, 2008 03:42
|
|
 about editing resource files
about editing resource files
|
Milde posted:... This worked perfectly, thanks!
|
|
#
?
May 17, 2008 19:12
|
|
|
There's not really a thread for this so I'll ask it here. Does anyone have experience with doing FFT on the GPU? I've been looking around for a few libraries and I'm having difficulties getting the ones I've found working. Also, should we have a GPU programming thread?
|
|
#
?
May 21, 2008 20:41
|
|

|
StickGuy posted:There's not really a thread for this so I'll ask it here. Does anyone have experience with doing FFT on the GPU? I've been looking around for a few libraries and I'm having difficulties getting the ones I've found working. quote:Also, should we have a GPU programming thread?  After finally getting 169.09 drivers installed to make it stop complaining, every example program either seg faults or halts my display. After finally getting 169.09 drivers installed to make it stop complaining, every example program either seg faults or halts my display.
|
|
#
?
May 22, 2008 18:12
|
|

|
I have a task that I am not sure how to go about accomplishing. I work at a veterinarian, and a few times a month we have to send out those wonderful reminder cards in the mail to remind people that their pets vaccines have expired or their yearly exam is coming up (or they missed it) etc etc. This is all fine and good, but the owners of the clinic like to see statistics on how many customers actually keep up with things. The software we have that generates these reminders does nothing to produce statistics for you. That is currently all done by hand. We print the list of reminders for an upcoming month, and then a few months later we go back and print the reminders that are still outstanding for that same month and compare the lists. Guess who has to do this now? Me! The first time I was asked to do this I was floored. I still can't believe they do this all by hand. It is dull, slow, and prone to mistakes. What a giant waste of time! Quite frankly, I don't want to do it! If only humanity had invented some sort of machine or device that could tally data for you! I have since discovered that the software will export these lists to a csv file. So now I just have to go about parsing this into usable data, and this is where I ask for your help as I can't quite think of a good way to go about it. Should I dump the data into a database? If so, how exactly would I store it? Do I create a table for each dump, or just have one large table that I then store the insert date on each row (so I can limit myself to a specific dump by a where clause (where insert_date = 0608) or something). They print and mail lots of cards, and they actually like stats gathered for a specific month on multiple occasions, to see how quickly people are "complying". For example, they will print a list two months in advance of a month, one month in advance, and then one, two, and six months after. As I type this I realize now that maybe it really is just a question of writing horribly complicated (to me anyway) sql so maybe this should be in the sql thread? Any thoughts or ideas are appreciated!
|
|
#
?
May 22, 2008 21:06
|
|
 Associate Christ
Associate Christ
|
Post a line or two of the CSV that it exports, some guess as to how many lines it spits out (hundreds/thousands/millions), and the format that you want the statistics in. Chances are this is a really trivial job that doesn't need a database, and I can replace your job with a Perl script.
|
|
#
?
May 22, 2008 21:15
|
|
|
Kaluza-Klein posted:veterinarian reminder cards What is the volume of cards? Are we talking 200 a month or 20000 a month? How much time are you going to spend on the project? If it's low volume you can probably do everything you need in Excel. This has the upside of leaving something fairly simple (although maybe tedious) to maintain should you no longer be in your current position one day. The database solution will be nice, but make sure it's something that has enough data to warrant a full database. There's no reason to make a complex solution to what may be a simple problem.
|
|
#
?
May 22, 2008 21:19
|
|
|
The info it spits out looks something like the following. This is a dump for 06/01/08 through 06/30/08. This list has around 500 lines. I don't think they ever go much past a thousand. First item is the client id number, then you get first and last name, then you get the pet name, then you have species, and then the reminders for that pet follow. So if a client has reminders for two pets they each get a line. Reminders come in the form of code/description/due date. (I won't use code tags so remember that this is wrapped text) " 52","Rosemary","Phips","SERENA","FE","YEXSR","SENIOR EXAM, BLOODWORK, FECAL","06/28/2008","","","","","","","","","","","","","","","","","","","","","","","","" " 139","Carol","Wood","MOBY","CA","S141","CANINE RABIES 3 YEAR VACCINE","06/26/2008","","","","","","","","","","","","","","","","","","","","","","","","" " 185","Rebecca","Smith","WEBSTER","CA","YEX","YEARLY EXAM, BLOODWORK, FECAL","06/01/2008","4417","HW/EHRLICHIA/LYME TEST-YEARLY","06/01/2008","4506","JR. WELLNESS BLOODWK-DOGYEARLY","06/01/2008","","","","","","","","","","","","","","","","","","" " 268","Nancy","Phillips","WAGS","CA","YEXSR","SENIOR EXAM, BLOODWORK, FECAL","06/10/2008","S404","FECAL EXAM-YEARLY","06/10/2008","4417","HW/EHRLICHIA/LYME TEST-YEARLY","06/10/2008","4504","SR. WELLNESS BLOODWORK-YEARLY","06/10/2008","","","","","","","","","","","","","","","" " 300","Larry","Stevens","IVY","CA","YEXSR","SENIOR EXAM, BLOODWORK, FECAL","06/26/2008","S404","FECAL EXAM-YEARLY","06/26/2008","4417","HW/EHRLICHIA/LYME TEST-YEARLY","06/26/2008","","","","","","","","","","","","","","","","","","" " 300","Larry","Stevens","MADDIE","CA","4417","HW/EHRLICHIA/LYME TEST-YEARLY","06/26/2008","YEXSR","SENIOR EXAM, BLOODWORK, FECAL","06/26/2008","","","","","","","","","","","","","","","","","","","","","" Then I will export the data again using the same dates in July. This time I will get a slightly bigger list. If a client came in and did everything they were "reminded" to do, then they won't appear on the list (since the reminder for them will now be changed to 06/2009). Sometimes a client will do a few items on a list, but not all, so some of their items for that pet will still appear, while some will be gone. The list that is printed is broken down by client/pet. We can count the number of pets listed on the first print (done before the month) and then when we print the list after the month has past we do the same count and hopefully get a smaller number (since pets who showed up are no longer on the list). Then we subtract and that is the number of pets who showed up and we can produce a nice percentage figure. We go back a few months later and send out more cards for the remaining people and count who is left on the list. So far this is all very straight forward. There are a few issues that make this a bit more tedious than it sounds. We calculate these percentages for each REMINDER CODE that we are interested in (about a dozen codes)! So we have to count all the reminder codes of a specific type. Boring as hell and takes forever. The first thing is when a pet has their reminded exam, but declines the reminded bloodwork (or fecal, or heart worm test, etc) the computer generates a new reminder for them. This is a "declined fecal" reminder lets say. The date for this reminder will be the day they declined it. So if I bring my pet in during June and decline to have a Bordetella vaccine, I will show up on the lists printed after June with a "DECLINED" reminder for whatever items I decided not to do. These have to be accounted for because they will throw off the simple subtraction we try to do. The other issue is when a person with things due in July has their appointment a bit early and shows up in June. Now if they have declined anything those decline codes will appear on lists for June that we print (once June has passed). So basically, any client/pet that isn't on the first list (printed before things are due) is totally ignored. I imagine this is very doable in excel but I have ZERO excel experience and I don't have access to it at home. DB's I can handle if it doesn't get too crazy.
|
|
#
?
May 22, 2008 22:48
|
|
|
Kaluza-Klein posted:I have since discovered that the software will export these lists to a csv file. So now I just have to go about parsing this into usable data, and this is where I ask for your help as I can't quite think of a good way to go about it. Unless you're already really familiar with databases, I wouldn't bother with that. If it's low-volume enough that you can do it by hand right now you should be able to just store the .csv files somewhere and read them each time you want to process them. Python has an excellent CSV parsing module - I'd just save the .csv file into a directory tree organized by date, and write a Python script to read them and calculate stats. EDIT: it all depends on what tools you're familiar with. If you already have some experience with databases, import the .csv files into SQLite (so you don't need to run a server or anything); if you're good with Excel macros, import them into that. I'm most familiar with programming/Python scripting, so that's what came to mind first. JoeNotCharles fucked around with this message at 22:52 on May 22, 2008 |
|
#
?
May 22, 2008 22:49
|
|
|
JoeNotCharles posted:EDIT: it all depends on what tools you're familiar with. If you already have some experience with databases, import the .csv files into SQLite (so you don't need to run a server or anything); if you're good with Excel macros, import them into that. I'm most familiar with programming/Python scripting, so that's what came to mind first. This is really what I was trying to say. Don't spend a lot of time in Excel if you're not familiar with it. I only recommended Excel since it's more likely that someone can work through Excel than other tools. Use the tool that you're familiar with that will get the job done. What database software do you have available? What programming languages do you know well?
|
|
#
?
May 23, 2008 18:59
|
|
|
I am concerned this question is going to be innapropriate or way way below the kind of questions in this thread so keep that in mind. I'm writing a simple program in Pascal that calculates prime numbers, for a high school level assignment. Beyond that it's going to do a bunch of other stuff that we've learnt just this year, output to files and search and sort and stuff. I have three different functions for finding prime numbers. The first one is a slow, simple one, and the 2nd one is still simple but way faster because it only goes to sqrt(input). and the 3rd one, 6k+-1 wiki calls it, is hard to explain, so see here (http://en.wikipedia.org/wiki/Primality_testing#Na.C3.AFve_methods). but in my program, the 3rd one whould be way faster than the 2nd, but it isn't, and I want to know why that is. code:
|
|
#
?
May 25, 2008 08:13
|
|

|
I'm not entirely sure, and would have to program out an example to be completely sure (but not in Pascal), that the point of the 6k+/-1 optimization is that you can skip 6 each time, with the exception of your base cases (2 and 3). I.e. start at 6; check 5 and 7, go to 12. check 11 and 13, go to 18, much like the += 2 to check odds only. e: The code looked like it was checking every number for being of the form 6k+/-1, and then going from there, but I could be wrong. Not that great at reading Pascal. narbsy fucked around with this message at 15:49 on May 25, 2008 |
|
#
?
May 25, 2008 08:32
|
|

|
narbsy posted:I'm not entirely sure, and would have to program out an example to be completely sure (but not in Pascal), that the point of the 6k+/-1 optimization is that you can skip 6 each time, with the exception of your base cases (2 and 3). yeh, thats what mine does now. It may not seem that way because of the bizarre way i did it, which i can probably do better looking at it that way. But surely that isn't making it run 3 times as slow as it should?
|
|
#
?
May 25, 2008 10:30
|
|
|
I wrote a quick version in C# and I get 12s,1s,0.5s for the three different algorithms(I forget the number of iterations), so your algorithms are correct. Your problem may be that you're just doing a lot of work in each iteration of your loop. If you loop through half as many times but do twice as much work then you don't get a speedup. You should try to avoid recomputing values that won't change like sqrt(inp) and count*6 every time through the loop. Also your third case in the inner loop causes an extra count*6 and an extra comparison. Last, you should minimize IO while doing a timing test because it can mess with the results.
|
|
#
?
May 25, 2008 15:53
|
|

|
Sorry, will post in the PHP forum.
ilikechapstick fucked around with this message at 23:36 on May 25, 2008 |
|
#
?
May 25, 2008 23:22
|
|

|
Where the hell do you go that's still teaching Pascal?
|
|
#
?
May 26, 2008 00:44
|
|




|
HB posted:Where the hell do you go that's still teaching Pascal? A regional high school in souther NSW, Australia. State owned but it's pretty good. and thanks 'poopiehead', I'm pretty sure that might be it, I'll try that
|
|
#
?
May 26, 2008 06:53
|
|
|
This is more of a generic structural question, though I'll probably be implementing it in vb.net or C# I've got a series of rows in a dataset that I'm parsing that contain object IDs. The first column is the "container" id, that is, other IDs can belong to it. The second column is the id of the object that belongs to the first. So the data would look like this: code:The problems are: There might be only 1 ID2. There is no upper limit on potentially how many ID2s are related to an ID1. I have to read it in row by row, never knowing if the next row is a new ID1 or a continuation of the old one. This makes multi-dimensional arrays problematic since I'm always redimmingon every pass and it feels inefficient. The sole benefit so far is that the results are sorted in order by ID1 which means I don't have to go zipping up and down the index. Since the data has to be displayed to the user anyway I'm reading it into a datagrid using this loop: code:Does anyone have a more elegant solution? My philosophy is usually "get it to work and polish it later" but this thing is getting a bit out of hand (not shown: a database call for every row to retrieve details about that specific ID2). I've been looking at it too closely for a while now and believe there's something flawed about my loop control but I can't figure what it is even with some stepping through and watch monitoring.
|
|
#
?
May 26, 2008 09:24
|
|


|
HB posted:Where the hell do you go that's still teaching Pascal? I think it's a staple of 6th form (high school) computing teaching in the UK as well.
|
|
#
?
May 26, 2008 13:08
|
|

|
Scaramouche posted:
For starters, get rid of your redundant lines of code. You've got two lines that are the same in both "if/else" paths, and the first path has nothing but those two lines, making it useless. Also looking at this code, it's not going to add the data from the last read ProdID, as it only adds it when it encounters a new ID2. You will need to duplicate the "datagrid.rows.Add(accumulated ID2s linked to ID1)" line after your "for" block. Your intID > 0 check seems out of place. If you want to make sure you have a valid intID, don't mix it up with the check to add the accumulated ID2s to the ID1 row. Make sure when you're adding your ID2 data you don't link it to the current ID1, as you only add the data when the ID1 is different to previously. Here's a slightly tidier version: code:You could also use a hashtable/hashmap or whatever your language has available to store your data. This will let you associate any data with a key (in this case, your ID1). Basically, for each ID1 value in the map, you'd associate it with a dynamic array or vector or list (again, language dependent), and add values on to that list as you get them. This would really only be worth doing if your data was unsorted though. Python example of mapping: code:
|
|
#
?
May 27, 2008 00:28
|
|
|
Moof Strydar posted:Python example of mapping: code:
|
|
#
?
May 28, 2008 06:12
|
|

|
This isn't so much of a programming question, more of just a quick UNIX script. I have a directory full of files, about half of them named DHR_longasstimestamp_someotherbullshit.xls, and half named BOM_longasstimestamp_someotherbullshit.xls, and I need to take the MOST RECENT of each of these files, rename them to DHR.xls, and BOM.xls, respectively, and move them to another directory. I know how to use the 'mv' command to rename and move the files, but how can I make it so that only the two files with the most recent timestamp are renamed and moved?
|
|
#
?
May 28, 2008 20:20
|
|

|
I was making an ASCII table in LaTeX because the ones I've come across don't have the all info I want or aren't a single page to look at. The problem I'm having is of vertical alignment. Basically the layout is 4 tables. What I'd like is the tables to be vertically aligned. Unfortunately they don't seem to want to do that. The problem: 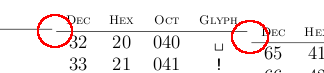 Full code at http://pastebin.com/m3ec6f484
|
|
#
?
May 28, 2008 20:22
|
|
|
Gingerbread Wife posted:This isn't so much of a programming question, more of just a quick UNIX script. There is probably a better way to do it, but you could do something like code:
|
|
#
?
May 28, 2008 20:28
|
|
|
Hey guys, this is a really newbie question but here goes... I'm creating a simple website where I need to display some yearbook ordering information, and have a way to submit names/info and have that stored. I have basic experience with php and mysql, where mysql was running on my computer, and the database would be set up on my computer. What I've never done though, is where I would use a remote server, and store information there. My question is, how do I set it up? Edit: I just realized there was a web design thread, sorry~ Ignore this. Incompl fucked around with this message at 07:00 on May 29, 2008 |
|
#
?
May 29, 2008 06:43
|
|

|

|
| # ? May 15, 2024 03:51 |
|
|
Josh's random thoughts of the days while working on "Yet another boring web page in this enterprise application". 1) The standard of using only up to 80 columns seems to be quite outdated. I had a prof who actually took off marks for this. My monitor supports up to 140 columns (visual studio 2003) at the default font and 1280*1024 resolution. Now, I know different people use different text editors, different font sizes, and so on, but could we please update the standard to 120/130? And then actually ENFORCE it so that I don't have to read stored procedures with lines of 200+ characters. 2) Is it normal that I don't use switch statements? I just find if/else if/else if/else much easier to read and less verbose than a switch statement. The only time I have used a switch statement is for a WinMain loop.. and that's because it's the convention I see everywhere.
|
|
#
?
May 29, 2008 15:37
|
|
