

|
9-Volt Assault posted:I would try the Scientific/Math(s) Computing: numerical/statistical analysis tools and CASs thread over at Ask / Tell � Science, Academics and Languages. Aha, thanks
|
 #
?
Jan 13, 2017 19:24
#
?
Jan 13, 2017 19:24
|
|


|

|
| # ? May 13, 2024 22:30 |
|
|
MononcQc posted:Thanks. I saw a talk once that talked about transforming OOP minded RFCs to Actor-Model architecture. Are there any resources that you know of that can help with translating OOP designed code to more of an actor based approach? I find this part very hard.
|
|
#
?
Jan 15, 2017 20:05
|
|

|
MononcQc posted:Rather than making a very long post about this from scratch, I'll source a transcript of a talk I gave on 'The Zen of Erlang' that mentions what OTP can bring to system structure: http://ferd.ca/the-zen-of-erlang.html ...Huh. That's actually pretty loving cool. I've never really thought of programming that way. Web apps, where I've spent 99% of my dev time, don't usually match up to this kind of approach - at least, not the ones I've ever worked on. I feel kinda left out now. It seems like all the interesting software stuff is kept away in places where Rails monkeys like me don't really get the chance to work on them and learn from it. I want to get more involved in cool stuff like this, so I've been making moves towards branching out and  ing my way into one of these kinds of projects. Teams are moving towards more functional and alternative coding styles now, so I hope my skills end up in demand. ing my way into one of these kinds of projects. Teams are moving towards more functional and alternative coding styles now, so I hope my skills end up in demand.
|
|
#
?
Jan 15, 2017 21:52
|
|



|
Mr Shiny Pants posted:I saw a talk once that talked about transforming OOP minded RFCs to Actor-Model architecture. Are there any resources that you know of that can help with translating OOP designed code to more of an actor based approach? Do you have any specific RFC in mind?
|
|
#
?
Jan 15, 2017 22:14
|
|

|
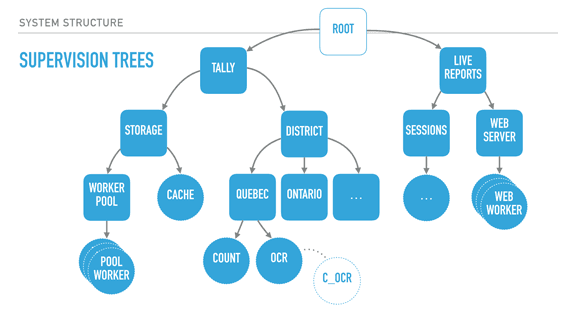
MononcQc posted:Do you have any specific RFC in mind? Of the top of my head, the guy was talking about how you would implement a webserver in Erlang and instead of one process that handles the connections and kicks of threads you would have a process for every connection coming into the server. Not in particular, no. I was just wondering about general guidelines. I saw your talk, supervision trees look really nice.
|
|
#
?
Jan 16, 2017 10:27
|
|
|
Mr Shiny Pants posted:Of the top of my head, the guy was talking about how you would implement a webserver in Erlang and instead of one process that handles the connections and kicks of threads you would have a process for every connection coming into the server. The thing with the actor model is that it can feel like a better Object Oriented environment than actual OO languages, but that's not a great way to structure systems. That way leads madness and frustration. The idea for Erlang is really to use processes to hold independent program units. That's the major difference with OO, where all pieces of data you have tend to materialize as objects. If you have a program that operates on a data structure (they pretty much all do!), you don't represent the data structure as a process. Instead you represent them as regular pieces of data that you operate on functionally with the functional subset of Erlang, in a good old sequential/declarative program. The level of concurrency and processes will come around when you take a given data flow or continuous piece of living state, and want to give it its own place to run. So yeah, for a webserver, there's two traditional designs depending on the server you use. In either case, a process is started that will listen on a socket. Then the split takes place: One one side (yaws, mochiweb), the server spawns a pool of processes that act as acceptors. Once a connection is accepted, the process itself becomes the connection: it will defer itself to custom code by the programmer based on a regular interface to handle requests and responses. A worker elsewhere receives a message asking to spawn a new acceptor, and the pool is maintained to a roughly stable size. There is a serialization point to spawn new acceptors On the other side (cowboy), the server spawns a pool of process that act as acceptors, but whenever a connection is accepted, they hand it over to a new process that will handle the request. The pool remains fixed in size, but if you want to implement a limit on the number of web workers, you require more complex coordination with the process pool, and more calls to shift control of sockets to processes (any process can send to a known socket, but only one may listen at a time, so they have a concept of ownership). In all cases, you end up using one process per connection. Pipelined or keepalive requests over a single connection can share the same local cache and state, though most servers don't make this explicit.
|
|
#
?
Jan 17, 2017 03:56
|
|
|
So the common idea of "HTTP is stateless and you must assume the connection and requests are too" still holds, but individual connections are considered their own processes? What advantage does this have over the previous one-process model? I can see the obvious picks of parallelization, but there's also concerns like database access that could limit the benefits from that...I'm not a web dev genius, just a monkey, so maybe I'm missing something. As a general system architecture, too, I can see how it'd be useful, but I still need some practice and experience to really grok it.
|
|
#
?
Jan 17, 2017 16:11
|
|
|
I hope this is the correct thread for this because I thought it was more of a general difficulty in understanding functions returning functions than a .NET thing or whatever.  Hello everyone I am knew to functional programming after spending amost all of my time in Java or C#. A friend I work with mentioned F# a while back and I've spent an occassional afternoon looking at it over the bpat few months but not really much time at all. Eventually I reached a tipping point of being interested after seeing enough elegant solutions for problems that ire unavoidably bloated in Java. I bought a book (Beginning F# 4.0 by Pickering and Eason) after reading through introductory things online. Currently theres a code snippet I can't fully understand and I think it comes down to not understanding what happens when a function returns another function. pre:let calculatePrefixFunction prefix =
let prefix' = Printf.sprintf"[%s]: " prefix
let prefixFunction appendee =
Printf.sprintf "%s%s" prefix' appendee
prefixFunction
let prefixer = calculatePrefixFunction "DEBUG"
printfn "%s" (prefixer "My message")This prints out [DEBUG]: My message My current understanding of this is that
What I don't understand is exactly what happens when prefixFunction is returned by calculatePrefixFunction. I don't think it's a function call because it's not given a parameter. However considering how it prints out when the program runs, prefixFunction must be run on the string "My Message". So after calculatePrefixFunction runs and prefixFunction is returned then it takes "My message" as the appendee parameter. I don't think this is correct though or if it is I don't really understand why it is. I'm just not able to divine the correct passage of information and method calls. e: actually I guess prefix' is just a string not function, still confused by the rest though 
EmmyOk fucked around with this message at 18:19 on Jan 17, 2017 |
|
#
?
Jan 17, 2017 17:50
|
|

|
Not exactly sure of the source of confusion - when you say "I don't think it's a function call because it's not given a parameter", what do you mean specifically? (calculatePrefixFunction "DEBUG") returns a function, which is stored in the variable prefixer. This function is then applied to "My message", returning the prefixed message. e: Maybe a translation into pseudo-C# could help? code:Asymmetrikon fucked around with this message at 18:36 on Jan 17, 2017 |
|
#
?
Jan 17, 2017 18:22
|
|

|
Your explanation makes a lot of sense actually! I guess the fact that an entire function can be returned and then stored is just completely alien to me as a concept. So when calculatePrefixFunction is called it returns prefixFunction and prefixer is a function defined by the returned function i.e. it's no different than an int that is initialised as the result of a function that returns an int?
|
|
#
?
Jan 17, 2017 18:43
|
|
|
Yeah, that's exactly right. Functional languages are big on tossing around functions as concrete things (usually described as them being first-class constructs like any other data.)
|
|
#
?
Jan 17, 2017 18:45
|
|
|
Pollyanna posted:So the common idea of "HTTP is stateless and you must assume the connection and requests are too" still holds, but individual connections are considered their own processes? What advantage does this have over the previous one-process model? I can see the obvious picks of parallelization, but there's also concerns like database access that could limit the benefits from that...I'm not a web dev genius, just a monkey, so maybe I'm missing something. As a general system architecture, too, I can see how it'd be useful, but I still need some practice and experience to really grok it. I'm under the impression that the database connection is actually an abstraction of a connection pool that works without programmer intervention. The process-per-connection allows a share-nothing approach that should, hopefully, make things just a little bit safer. FWIW, I think this is exactly how PHP-FPM works.
|
|
#
?
Jan 17, 2017 19:15
|
|

|
Asymmetrikon posted:Yeah, that's exactly right. Functional languages are big on tossing around functions as concrete things (usually described as them being first-class constructs like any other data.) Okay that's starting to make a lot of sense to me. Is prefixer just a reference to the original function or a copy? I'm wondering because it seems like prefix' is still available to prefixer which is a string originally from the first-order function.
|
|
#
?
Jan 17, 2017 19:34
|
|
|
I'm not super sure how F# handles it, but most functional languages (that I use, anyway) don't do references; they always copy.
|
|
#
?
Jan 17, 2017 19:45
|
|
|
EmmyOk posted:Okay that's starting to make a lot of sense to me. Is prefixer just a reference to the original function or a copy? I'm wondering because it seems like prefix' is still available to prefixer which is a string originally from the first-order function. It's best to think of it as a new function that was built during the calculatePrefixFunction method. Yes, prefix' is still available to the prefix function (this is commonly known as "closing" over a variable, see wikipedia). How it *actually* works is heavily dependent on your language implementation, but the semantics should be the same as if you just created a new function. It might also help to look at a similar example with numbers: code:code:
|
|
#
?
Jan 17, 2017 19:55
|
|

|
Thanks, Bognar and Asymmetrikon, these posts really helped a lot! The example using numbers are really clear and I'm much happier moving forward that I understand what's happening. Thanks again!
|
|
#
?
Jan 17, 2017 22:18
|
|
|
Pollyanna posted:So the common idea of "HTTP is stateless and you must assume the connection and requests are too" still holds, but individual connections are considered their own processes? What advantage does this have over the previous one-process model? I can see the obvious picks of parallelization, but there's also concerns like database access that could limit the benefits from that...I'm not a web dev genius, just a monkey, so maybe I'm missing something. As a general system architecture, too, I can see how it'd be useful, but I still need some practice and experience to really grok it. The process model for cgi and fcgi still makes sense, it's just that it's a ton cheaper to run in a VM like Erlang's. Database pools and access do represent a similar problem, except that now, the pool is usually a tweakable and configurable thing that lives within your VM along side the app. One of the benefits there is the ability to efficiently have bidirectional communication with the pool, on your own terms. That being said, the problems of contention, control flow, and back pressure don't change. They just take a different form, one that may be more explicit (I wrote on this at http://ferd.ca/handling-overload.html) Overall you can think of a large Erlang system of the way you could build a microservice architecture, but with all the apps living within one VM under a single memory space in a single runtime. There's huge benefits from having the proper isolation and architectural divide, but you don't have to pay the cost of the network overhead in most cases.
|
|
#
?
Jan 17, 2017 23:32
|
|
|
MononcQc posted:Overall you can think of a large Erlang system of the way you could build a microservice architecture, but with all the apps living within one VM under a single memory space in a single runtime. There's huge benefits from having the proper isolation and architectural divide, but you don't have to pay the cost of the network overhead in most cases. This also how I am imagining the system, so you could say the Erlang VM is kuburnetes? And a process is a docker instance?
|
|
#
?
Jan 18, 2017 09:31
|
|
|
xtal posted:What is the best language to use on a Raspberry Pi? Haskell runs fine but lens has been compiling for over a day Ralith posted:If you can live without being MAXIMUM FUNCTIONAL, rust's nice, and has a pretty good embedded story. Self-quoting for context. How much of a coding horror would it be for me to make a Lisp syntax for Rust using Haskell and parsec?
|
|
#
?
Jan 18, 2017 13:57
|
|
|
I can understand why you'd want to write your systems and applications as a process tree, but I haven't yet developed a sense of what use cases those would be. I guess I haven't had a need to work on uptime critical systems before, but it sure sounds interesting. I got pretty far into LYAH, so maybe LYSE is up next. Edit: I have to say, Elixir/Erlang, OTP and the BEAM are how I expected computer programs to work in the first place, so it's nice to see that I wasn't totally off. xtal posted:Self-quoting for context. How much of a coding horror would it be for me to make a Lisp syntax for Rust using Haskell and parsec? As long as it isn't a security critical thing, 
Pollyanna fucked around with this message at 15:46 on Jan 18, 2017 |
|
#
?
Jan 18, 2017 15:43
|
|
|
xtal posted:Self-quoting for context. How much of a coding horror would it be for me to make a Lisp syntax for Rust using Haskell and parsec? Well, I'm doing this for C (with intent to create a lot of macros to automatically do generics/monomorphisation/better types/etc.,) so I'd be a hypocrite if I didn't say go for it
|
|
#
?
Jan 18, 2017 15:56
|
|
|
Pollyanna posted:I can understand why you'd want to write your systems and applications as a process tree, but I haven't yet developed a sense of what use cases those would be. I guess I haven't had a need to work on uptime critical systems before, but it sure sounds interesting. I got pretty far into LYAH, so maybe LYSE is up next. What implications would that have for security? Do you mean it's just silly to make our own language?
|
|
#
?
Jan 18, 2017 16:08
|
|
|
xtal posted:What implications would that have for security? Do you mean it's just silly to make our own language? I mean that anything goes really. Ignore what I said about security, I don't know anything about it.
|
|
#
?
Jan 18, 2017 18:34
|
|
|
xtal posted:Self-quoting for context. How much of a coding horror would it be for me to make a Lisp syntax for Rust using Haskell and parsec? One of the fun things about the Rust compiler is that it's pretty well factored into a bunch of distinct libraries--you might actually be able to just drop in a new front-end rather than doing syntax-to-syntax transforms. You'd need to write a parser in Rust to do that, but s-expressions are pretty easy and nom may not be parsec but people seem to like it. This will probably be even less stable than something that emits rust syntax, since internal compiler APIs change whenever they like, but would IMO be a way more interesting project. Asymmetrikon posted:Well, I'm doing this for C (with intent to create a lot of macros to automatically do generics/monomorphisation/better types/etc.,) so I'd be a hypocrite if I didn't say go for it
|
|
#
?
Jan 18, 2017 18:39
|
|

|
Ralith posted:Not to be an evangelist or anything, but FYI Rust is basically what you get if you start with C and add all those things. Maybe have a look! Oh, I've written a fair amount of Rust, and I would totally use it for any actual serious low-level work I'd want to do. This is just for my own curiosity - I have some ideas about macros and reinterpretation of Sized types that I want to test out.
|
|
#
?
Jan 18, 2017 19:03
|
|
|
Mr Shiny Pants posted:This also how I am imagining the system, so you could say the Erlang VM is kuburnetes? And a process is a docker instance? Ehhh... analogies like that can help make things click, but you can't program by holding them like a mantra or to that degree of precision. Erlang was made open 19 years ago, and existed for 30+ years before. It has grown in isolation from these things for the most part, and mostly came before them (OO has had many incarnations, so don't hold me to too much precision there). The patterns it uses and allows are disconnected conceptually and come from different motivations. While it may help to compare broad properties to OO (encapsulation and message passing) and to microservices (isolation and separation of concerns), you can't really bring things much further than that, and sooner or later, it's easier to just abandon preconceptions and just dive in. The blog post / presentation I linked is as abstract I've managed to word things without losing too much, but nothing would beat getting some experience or looking at existing systems or libraries.
|
|
#
?
Jan 19, 2017 00:02
|
|
|
MononcQc posted:Snip Cool, I've watched some talks about Erlang and I think I got a good idea how it conceptually works. What do you think of Elixir? It seems to have really gained some traction over the last couple of years. Especially with Phoenix.
|
|
#
?
Jan 19, 2017 10:35
|
|
|
Mr Shiny Pants posted:Cool, I've watched some talks about Erlang and I think I got a good idea how it conceptually works. Elixir and Phoenix seem to be going together the way that Ruby and Rails ended up an indistinguishable thing for most of their respective communities. Elixir has a few niceties and capacities it adds on top of Erlang (protocols are the biggest one), but by all means both maintain very similar semantics overall. I think the divide that seems to happen now between both communities is that Elixir gets to be used for web and web-related stuff, whereas Erlang keeps seeing more usage at the infrastructure level. There's of course outliers in both directions, but I wouldn't be surprised if <10% of Elixir's usage was non-web stuff, and <5% of Erlang's usage was primarily web stuff (excluding bolting on HTTP APIs on an otherwise non-web service) While the Elixir community is also still not on solid ground when it comes to OTP -- that stuff takes a while to internalize as a group and I'm not too worried about it -- it still entirely applies and remains valid as a set of design rules, so I'm pretty happy about that.
|
|
#
?
Jan 19, 2017 14:04
|
|
|
I don't see Elixir lasting very long without OTP also becoming a valued asset. It's a functional Ruby otherwise and it would need more of an edge than that to survive long-term. It helps that OTP is relatively simple in concept, at least.
|
|
#
?
Jan 19, 2017 14:18
|
|
|
What *is* OTP anyway? A design pattern? A library? An API? The little research I did didn't clarify any of that (maybe I'm looking at the wrong docs or at the docs wrong) and the name sure as hell doesn't make it any clearer. It doesn't help that some people mention Erlang/OTP as if it's a variant of Erlang. Well, is it??? totally not baiting mononcqc :P
|
|
#
?
Jan 19, 2017 18:57
|
|

|
Shinku ABOOKEN posted:What *is* OTP anyway? Outlaw Techno Psychobitch.
|
|
#
?
Jan 19, 2017 19:22
|
|

|
Shinku ABOOKEN posted:What *is* OTP anyway? A design pattern? A library? An API? stdlib
|
|
#
?
Jan 19, 2017 19:34
|
|

|
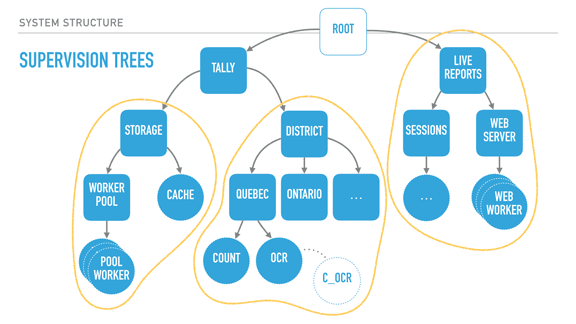
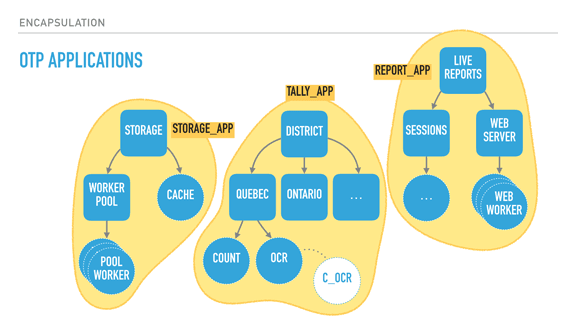
Shinku ABOOKEN posted:What *is* OTP anyway? A design pattern? A library? An API? OTP is basically the evolution of all the patterns that kept being rediscovered at Ericsson in their big products in the 90s, and then their continuous updating since then. They found out common design patterns (how to do request/response, how to encode state machines, how to fan-out events, how to handle failures through supervision, and so on), and then turned them into core libraries for generic/specific components. So for a stuff like a 'server' pattern, where a process holds a bit of canonical state and responds based on it to a bunch of randos sending it messages, they abstracted away the common core: sending/receiving messages, maintaining and storing state in memory, handling debug messages, tracing, suspending/resuming workflow, the usage of hooks for introspection, and so on. They did all of that into a core 'gen_server' module (called a 'behaviour'), and what you specify is how to handle messages of various types. They did this with the most common patterns, and wrapped it with the idea of supervision trees ('supervisor' is one of these behaviours). They took these supervision trees and put them into 'applications' (basically stateful libraries), and built a system of 'releases' around it that handle things like booting, restarting, shutting down, and doing live upgrades of these application and supervisor subtrees. To make a short story of it, Erlang is a very small language with processes, links, monitors, message passing, and the VM. OTP is the general development framework that specifies how you organize code, write libraries, distribute and boot them no matter the kind of industry you're in.
|
|
#
?
Jan 19, 2017 19:48
|
|
|
Shinku ABOOKEN posted:What *is* OTP anyway? A design pattern? A library? An API? it's the open telecom platform. how much clearer do you need? (it's basically just erlang's stdlib)
|
|
#
?
Jan 19, 2017 20:29
|
|



|
Ralith posted:Not to be an evangelist or anything, but FYI Rust is basically what you get if you start with C and add all those things. Maybe have a look! In the same sense that Sacr� Coeur is basically what you get if you start with a primitive hut and then tear it down and build a basilica there, yes. I like Rust, but it is much fairer to say that it is a safer and more principled C++ with a startlingly different syntax. It is a language for motivated experts which yields great rewards for sophisticated use.
|
|
#
?
Jan 19, 2017 20:30
|
|

|
Mr Shiny Pants posted:Cool, I've watched some talks about Erlang and I think I got a good idea how it conceptually works. i like elixir but i think phoenix is sucking up all the oxygen and phoenix is ultimately just a rails rewrite. i could be wrong, but i think the era where rails style applications were the 'right' way to build an application is gone and things like django, rails, express and phoenix are on the way out i also think they made some pretty bad choices early on that are going to hurt them longer term. they use key/value dictionaries pretty pervasively throughout the standard library (and even provide sugar for dicts that they call `structs`) when there were faster, safer, more idiomatic data structures available. they also have really fuzzy boundaries between compile time and run time that cause headaches
|
|
#
?
Jan 19, 2017 20:51
|
|
|
the talent deficit posted:i think the era where rails style applications were the 'right' way to build an application is gone and things like django, rails, express and phoenix are on the way out Out of curiosity, what do you see as the next big thing in web dev?
|
|
#
?
Jan 20, 2017 03:13
|
|

|
redleader posted:Out of curiosity, what do you see as the next big thing in web dev? i think it's only a matter of time before you see clients that effectively just make rpc calls to a backend service. whether this is negotiated via an sdk that uses graphql/rest or just uses something like gRPC or thrift over http2 i think application developers will stop having to care about the details of how their app talks to the server on the server side i think it's inevitable that apis reuseable by multiple clients will replace server generated html completely. for web browsers i expect turning javascript off will soon be unthinkable
|
|
#
?
Jan 20, 2017 06:09
|
|
|
That's pretty much the status quo, as someone who uses w3m and surf with JavaScript off. Someone should have seen this horror show coming.
|
|
#
?
Jan 20, 2017 15:33
|
|
|

|
| # ? May 13, 2024 22:30 |
|
|
the talent deficit posted:i think it's only a matter of time before you see clients that effectively just make rpc calls to a backend service. whether this is negotiated via an sdk that uses graphql/rest or just uses something like gRPC or thrift over http2 i think application developers will stop having to care about the details of how their app talks to the server Just to pick a nit, I don't think server-side rendering is going away anytime soon because people are paranoid about getting something to display ASAP and I don't think those people are going to trust networks to deliver their front-end code fast enough. Granted, this'll probably take the form of running a headless client against the API and shoving what it renders into a cache, so, yeah, agreed that stuff like Django and Rails are going away. xtal posted:That's pretty much the status quo, as someone who uses w3m and surf with JavaScript off. Someone should have seen this horror show coming. Yes, this world where there's a viable solution for a write-once-run-everywhere client UI that can be made to look like not-poo poo, is safely isolated from other programs and is Good Enough for most requirements is truly the stuff of nightmares.
|
|
#
?
Jan 20, 2017 17:21
|
|


