


|
D. Ebdrup posted:How does that work out against just sharing the files, on the machine that hosts the iSCSI initiator target, with samba? Originally it was because my backup software didn't like old school opensolaris. That and all my poo poo is domain joined, and getting opensolaris to play nice with it via samba was like slowly, lovingly cramming glass in your dick. All in all the solution works shockingly well. I get bitlocker'd storage pools, easy to manage permissions, and spend 95% of my computer janitor time dinking with stuff in windows vs. trying to remember how to set ACLs in solaris. It's also remarkably fire and forget. Last time I had to do anything to it was the last time there was a power outage, and that just consisted of making sure the boxes were turned back on in the correct order.
|
 #
?
Oct 29, 2019 11:44
#
?
Oct 29, 2019 11:44
|
|


|

|
| # ? May 11, 2024 21:26 |
|
|
Methylethylaldehyde posted:Originally it was because my backup software didn't like old school opensolaris. That and all my poo poo is domain joined, and getting opensolaris to play nice with it via samba was like slowly, lovingly cramming glass in your dick. 
|
|
#
?
Oct 29, 2019 12:28
|
|



|
Duck and Cover posted:This isn't really an example or one person doing something worse then others have done, more me getting sick of reading it yet again. I certainly could have ignored it I choose not to, in an attempt to maybe change future behavior of not just Atomizer, but others. Please backup your poo poo that you care about offsite so that when you have an issue you don't come in here screaming that we mislead you or something. Thanks. Methylethylaldehyde posted:getting opensolaris to play nice with it via samba was like slowly, lovingly cramming glass in your dick. This gave me nightmares on multiple levels but I also laughed at it so carry on you crazy bastard.
|
|
#
?
Oct 29, 2019 15:16
|
|

|
Crunchy Black posted:Please backup your poo poo that you care about offsite so that when you have an issue you don't come in here screaming that we mislead you or something. Thanks.
|
|
#
?
Oct 29, 2019 16:04
|
|
|
Crunchy Black posted:Please backup your poo poo that you care about offsite so that when you have an issue you don't come in here screaming that we mislead you or something. Thanks. Wait you're saying my onsite copies aren't immune to fire? gently caress I had no idea! Thanks you are so smart! Anyway went with 1 backup for a 5 hard drive system. Thanks for your ever so helpful post! This was only caused by me using the word backup instead of the proper term raid. Smart (at least relatively) folks realized what I was asking and responded. Dumb folks decided it was time to educate me! Even dumber folks ignored the posts where I made it loving clear I understood and kept going even though the thread moved on. D. Ebdrup posted:But his anims! If my anims get deleted my waifus die. (USER WAS PUT ON PROBATION FOR THIS POST)
|
|
#
?
Oct 29, 2019 19:17
|
|

|
Duck and Cover posted:If my anims get deleted my waifus die. I think the reason you got such push-back on using the word backup wrongly when you meant RAID is that all too many people do assume that RAID is backup, and we can't read your mind to know that you know that it isn't and that you just typo'd. And it's probably also because people in technical fields tend to be specific to avoid exactly such misunderstandings, because the English language even in its technical sub-fields can be incredibly easy to misunderstand.
|
|
#
?
Oct 29, 2019 19:36
|
|
|
My current file server is running Xubuntu 18.04 with MDADM and ext4, I know this probably not the smartest setup but it is what it is. This seems to be meeting my needs just fine but I feel like it could be better. Would ZFS actually improve my life much over MDADM and ext4? I believe I originally chose not to go with ZFS because the previous motherboard only had 4GB of RAM in the NAS which technically met the 1GB per TB recommendation but 4GB was still often less than the minimum RAM suggested. Would it have been just fine? Maybe, maybe not, I just knew it was a confusing mess with too many different opinions on how much RAM was necessary so I bailed on ZFS. Now I have 16GB of RAM and 4x 2TB drives, I think I could go up to 32GB of RAM if necessary, but I don't want to waste money. If anything, my only concern about going with FreeNAS now is I read talk about BSD's ZFS implementation is no longer the most actively developed and Z on Linux is the new hotness to a point where FreeBSD is now basing their ZFS on ZoL. Does FreeNAS still have the best ZFS file system implementation? If ZoL is better, is there any real downside to either staying with Ubuntu or should I switch to something like CentOS? I think the FreeNAS web GUI alone is probably why I want to change, but I still kinda like having a full Linux GUI on my file server since I already keep an old keyboard and monitor connected to it.
|
|
#
?
Oct 29, 2019 19:38
|
|
|
ZFS is worth it over md just for the file integrity alone. I've had mdraid poo poo arrays for a single error during a rebuild, whereas ZFS will flag corrupted files and move on. 1GB/TB is overkill and was probably based on how to make ZFS survive in the enterprise world despite its shortcomings. I'm well under that and my system still has ~20% RAM free at any given time.
|
|
#
?
Oct 29, 2019 19:45
|
|




|
IOwnCalculus posted:ZFS is worth it over md just for the file integrity alone. I've had mdraid poo poo arrays for a single error during a rebuild, whereas ZFS will flag corrupted files and move on. For home use? Streaming media loads don't even get loaded into ARC anyways!
|
|
#
?
Oct 29, 2019 19:49
|
|

|
D. Ebdrup posted:I'm only an old-school weeb so I don't know for sure, but I think at this point someone is supposed to say that your waifu is trash? Yeah, you have to remember where I work I hear people say this every day followed by "but I can't get that data back!" At our company we have fired people for saying RAID is a backup.
|
|
#
?
Oct 29, 2019 20:51
|
|

|
Oh yeah and when I was talking about raid I was talking about The Synology Hybrid Raid not that it mattered towards what I was asking.
|
|
#
?
Oct 29, 2019 21:29
|
|
|
Crotch Fruit posted:my only concern about going with FreeNAS now is I read talk about BSD's ZFS implementation is no longer the most actively developed Even ignoring all that, ZFS in FreeBSD is still scheduled to receive the full 5 years of support from whenever 13-STABLE is branched (unless the new OpenZFS code magically gets imported into HEAD before then, which I don't regard as likely), and that isn't going to happen for at least another year - so there will be at least 6 more years before any action need be taken. Also, it's worth reiterating that ZoL won't be be taking over in any sense but the most Linux-facistic way (and again, ZFS isn't part of the main-line kernel, so it's up to distributions to get everything properly implemented), rather it's being repurposed as the repository of record for the OpenZFS project and will at some point actually be the OpenZFS repository in name and everything. IOwnCalculus posted:1GB/TB is overkill and was probably based on how to make ZFS survive in the enterprise world despite its shortcomings. I'm well under that and my system still has ~20% RAM free at any given time. On the other end of the scale, I've run ZFS on as little as 512MB RAM (which is less than the official minimum requirement for FreeBSD) - so the only thing ZFS really cares about is that it's a 64bit platform, because otherwise it has to split a lot of the (atomic) operations which on a 32bit platform will be handled in more instructions, rendering them non-atomic and thus breaking one of the core tenants of ZFS - namely that you can always roll back a transaction group (preferably when the pool is in read-only mode) and send|receive your way to recovering your data. BlankSystemDaemon fucked around with this message at 22:57 on Oct 29, 2019 |
|
#
?
Oct 29, 2019 22:50
|
|
|
Just snagged a few of these for cheap. Probably the nicest direct attach enclosure I've had. Completely tool less disassembly with no bits to lose. Built in PSU. They make newer ones with USB3/C https://www.youtube.com/watch?v=WgqEv7lMH_M
|
|
#
?
Oct 29, 2019 23:23
|
|
|
D. Ebdrup posted:Even ignoring all that, ZFS in FreeBSD is still scheduled to receive the full 5 years of support from whenever 13-STABLE is branched (unless the new OpenZFS code magically gets imported into HEAD before then, which I don't regard as likely), and that isn't going to happen for at least another year - so there will be at least 6 more years before any action need be taken. Duck and Cover posted:Wait you're saying my onsite copies aren't immune to fire? gently caress I had no idea! Thanks you are so smart! Anyway went with 1 backup for a 5 hard drive system. Thanks for your ever so helpful post! Echoing D. Ebdrup, for someone whose posts in this thread are very focused on pedantry, you tend to not be very concise. Please do with your data as you wish but don't get mad when we tell you that what you're doing isn't scalable or a best practice.
|
|
#
?
Oct 30, 2019 00:28
|
|
|
Have you guys had SSDs die? What's expected lifespan for consumer SSDs? This guy kicked the bucket this week.
|
|
#
?
Oct 30, 2019 16:20
|
|

|
Twerk from Home posted:Have you guys had SSDs die? What's expected lifespan for consumer SSDs? This guy kicked the bucket this week. 2 petabytes of write against that amount of host writes suggests offset issues. Though I haven't looked deeply into it. Yes I have had thousands die but in datacenter workloads, though most as os drives not heavy hit ones. (The heavy hitters nuked out way faster.)
|
|
#
?
Oct 30, 2019 16:26
|
|

|
Yeah, you've got something wonky going on there to get that sort of write amplification. That said, for a consumer 240GB drive, TBW specs are usually in the 75-150 TBW range, with SanDisk trending to the lower end of that range. You're at 153TB host and, as said, over 2PB NAND written. So either way you are between "a bit more than specced" and "Jesus, man, wtf?" depending on how you look at it, and should frankly have expected to have it die quite a while ago. You're clearly using that drive for some business/enterprise workload: shell out a few extra bucks for a larger enterprise-level drive next time and it should last a good bit longer. A 512GB 970 Pro, for example, is warrantied to 600TBW, or probably 6x what that SanDisk was engineered to hit.
|
|
#
?
Oct 30, 2019 16:41
|
|
|
H110Hawk posted:2 petabytes of write against that amount of host writes suggests offset issues. Though I haven't looked deeply into it. Yes I have had thousands die but in datacenter workloads, though most as os drives not heavy hit ones. (The heavy hitters nuked out way faster.) Yeah, I was curious about that but don't know how to address it in the future. This disk had a couple of hyper-V VMs, including 1 Win10 and 2 or 3 Ubuntu. It was running a plex server, minecraft server, Uni-Fi wifi controller, qbittorent scratch area, couple low-traffic NodeJS and PHP websites, TICK stack for monitoring & dashboards. I have no idea which of those was writing enough to hit even 150TBW, because all of them were extremely low utilization. I had configs and database backups and didn't lose anything that I will miss, but it was still annoying. Edit: I didn't need Windows, so I've already got everything set up on Ubuntu 18.04. I'll monitor to see what's writing so much, assuming that it wasn't something related to Hyper-V / Windows that was writing so much. DrDork posted:You're clearly using that drive for some business/enterprise workload: shell out a few extra bucks for a larger enterprise-level drive next time and it should last a good bit longer. A 512GB 970 Pro, for example, is warrantied to 600TBW, or probably 6x what that SanDisk was engineered to hit. I replaced it with an 840 Evo out of my junk drawer and I am preparing to make the next drive failure even faster to recover from. 
Twerk from Home fucked around with this message at 17:21 on Oct 30, 2019 |
|
#
?
Oct 30, 2019 16:42
|
|
|
Twerk from Home posted:Yeah, I was curious about that but don't know how to address it in the future. This disk had a couple of hyper-V VMs, including 1 Win10 and 2 or 3 Ubuntu. It was running a plex server, minecraft server, Uni-Fi wifi controller, qbittorent scratch area, couple low-traffic NodeJS and PHP websites, TICK stack for monitoring & dashboards. What caused it is your host OS (Windows?) formatted the disk such that FS block boundaries were offset from the NAND ones. Two examples: 1. Host OS formats 512b blocks on a 4k NAND disk. Every "one" write is amplified by (4096 / 512) = 8.0x. 2. Host OS formats 4k blocks on a 4k NAND disk but starts at byte 1k. (Out of 240,000,000kb) It should have started at byte 4k. Now every write is written out to 2.0x as it crosses a NAND boundary. (The closer to 4k increments the lower this multiplier, but 1 bit changed will result in 8k written.) It sorta looks like you had the former. Ubuntu as a host OS should handle it a LOT better, but I would check this out right at the start and make sure everything maps through correctly. gparted has a little helper as I recall which can help you align things from the get go. Make sure your VM os disks are the correct block size as well and because you're using files they will self-align. Also for your butttorrents and plex storage consider a HDD. As the other poster said, go with a higher quality disk, and keep it under 100% utilization to help with wear leveling. If you were running it at 90+% utilization the whole time it's going to have a hard time shuffling data to keep wear down on "hotspots." I bet if you looked it up behind the curtain you've been remapping blocks for a year or more at this point and the drive finally ran out of spares. High wear disks keep huge reserves (think 20%) that your OS cannot see to remap dead blocks. You can read this out of your disk with a utility as I recall. It might be disk and os specific.
|
|
#
?
Oct 30, 2019 18:01
|
|
|
people laugh at me when I tell them to keep an eye on write amplification, because that's one case where the old saw about "consumers will never write enough to wear out a SSD" isn't true. 153TBW is still a lot but you can still hit that with, say, Shadowplay/Relive Instant Replay Capture functionality (where you're continuously running a tape loop of your game sessions at 50 Mbit/s) or that kind of thing. I've always recommended you put that on HDD if you're doing that. Running full all the time is another thing that can increase write amplification.
|
|
#
?
Oct 30, 2019 18:07
|
|

|
H110Hawk posted:What caused it is your host OS (Windows?) formatted the disk such that FS block boundaries were offset from the NAND ones. Two examples: Thanks, I appreciate this. Hyper-V was the host, with Windows and Ubuntus installed on it. I didn't think about VM OS disks block sizes at all, and there's a separate long-term storage system that's on hard drives. I just wanted to use the SSD as some fast scratch space. This drive should have been doing barely anything, so 150TBW does not add up with its extremely light usage. It's a mystery to me why it wrote so much. I also kept it under 80% full.
|
|
#
?
Oct 30, 2019 18:10
|
|
|
Is block alignment something that should most likely be good when using default settings in most built in OS partitioning tools? So when its incorrect then usually its user error by trying to goof around with advanced overrides right? I'm talking about modern tools not something partitioned 15 years ago in windowsXP.
|
|
#
?
Oct 30, 2019 18:21
|
|
|
Paul MaudDib posted:people laugh at me when I tell them to keep an eye on write amplification, because that's one case where the old saw about "consumers will never write enough to wear out a SSD" isn't true. Ehhhh. For a normal consumer doing normal consumer things, it's still super hard to kill a drive. Even Shadowplay at 50Mbps works out to ~4,500hrs to hit 100TBW, and a 512GB 970 Evo is specced at 300TBW with actual endurance several multiples higher than that. Write amplification can happen, but with Win7/8/10 you have to muck with stuff intentionally to cause those issues, at which point you should know better, anyhow. VMs and such are different issues, but also not something normal consumers ever poke at. The point, really, is that a normal consumer will not produce 100+ TB/y. Most would struggle to hit 10 TB/yr. Whatever this guy was doing to hit 150+TB is beyond the scope of "normal consumer behavior," though I'd be real interested to see what he can turn up as to the root cause of those writes, since nothing immediately jumps off the page at me.
|
|
#
?
Oct 30, 2019 18:22
|
|
|
Paul MaudDib posted:people laugh at me when I tell them to keep an eye on write amplification, because that's one case where the old saw about "consumers will never write enough to wear out a SSD" isn't true. Our friend here isn't a consumer, and I still laugh at you. Which tool is this by the way? I want to check my Win 7 disk.
|
|
#
?
Oct 30, 2019 18:24
|
|
|
H110Hawk posted:Which tool is this by the way? I want to check my Win 7 disk. Looks to be CrystalDiskInfo. So I purchased a server to use as a homelab, a DL380 G7 and didn't read about the horrors of trying to use an OS like Unraid or FreeNAS with the P410i controller. Spent about 4 or 5 hours fiddling with the controller and wondering why I couldn't break my disks to a JBOD or ZFS. Come to find out that unless you have a cache memory module or different HBA then you can only do RAID 1 or 0! What joy! Luckily there was a pretty common LSI controller for cheap and I am eagerly awaiting for that to come. I guess a workaround to getting it to work with Unraid is to just make every disk its own RAID 0 array and then throw it into your array in Unraid. Good luck ever using that disk in another system then.
|
|
#
?
Oct 30, 2019 18:39
|
|

|
cage-free egghead posted:Looks to be CrystalDiskInfo. ... this? https://crystalmark.info/en/software/crystaldiskinfo/ Does it also install animes on my computer? (I recognize the name from back in the day, but oh god the website. Is this the real one or the viruses and crytolocker one?)
|
|
#
?
Oct 30, 2019 18:43
|
|
|
I dug up my invoice for that dead drive: $68 from Amazon in the first half of 2015. Not a bad lifespan considering the price, and hopefully Ubuntu as host OS will reduce writes going forward. How would I have hosed up block sizing or alignment? I just installed Win10 with defaults, added hyper-v role later, and used defaults everywhere possible. This time around, I just installed Ubuntu 18.04 server with defaults.
|
|
#
?
Oct 30, 2019 19:02
|
|
|
H110Hawk posted:... this? https://crystalmark.info/en/software/crystaldiskinfo/ Does it also install animes on my computer? (I recognize the name from back in the day, but oh god the website. Is this the real one or the viruses and crytolocker one?) It looks like the real one to me. Grab the standard edition if you don't want the animes
|
|
#
?
Oct 30, 2019 19:06
|
|

|
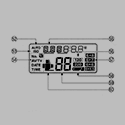
MagusDraco posted:It looks like the real one to me. Grab the standard edition if you don't want the animes Thanks. Looks like I don't get R/W/NAND info. Edit: and this is what I get for using the attachment feature. Sorry about that.
|
|
#
?
Oct 30, 2019 19:23
|
|
|
Ha, I had more than 36,000 power on hours and thirty-something power on count.
|
|
#
?
Oct 30, 2019 19:25
|
|
|
Yeah, given how cheap SATA SSDs are at 0.5TB and below, meh. My worst-case scenario drive right now in that regard is a Sandisk 480GB with ~8400 power-on hours. 105TB total writes, 143TB NAND writes, and this thing has spent a lot of time near full. Not all SSDs report GBW. My Kingston 96GB doesn't. edit: How the hell do you only have 420  hours on a Crucial M4? That thing is ancient. hours on a Crucial M4? That thing is ancient.edit 2: does that thing still have the firmware that has the power-on hour bug IOwnCalculus fucked around with this message at 20:30 on Oct 30, 2019 |
|
#
?
Oct 30, 2019 20:27
|
|
|
Ugh, after finally completing my hdd migration, I am kicking myself for seemingly easy choices i made long ago. WD easy store drives are taped up and running, but somehow I lost one during the server re-rack. Its already added as an LVM, i just need to extend it when i spin it back up. My 2 post 12U rack has less then perfect threaded mount holes. This makes the heavy-ish 2U server hard to rack on and off, and i have a shelf that helps it now, but should have gone with cage nut mounts instead. The case i have holding my little server has 3x HDD cages, but upon reading the amazon page more carefully, I see that it only holds 4xHDDs. meaning the middle cage has screw holes for 2 drives, but the other cages only have slots for 1, even though they are the same height . VERY annoying moving cages around to keep HDDs and power in check. Already planning the next upgrade in a couple years for a proper case, hot swap hdd bays and either enough sata ports or enough PCI space to add cards. My poor little i7 microatx mobo only has 4 ports and 2 dimm slots. Looking into a big server bump in whatever the 'cheap' chip is at the time, but grabbing a bunch of new drives to play with RaidZ2
|
|
#
?
Oct 30, 2019 21:04
|
|
|
Friends of mine had a SSD die on them over the weekend. It was only 128MB, I think they pretty much filled it up right away and it lasted about 9 months. Not 100% sure if it wore out but it came up blank after a bluescreen and when I tried to run recovery tools on it, the log was a solid wall of read errors.
|
|
#
?
Oct 30, 2019 21:13
|
|



|
H110Hawk posted:Thanks. Looks like I don't get R/W/NAND info. That 98% is your wear % for the nand on the SSD. It's most likely fine still. The M4 hides total writes or something. Hard to tell when most links talking about it go to crucial's old forums. edit: What I've got below is the most I can pull out of the wayback machine quote:I think I should correct the post above. After using M4 for much longer period of time I would say "AD Wear Leveling Count" value multiplied by drive capacity is quite equal to "Total NAND Writes". edit 2: your AD raw value is 3F in hex so 63 * 256 gigs so roughly 16 TB of writes but only like 2% of wear on the flash media? I dunno how accurate that is but the drive is rated for at least 72 TB writes. MagusDraco fucked around with this message at 21:19 on Oct 30, 2019 |
|
#
?
Oct 30, 2019 21:14
|
|
|
IOwnCalculus posted:edit: How the hell do you only have 420 Easy: It's wrong. I've been using this computer as a daily driver for work for well over a year now, not to mention the countless hours spent in Path of Exile prior to that, and all the overnight handbrake marathons before nvenc was added, but there was a time where the computer sat off for days to weeks on end. (Moved to the burbs, had a baby, no more time for path of exile but still worked in an office.) Once I saw the time I laughed and quickly took a screen shot.Firmware: No. It's upgraded past the 000x series buggy stuff. It's in fact running the latest (from 2013). MagusDraco posted:That 98% is your wear % for the nand on the SSD. It's most likely fine still. The M4 hides total writes or something. Hard to tell when most links talking about it go to crucial's old forums. edit: What I've got below is the most I can pull out of the wayback machine And smart values count down not up right?
|
|
#
?
Oct 30, 2019 21:29
|
|
|
H110Hawk posted:And smart values count down not up right? Depends. There's no actual standard for the implementation or interpretation of a lot of SMART values, so it's a bit of a poo poo show for stuff like that.
|
|
#
?
Oct 30, 2019 21:32
|
|
|
Why not use 2 data entries. 'value' and 'threshold'. Are they that cheap?
|
|
#
?
Oct 30, 2019 21:34
|
|
|
Shaocaholica posted:Why not use 2 data entries. 'value' and 'threshold'. Are they that cheap? It was a different time back then. It hasn't improved much. (newer versions are less dumb, but truly until ssd's most of the failure conditions were pretty binary. In a hdd a single remapped means that the disk is as good as dead. In a ssd it's Tuesday.)
|
|
#
?
Oct 30, 2019 21:37
|
|
|
H110Hawk posted:
hell if I know for that thing. Anyway I had to use the wayback machine to figure out your rough nand writes on the m4 Old Crucial forums and random other forums (xtremesystems) edit: fixed first link
|
|
#
?
Oct 30, 2019 21:42
|
|
|

|
| # ? May 11, 2024 21:26 |
|
|
H110Hawk posted:Firmware: No. It's upgraded past the 000x series buggy stuff. It's in fact running the latest (from 2013). Maybe that was how they "fixed" it, by forcing it to wrap back to zero hours. I wonder if I still have my 64GB M4 kicking around somewhere.
|
|
#
?
Oct 30, 2019 21:49
|
|