


|
Triple Tech, I suggest going with the EAV approach, and set up insert/update triggers on the 2mil row table that creates EAV entries. Then you can use my historical EAV code to pull a version of the table at any date/time.
|
 #
?
Feb 6, 2009 18:34
#
?
Feb 6, 2009 18:34
|
|

|

|
| # ? Jun 1, 2024 18:57 |
|
|
I was thinking about it the other day and my real beef was how to diff rows in the database-space against rows in the text space... Obviously you just query all the columns and cat them together, and then encapsulate it in a subroutine and forget about how ugly it is. And then just put instance dates in the table whenever a new instance pops up. So it was this overhead that I was originally whining about. Plus the overhead of having to loop through the file's rows in Perl-space as opposed to bcp'ing it and doing it some other magical way. Also supposedly SQL Server's ISS chain handles all this ETL/data warehousing garbage, but I don't know anyone who's willing to put their business on the line like that. Edit: I will never give EAV the time of day. It's like making GBS threads on my ivory tower. I refuse to acknowledge these data warehousing queers. 
Triple Tech fucked around with this message at 18:53 on Feb 6, 2009 |
|
#
?
Feb 6, 2009 18:50
|
|


|
Triple Tech - What is the projected rate of change? If only a small number of entries change you can just set up the table with Record Begin/End Dates and a REC_CURRENT_FLG.
|
|
#
?
Feb 6, 2009 20:15
|
|

|
What is the flag in this model used for? It's not enough to just select the one with the max date? I'm sure the flag helps trivialize this process. It just seems redundant, data-wise. That or make a trigger-powered table of latest entries and just a historical dump table of previous incarnations. Projected rate of change? Should be zero. This processes is sort of an alert filter against real life.
|
|
#
?
Feb 6, 2009 20:57
|
|
|
table - c1 - date_added I would like to write a query that will remove all but one row for each value of c1. E.g. If three rows have a value of 'asdfasdfasdf' for the column c1, I want to delete the first two rows, leaving the most recent.
|
|
#
?
Feb 6, 2009 21:12
|
|

|
Make a join table, containing the max date for each value of c1. Then, using this join table, delete every row in the base table where there is no joined row (e.g. rows that do not satisfy this initial condition).
|
|
#
?
Feb 6, 2009 21:16
|
|
|
Stephen posted:table in SQL Server 2005 code:
|
|
#
?
Feb 6, 2009 21:18
|
|

|
Perfect, thanks guys.
|
|
#
?
Feb 6, 2009 21:39
|
|
|
I don't know if this is the right thread for this, but I have a general question related to hard drives and SQL server. What kind of a performance difference is there between a 15k RPM serial SCSI drive, and a 7K RPM SATA drive? The database being housed on the drives is going to be primarily retrieving data, is it worth the extra cost to go with a 15k drive? Sorry if this is a dumb question, but I'm really not a hardware guy.
|
|
#
?
Feb 6, 2009 22:17
|
|

|
This doesn't directly answer your question, but if you're optimizing for read, you generally want to stripe your storage across physical disks and also look up techniques related to reading data faster (indexes, denormalized tables, things typically opposite writing optimizations).
|
|
#
?
Feb 7, 2009 03:05
|
|
|
Triple Tech posted:What is the flag in this model used for? It's not enough to just select the one with the max date? I'm sure the flag helps trivialize this process. It just seems redundant, data-wise. That or make a trigger-powered table of latest entries and just a historical dump table of previous incarnations. Some people hate using between and think it kills performance, I add it out of habit now so I don't have to argue with people. You can keep a complete history and still have an easy select by using a view. code:
|
|
#
?
Feb 7, 2009 04:56
|
|
|
BizzyLimpkits posted:I don't know if this is the right thread for this, but I have a general question related to hard drives and SQL server. What kind of a performance difference is there between a 15k RPM serial SCSI drive, and a 7K RPM SATA drive? The database being housed on the drives is going to be primarily retrieving data, is it worth the extra cost to go with a 15k drive? Sorry if this is a dumb question, but I'm really not a hardware guy. Joe Chang has some good articles on http://sql-server-performance.com. Joe's page: http://www.sql-server-performance.com/authors/jchang.aspx His recent article on storage: http://www.sql-server-performance.com/articles/per/system_storage_configuration_p1.aspx
|
|
#
?
Feb 7, 2009 10:17
|
|
|
Suppose that I have a table called User and a table called UserLogins. The table UserLogins has the columns UserID, LoginTime (together making the table's Primary Key), and EnteredNumber. EnteredNumber is an integer between 0 and 9 that the user is required to enter when he logs in. Suppose I want to use a query to create a table of users that is sorted according to the total of all the numbers that a user has ever entered when he logged in, in descending order... but if a user has logged in more than 100 times, I only want to take into account the last 100 times he logged in. How do I go about doing this? (The task I am trying to figure out how to do actually has nothing to do with users logging in; I just decided to express it in a generic setting. So if your response is "That sounds ridiculous, why are you trying to do that?", yes it is ridiculous and no I'm not really trying to do that, but please tell me how I would do it anyway.)
|
|
#
?
Feb 7, 2009 16:06
|
|

|
Hammerite posted:Suppose that I have a table called User and a table called UserLogins. The table UserLogins has the columns UserID, LoginTime (together making the table's Primary Key), and EnteredNumber. EnteredNumber is an integer between 0 and 9 that the user is required to enter when he logs in. code:
|
|
#
?
Feb 7, 2009 17:46
|
|
|
Xae posted:Try this: Thanks for the suggestion. I ought to have mentioned that I am constrained to using MySQL. Looking on the internet, I see that ROWNUM is a feature that other RDBMSs have but that MySQL does not have. Is there a way of doing it that will work in MySQL? Edit: Also, I want to make sure it's clear that I want to apply the "most recent 100 logins" requirement to the users individually, not to the output as a whole. So if I have 3 users Adam, Beth and Chloe who have logged in 120, 50 and 90 times respectively, I want to get back three rows: the sum of Adam's last 100 login numbers, the sum of all of Beth's login numbers and the sum of all of Chloe's login numbers. And the only ordering in time of the logins that matters is the ordering of the individual user's logins relative to one another; it shouldn't matter when Chloe's logins occurred relative to Adam's, for example. Hammerite fucked around with this message at 02:18 on Feb 8, 2009 |
|
#
?
Feb 8, 2009 02:12
|
|
|
When doing a query, how do I used one of the value of a query as part of another aspect of the same query? here is the code: code:PS. I know it works becuase when I don't include the "AND... " line, I just get NULLs for that column. EDIT: Could this be an alternative, 2 sequencial select statements? code:cannibustacap fucked around with this message at 07:06 on Feb 8, 2009 |
|
#
?
Feb 8, 2009 06:53
|
|

|
code:
|
|
#
?
Feb 8, 2009 15:25
|
|

|
Hammerite posted:Thanks for the suggestion. I ought to have mentioned that I am constrained to using MySQL. Looking on the internet, I see that ROWNUM is a feature that other RDBMSs have but that MySQL does not have. Is there a way of doing it that will work in MySQL? You will need to use a work table to store the results then. MySQL supports the LIMIT function to limit the number of rows. Pseudo Code code:
|
|
#
?
Feb 8, 2009 17:46
|
|
|
Xae posted:You will need to use a work table to store the results then. MySQL supports the LIMIT function to limit the number of rows. OK, thanks for telling me how to do it. It looks like that way of doing things would be quite computationally intensive. Since the actual task I have in mind is related to displaying information on a web page that anyone can access, I might consider automating the query to run once per day and each time store the results in the User table, or something like that.
|
|
#
?
Feb 8, 2009 18:21
|
|
|
Hammerite posted:Suppose that I have a table called User and a table called UserLogins. The table UserLogins has the columns UserID, LoginTime (together making the table's Primary Key), and EnteredNumber. EnteredNumber is an integer between 0 and 9 that the user is required to enter when he logs in. I haven't tried it but will something like this work: code:
|
|
#
?
Feb 8, 2009 19:04
|
|
|
deimos posted:
Hmmm, It kind of works, but it doesn't seem to take any input. The "nid" is a term ID and depends on the URL you are on. I'll keep diggin, thanks though! cannibustacap fucked around with this message at 00:49 on Feb 9, 2009 |
|
#
?
Feb 9, 2009 00:39
|
|
|
Not sure if this entirely proper to post here, but I've been searching for over 15 minutes now for Oracle Client 10.1.0.5 (not instant, I need the full admin package) but can't find it anywhere. Does anyone know how to find it? Edit: maybe it's only on metalink...crap, now I have to go through all of the red tape in my company to find out how to get access 
mister_gosh fucked around with this message at 02:23 on Feb 9, 2009 |
|
#
?
Feb 9, 2009 01:59
|
|

|
Here's a stupid newbie question from someone who's fiddling with MySQL for the first time. I've just set up a small database with a single table that contains the following columns: -Name -Day -'Working' - A single-character value (Y/N) on if that person is going to be working that day or not Four people are listed in this table so far, with their working / non-working days set up. The goal is to be able to ask the database for the next day that persons 1, 2, 3, and 4 will all have off at the same time, based on this data This query should also only check today's date, or days in the future. All days in the 'day' column are in the SQL "DATE" format (i.e. 2009-02-09). Unfortunately, I'm about stumped at how to do this. The closest query string I've worked out is: code:I feel like I'm missing something stupid with this for what should be such a simple thing, but after trawling the net for the last couple of hours with no productive result (aside from a headache from my attempts to toy around with the 'GROUP BY' and 'HAVING' arguments), I thought I'd ask to see where I'm aiming wrong.
|
|
#
?
Feb 9, 2009 11:58
|
|

|
Parias posted:Here's a stupid newbie question from someone who's fiddling with MySQL for the first time. I've just set up a small database with a single table that contains the following columns: Two solutions follow. code:code:
|
|
#
?
Feb 9, 2009 16:29
|
|

|
With MSSQL there is a PRINT commands that sends messages back to the client to print in the messages area. Is there a way I can replicate this with PostgreSQL (or Greenplum)? I could use Select 'message here' for a final message, but I would like to output the current time and location in a script at different places in the script while it's running.
|
|
#
?
Feb 9, 2009 21:27
|
|
|
I have a question about grouping, I can't seem to get this to work right even though it seems like it should. Basically my query currently pulls data that looks like this:code:code:code:code:edit: well crap I think the reason it's not working right is I'm changing it in my select but not in my group by :| edit2: Fixed breaking tables and yeah I didn't group right. I didn't think of using CTE's... maybe I'll use them and see if improves performance, thanks! pikes fucked around with this message at 18:30 on Feb 12, 2009 |
|
#
?
Feb 12, 2009 17:55
|
|
|
Please fix table breakage. You might want to use derived tables. Here's a hint: code:
|
|
#
?
Feb 12, 2009 18:18
|
|
|
I am in the process of cleaning up our website code and moving all the queries from the pages into stored procedures and I'm running into a performance issue for the query on our invoice lookup page. If I run a query like so:code:code:
|
|
#
?
Feb 12, 2009 23:08
|
|

|
golgo13sf posted:Stuff Theoretically, separate procs might be a cleaner solution, but I'd like to see the database design underneath this proc just to see why you need to query like this. The most flexible solution would probably be Dynamic SQL. It'll perform better than conditional where clauses. Just be sure to use sp_executesql to execute your query and not EXEC. I hate Dynamic SQL as much as any DBA, but sometimes you have to grin and bear it.
|
|
#
?
Feb 12, 2009 23:40
|
|

|
Could you explain in English what your query is trying to do? It's getting a bit meta and it's clouding the design/intention of your code.
|
|
#
?
Feb 12, 2009 23:50
|
|
|
Xer� posted:Theoretically, separate procs might be a cleaner solution, but I'd like to see the database design underneath this proc just to see why you need to query like this. Here is a screen shot of the invoice search area on our site 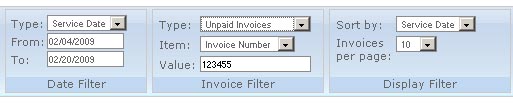 So there are several fields one could use to find an invoice, like say this pseudocode code:Here is the full stored procedure code (sanitized), sorry if it breaks tables code:
|
|
#
?
Feb 13, 2009 00:11
|
|
|
golgo13sf posted:I am in the process of cleaning up our website code and moving all the queries from the pages into stored procedures and I'm running into a performance issue for the query on our invoice lookup page. If I run a query like so: I would look at the query execution plans. I bet the second version isn't using a good index because it is not sargable in the query. Might see if you can use IF, something like this (untested): code:
|
|
#
?
Feb 13, 2009 00:23
|
|
|
camels posted:stuff... The query execution plan shows a clustered index seek on the [i] table of 42%, and 2 clustered index scans of 9% and 12%, which is what I'm sure is the killer. Looks like I'm going to have to go and make sure the indexes are all set up properly, and if that doesn't work, try rewriting with 'ifs' instead of 'case' statements. On that note, the jackass that did the majority of the work on creating this db went loving nuts setting up indexes, like the same column is defined multiple times on the index screen, the PK is indexed more than once, etc. Is that a performance hit, or is SQL smart enough to only index the column once even though it is defined multiple times? If anyone else has any solutions, I'm all ears.
|
|
#
?
Feb 13, 2009 01:22
|
|
|
golgo13sf posted:On that note, the jackass that did the majority of the work on creating this db went loving nuts setting up indexes, like the same column is defined multiple times on the index screen, the PK is indexed more than once, etc. Is that a performance hit, or is SQL smart enough to only index the column once even though it is defined multiple times? It will eat some space, including increasing the size of backups, and slow down UPDATEs as well as backup and restore operations. Even if all these are marginal, getting rid of the duplicate indexes can make it easier to write and tune queries.
|
|
#
?
Feb 13, 2009 01:39
|
|
|
Which engine are you using? Superfluous indices should only hurt write speed, never read. Also, I have this heavy, HEAVY bias AGAINST stored procedures that try to dynamically write SQL. Not done properly, it hinders the engine's ability to cache the query plans. Either offload all of the SP logic into regular programming space and execute them there, or study what ways your SP can be rewritten to take advantage of caching. Definitely make sure that your engine is caching right after you run the query, because if it isn't, that's the problem. The gulf between "what query I want" vs "what is actually run" shouldn't be that wide.
|
|
#
?
Feb 13, 2009 02:25
|
|
|
Triple Tech posted:I have this heavy, HEAVY bias AGAINST stored procedures that try to dynamically write SQL.
|
|
#
?
Feb 13, 2009 09:19
|
|
|
I feel like it is going to be difficult to ever get a good plan if you smoosh everything into one query because the filter types change what indexes are important, and that is something that will make parameter sniffing highly hit or miss. So maybe this is actually a good time for dynamic sql and sp_executesql.
|
|
#
?
Feb 13, 2009 13:56
|
|
|
There are going to be tradeoffs and it might just turn out that you don't care about the "slight" performance hit. Measure, measure, measure!
|
|
#
?
Feb 13, 2009 14:50
|
|
|
Victor posted:I haven't fully vetted this, but: http://www.sommarskog.se/dyn-search-2005.html This is very interesting and I think it is what I am going to end up doing, too bad we don't have SQL 2008, as it looks like it would be able to optimize my original query. edit: I rewrote the query using the method in the link, and it runs obscenely fast. Just-In-Timeberlake fucked around with this message at 18:21 on Feb 13, 2009 |
|
#
?
Feb 13, 2009 15:23
|
|
|

|
| # ? Jun 1, 2024 18:57 |
|
|
I have a little app which posts data to a database, and includes a smalldatetime timestamp marking when the application is run. For charting and historical trend purposes, I only care about the data collected by the last run in each day - if the app was run once at 10 AM and then again at 1 PM, I would like to remove the 10AM data from the table. I don't need anything too specific, just a general idea of how I would search through and remove those 10AM rows. My guess would be to chop the smalldatetime into pieces and compare each one, but I'm a sql noob, so I turn to you, the internet, for help.
|
|
#
?
Feb 14, 2009 16:09
|
|
