


|
Mr. Crow posted:Something I'm confused on, I understand you can use git-filter-branch (or I guess BFG is recommended too) to prune old files, but something I don't really get is how is it reflected in the history, after the fact? I've never used BFG, but with history editing in general it's as though those files had never been committed in the first place, no commits edited them, and commits that only edited them are removed entirely. E.g. if your history looked something like: 1234 Add binary file A and text file B 2345 Edit B 3456 Edit A 4567 Edit A and B and then you use filter-branch to retroactively delete A, your history now looks like: 1234' Add text file B 2345' Edit B 4567' Edit B Note that these are new commits with the same descriptions and same (modulo the removed files) contents as the old ones, just like any other history-rewriting operation like rebase. The old commits (and their files) still exist in the repo. Eventually, if not referred to otherwise (e.g. by tags), they'll expire and become subject to garbage collection; you can force this to happen earlier if saving space now is important, either by clearing the reflogs or just cloning the repo.
|
 #
?
Aug 12, 2014 23:24
#
?
Aug 12, 2014 23:24
|
|



|

|
| # ? May 11, 2024 12:22 |
|
|
I forked a repo on github, made some changes, and my pr was accepted. I don't think I need my fork anymore, I can't foresee needing to make any additional changes. Can I just delete my fork now?
|
|
#
?
Sep 16, 2014 02:16
|
|


|
Yes. You don't need a forked repo around if the code has already been merged into the mainline repo.
|
|
#
?
Sep 16, 2014 02:41
|
|
|
Marsol0 posted:Yes. You don't need a forked repo around if the code has already been merged into the mainline repo. I guess it doesn't really matter much that the pr now says: "rosstimson merged 2 commits into rosstimson:master from unknown repository about 7 hours ago" ?
|
|
#
?
Sep 16, 2014 04:12
|
|
|
fletcher posted:I guess it doesn't really matter much that the pr now says: "rosstimson merged 2 commits into rosstimson:master from unknown repository about 7 hours ago" ? The repo doesn't care. I guess github might, though. Seems silly to me.
|
|
#
?
Sep 16, 2014 04:39
|
|
|
Marsol0 posted:The repo doesn't care. I guess github might, though. Seems silly to me. GitHub doesn't really care either. But if you remove a fork then it can no longer be a remote, so changing it to "unknown repository" makes sense.
|
|
#
?
Sep 16, 2014 05:14
|
|

|
I've got a loving weird git problem I can't figure out. Something in HEAD right now is wrong, so I go to that file's history to see where the change was made...but the change isn't in the log. The last commit that git log sees for the file results in contents that don't match HEAD right now. Am I wildly misunderstanding something? Where the hell is the change? e: I think this was just my GUI getting confused about something, because I used a different one and found what I was looking for (I'm not good enough with command-line git to really dig into these weeds). raminasi fucked around with this message at 19:37 on Sep 25, 2014 |
|
#
?
Sep 25, 2014 19:28
|
|

|
I'm looking at the history of my master branch. I see one John has made a change to a script. I see Alice has done a merge. John's change to the script are gone after the merge. git log thescriptfilename does not show John's commit. I can only tell it happened using gitk. So the tree is like so:pre:* 40bd7b0 - Merge branch 'master' of github.com:MyProject (2 days ago) <Alice> |\ | * d829a37 -Fixed the script (3 days ago) <John> * | e4f98be - Did some work on something else (2 days ago) <Alice>
|
|
#
?
Oct 3, 2014 15:44
|
|
|
Dromio posted:I'm looking at the history of my master branch. I see one John has made a change to a script. I see Alice has done a merge. John's change to the script are gone after the merge. git log thescriptfilename does not show John's commit. I can only tell it happened using gitk. So the tree is like so: Probably she merged with git merge -s ours, which creates a merge commit but completely discards the changes from branch being merged in. It's generally used when you want to record a branch as "merged" for some reason (rather than just deleting it) but all of the changes in that branch are obsolete. 40bd7b0^ is probably e4f98be, so that diff having no changes is consistent with a -s ours merge. Do git diff d829a37..40bd7b0 to show the diff with respect to the other parent and you'll probably see it as a change that introduces Alice's changes and discards John's. You can also use git show 40bd7b0 to see the diff with respect to both parents at once, which takes a bit of getting used to but is great for figuring out what went wrong in a bad merge.
|
|
#
?
Oct 3, 2014 16:07
|
|
|
Say I have the following pretxncommit hook:Python code:pre:[hooks] pretxncommit = pretxncommit.py I've been wondering, what good is this pre-comment hook? The only way it will be used is if every time one of the dozens (or hundreds, say) of developers working at the company clones this repo, they dutifully add pretxncommit = pretxncommit.py to their hgrc file, which they may or may not do. How do I actually enforce author names? epswing fucked around with this message at 18:35 on Oct 8, 2014 |
|
#
?
Oct 8, 2014 18:32
|
|

|
epalm posted:Say I have the following pretxncommit hook: I haven't used hg, but the approach I've seen used with git is to install those hooks on the server side. People can do whatever the hell they want with their local repos, but when they try to push those changes, the changes being pushed have to pass those checks.
|
|
#
?
Oct 8, 2014 19:10
|
|
|
ToxicFrog posted:I haven't used hg, but the approach I've seen used with git is to install those hooks on the server side. People can do whatever the hell they want with their local repos, but when they try to push those changes, the changes being pushed have to pass those checks. The Mercurial equivalent is a prechangegroup hook on the destination (e.g server) repository.
|
|
#
?
Oct 8, 2014 20:17
|
|
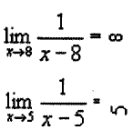
|
MrPablo posted:The Mercurial equivalent is a prechangegroup hook on the destination (e.g server) repository. Awesome! (What I actually needed was pretxnchangegroup)
|
|
#
?
Oct 8, 2014 21:46
|
|
|
epalm posted:Awesome! You might find pretxncommit is slightly easier (you don't have to iterate through the changesets). I wrote an incoming hook to implement that sweet GitHub feature where issues are closed or referenced when commits mention them for our local Jira instance. 
Scaevolus fucked around with this message at 07:21 on Oct 9, 2014 |
|
#
?
Oct 9, 2014 07:14
|
|

|
I'm trying to transition my team to git with a central server. We already have a few git repositories, but they've been mostly single-user repos which existed just to keep history (maintainers would usually just archive the directory, .git and all in order to distribute). In our project heirarchy some of the code is also just kind of bare in the file system, but the current hierarchy goes something like:code:How can I set up the submodules with a URI that anyone with access to the server can get to? eg I could have just set the submodule URI to my_user@server:/path, but then others couldn't access it when cloning. Do I need to make something like a 'git' user on the server so that everyone can access this? Or am I missing something else obvious here?
|
|
#
?
Oct 14, 2014 21:47
|
|


|
Take a look at the "repo" tool put out for git, it is designed to handle multiple top level repositories that are supposed to live together on some level. Also, is there a reason why you want multiple repositories? Would it make sense for all of your code to live in one repository? You could use filter branch to bring the history of other repositories into one repo.
|
|
#
?
Oct 14, 2014 21:51
|
|

SintaxError posted:But then when I attempt a remote clone, it fails, telling me the directory to the submodule doesn't exist. I'm guessing it's because I used the file path as the submodule location when creating it. Your hosted git repositories should be owned be a machine account as opposed to a specific user. Also when you remote clone your master repo make sure you do a "git submodule init"
|
|
|
#
?
Oct 14, 2014 22:04
|
|
|
Also, remember to use code:
|
|
#
?
Oct 14, 2014 22:20
|
|

 only
only
|
Ah that repo tool looks pretty neat. The main reason for keeping the repos separate was to keep the history. I'm fairly new to git myself, so I wasn't aware that importing the histories would be an option. Filter-branch looks rather cryptic, but if that's what I need, I may just hack through it to get a single repository.
|
|
#
?
Oct 14, 2014 22:48
|
|
|
SintaxError posted:Ah that repo tool looks pretty neat. The main reason for keeping the repos separate was to keep the history. I'm fairly new to git myself, so I wasn't aware that importing the histories would be an option. Filter-branch looks rather cryptic, but if that's what I need, I may just hack through it to get a single repository. Yeah, filter-branch is basically a way to bulk-modify history, so you can remove a file, move paths, etc for all commits. This means that if you have several repos on subdirectories, you can use filter-branch to move them from being in the top level from git's perspective to a subdirectory, then merge that repo into your "main" repo. Remember, git lets you have multiple remotes, so this is actually easy peasy from a logistical perspective! Like all things with git, it's esoteric, but totally awesome.
|
|
#
?
Oct 15, 2014 12:09
|
|
|
I'm working on a short hook script which notifies developers that a push just occurred ("Alice pushed 4 changesets to RepositoryName"). I'd like the notification to include the number of commits pushed, but I can't see an obvious way to do this with the changegroup hook. I was going to do something silly like Python code:Any suggestions? SO Question
|
|
#
?
Oct 23, 2014 16:45
|
|
|
epalm posted:I'm working on a short hook script which notifies developers that a push just occurred ("Alice pushed 4 changesets to RepositoryName"). I'd like the notification to include the number of commits pushed, but I can't see an obvious way to do this with the changegroup hook. Try using os.getenv('HG_NODE') and splicing that into the command with % rather than including $HG_NODE/%HG_NODE% directly in the command.
|
|
#
?
Oct 23, 2014 17:23
|
|
|
Is the easiest way to make a branch in TFS read only really just holding an exclusive check-out lock on it? Or jack with permissions?
|
|
#
?
Oct 29, 2014 22:03
|
|


|
No Safe Word posted:Is the easiest way to make a branch in TFS read only really just holding an exclusive check-out lock on it? Or jack with permissions? Changing the permissions for the branch is way easier than taking an exclusive lock.
|
|
#
?
Oct 29, 2014 22:07
|
|

|
Say there's some open source project 'assproject' and my company 'buttcorp' uses an modified version internally. Assproject has branches master, v1, v2, v3 etc. Right now our internal git has branch v1-buttcorp with all our changes. We want to move to v2 or v3 at some point. What's the best/simplest way of moving all our changes to a newer version? create a v2-buttcorp branch from v1-buttcorp and 'git rebase --onto v2-buttcorp v2'? Also, occasionally bugfixes are backported to the v1 and v2 branches by the assproject devs. Should we instead be doing our work on like master-buttcorp, and do something like 'git rebase --onto v2-buttcorp master-buttcorp'? Do I understand at all correctly how to use rebase? Illusive Fuck Man fucked around with this message at 00:04 on Nov 26, 2014 |
|
#
?
Nov 26, 2014 00:01
|
|
|
Illusive gently caress Man posted:Say there's some open source project 'assproject' and my company 'buttcorp' uses an modified version internally. Assproject has branches master, v1, v2, v3 etc. Right now our internal git has branch v1-buttcorp with all our changes. We want to move to v2 or v3 at some point. What's the best/simplest way of moving all our changes to a newer version? create a v2-buttcorp branch from v1-buttcorp and 'git rebase --onto v2-buttcorp v2'? If there's relatively little, making a v2-buttcorp branch on your v1-buttcorp and rebasing that onto v2 is the right way to go. But if there's too much stuff inbetween and the conflicts are killing you, it might be better to make a v2-buttcorp branch on your v1-buttcorp, rebase that 5 commits ahead, and keep rebasing it in incremental steps until you're on v2. Or maybe even start cherry-picking instead of rebasing. Illusive gently caress Man posted:Also, occasionally bugfixes are backported to the v1 and v2 branches by the assproject devs. Should we instead be doing our work on like master-buttcorp, and do something like 'git rebase --onto v2-buttcorp master-buttcorp'? Do I understand at all correctly how to use ebase?
|
|
#
?
Nov 26, 2014 05:46
|
|


|
Mithaldu posted:Depends on how much bullshit there is between v1 and v2. cool. I think rebasing shouldn't be too difficult, since most of our changes are just added files. Shouldn't be many conflicts. Also I just learned what cherry-pick does. Mithaldu posted:This question is vague and unclear. If they're putting patches onto their v1 and v2 branches and whatnot, the correct thing to do is to fetch their changes, and once you know where the new position of v1 is, rebase your v1-buttcorp onto their v1. wouldn't it be re-writing history if I keep rebasing v1-buttcorp onto assproject dev's v1 after v1-buttcorp has been pushed to our internal repo? Would that screw things up if I pushed that rebased v1-buttcorp to remote-buttcorp and someone else tried to fetch it? With the master-buttcorp thing, I'm trying to figure out a better practice/workflow than all of us at buttcorp working on vX-buttcorp to reduce future difficulties porting stuff to new versions. Illusive Fuck Man fucked around with this message at 06:47 on Nov 26, 2014 |
|
#
?
Nov 26, 2014 06:43
|
|
|
Illusive gently caress Man posted:wouldn't it be re-writing history if I keep rebasing v1-buttcorp onto assproject dev's v1 after v1-buttcorp has been pushed to our internal repo? Would that screw things up if I pushed that rebased v1-buttcorp to remote-buttcorp and someone else tried to fetch it? Illusive gently caress Man posted:With the master-buttcorp thing, I'm trying to figure out a better practice/workflow than all of us at buttcorp working on vX-buttcorp to reduce future difficulties porting stuff to new versions.
|
|
#
?
Nov 26, 2014 07:28
|
|
|
If it's at all possible/sensible the easiest thing is to contribute as much of your changes as possible to upstream. A pretty good chunk of the patches I've contributed to various third-party projects have been to spare me the headache of maintaining a fork, rather than any real desire to help the upstream project.
|
|
#
?
Nov 26, 2014 07:41
|
|

|
Yeah I can definitely see the benefits of that, but upstream has strict testing / continuous integration policies, and they won't be able to test our code at all because it relies on internal proprietary stuff. Plus I think my boss still wants to keep our project a secret.
|
|
#
?
Nov 26, 2014 17:19
|
|
|
Illusive gently caress Man posted:With the master-buttcorp thing, I'm trying to figure out a better practice/workflow than all of us at buttcorp working on vX-buttcorp to reduce future difficulties porting stuff to new versions.
If v2 isn't a big deal, branch v2-buttcorp off v1-buttcorp and merge v2 into it. Conversely, if there is a lot of refactoring that affects your code, you'll probably want to manually rebase or cherry-pick your changes. You may even have to manually make the changes and commit them as entirely a new thing. Anyways, once v2-buttcorp is published, only do merges from v2 until v3 comes out. The idea is that you're not rebasing changes except when pushing out a new branch. That way there's no force pushes and folks don't have to worry about rewritten history. It's really not worse than periodic rebasing since "git log --first-parent" only shows your changes and merge commits, but not all the upstream commits along the way--that's the intended purpose of --first-parent. And when you do, do a major rebase (from v1 to v2), it's probably the right time to reevaluate the set of changes against upstream and consider what actually needs to be maintained against it, and whether or not your old revision history on the new branch really matters. If it does matter, you may want to merge v2 into v2-buttcorp. If it doesn't you might rebase or cherry-pick. The downside to a master-buttcorp is that there's no opportunity to do a periodic rebase without a force push, if that's needed. You could also, depending how many folks are working on the code, have a "flag day" where old master-buttcorp gets archived with a tag (or branch if there's any intended future development) and a force-push to the new master-buttcorp happens and everyone updates accordingly. But keeping the vX-buttcorp branches gives you that for free.
|
|
#
?
Nov 26, 2014 20:55
|
|

|
There's no reason to do merges though if he just makes new copies of branches before rebasing them. (Seriously, gently caress merges.)
|
|
#
?
Nov 26, 2014 21:02
|
|
|
Mithaldu posted:There's no reason to do merges though if he just makes new copies of branches before rebasing them. (Seriously, gently caress merges.) Merges aren't bad. Pointless ones are, sure, but these aren't pointless.
|
|
#
?
Nov 26, 2014 21:27
|
|
|
ExcessBLarg! posted:He has to do merges to track any bugfixes to upstream. Or constantly force-push, which is worse. Mithaldu posted:... just makes new copies of branches before rebasing them ... To make it a bit more simple to understand: Upstream has master. Upstream makes a branch off master for v1.0. Buttcorp makes a branch off v1.0 and calls it v1.0-buttcorp. Upstream adds a bug-fix to v1.0, creating v1.1. Buttcorp makes a branch v1.1-buttcorp on v1.0-buttcorp and rebases that onto v1.1. Thus upstream's behavior is mirrored identically with the least amount of effort or confusing git graphs for buttcorp.
|
|
#
?
Nov 26, 2014 22:28
|
|
|
Say there's a git repository for project FART. Now say a coworker extracts a targz of a completely different project (TURD) into a subdirectory of that original repository and commits changes to it for months. Now I want to create a new/separate repository for TURD, and retain the commit history. Will this be annoying/difficult/possible?
|
|
#
?
Dec 3, 2014 01:50
|
|
|
Illusive gently caress Man posted:Say there's a git repository for project FART. Now say a coworker extracts a targz of a completely different project (TURD) into a subdirectory of that original repository and commits changes to it for months. Now I want to create a new/separate repository for TURD, and retain the commit history. Will this be annoying/difficult/possible? You will want to use git filter-branch. I recommend googling for things like "splitting off a Git repository" -- there will be a few articles that tell you how to do it.
|
|
#
?
Dec 3, 2014 01:57
|
|



|
Not only is it not difficult, it's one command: git filter-branch --subdirectory-filter path/to/TURD HEAD -- --all
|
|
#
?
Dec 3, 2014 05:41
|
|
|
Thanks. git is cool and I like it
|
|
#
?
Dec 3, 2014 05:53
|
|
|
Mithaldu posted:Thus upstream's behavior is mirrored identically with the least amount of effort or confusing git graphs for buttcorp. Upstream has master. Upstream makes a branch off master for v1, tags as v1.0. Buttcorp makes a branch off v1 and calls it v1-buttcorp. Upstream adds a bug-fix to v1, tags as v1.1. Buttcorp either has to:
ExcessBLarg! fucked around with this message at 21:12 on Dec 4, 2014 |
|
#
?
Dec 4, 2014 21:09
|
|
|

|
| # ? May 11, 2024 12:22 |
|
|
code:
|
|
#
?
Dec 19, 2014 21:06
|
|