


|
https://www.phoronix.com/news/Intel-AVX10 intels resolution for AVX512 being too big for E-cores is to introduce yet another new instruction set which is basically AVX512 again, except this time 512bit registers are optional
|
 #
?
Jul 24, 2023 23:21
#
?
Jul 24, 2023 23:21
|
|


|

|
| # ? May 30, 2024 11:20 |
|
|
repiv posted:https://www.phoronix.com/news/Intel-AVX10 This is what they should have done in the first place. AVX-512's most interesting and useful parts are the new instructions, not the 512-bit wide registers. It's 7 years late, but better late than never. It's going to take many years at this point before there's an install base worth targeting this for, and the situation is even worse now that Intel market share is plummeting and AMD does have AVX-512 support on their small (Zen 4c) cores.
|
|
#
?
Jul 24, 2023 23:30
|
|

|
https://www.phoronix.com/news/Intel-APX they're also iterating on the core scalar instructions for the first time in a while, notably doubling the number of general purpose registers software will need to be recompiled to see any benefit though
|
|
#
?
Jul 25, 2023 00:27
|
|
|
turning big dials that say "number of scalar registers" and "vector register width" and looking back at the silicon teams for approval like a contestant on the price is right
|
|
#
?
Jul 25, 2023 00:45
|
|
|
Twerk from Home posted:This is what they should have done in the first place. AVX-512's most interesting and useful parts are the new instructions, not the 512-bit wide registers. It's 7 years late, but better late than never. Yeah they missed the mark by not using variable width vector instructions like ARM has instead of AVX-512. Guess I'll check back in around 2030 to see if this gets any adoption.
|
|
#
?
Jul 25, 2023 08:56
|
|

|
variable width vectors are a cool idea in principle but they seem annoying to use in practice if you're doing anything more involved than looping over big SoA buffers (e.g. AoSoA) googles highway is the only SIMD wrapper library i've seen which attempts to cover SVE and the hoops they have to jump through to handle unsized vectors are pretty horrific
|
|
#
?
Jul 25, 2023 12:22
|
|
|
SwissArmyDruid posted:a combination oculink and thunderbolt egpu dock hit the market, and after benchmarks, it's not even funny how much bandwidth thunderbolt overhead consumes, which makes one wonder, why consumers even let it get to market dominance in the first place. The appeal of thunderbolt is that a single small cable can link your laptop up to a dock providing 100W power, a high res external display, ethernet, USB, sound out, etc, and it will all perform well. Oculink is just a PCIe link. No USB-C power delivery, no tunneling of displayport or USB, just one multi-lane PCIe link. There isn't a mass market for no performance compromises eGPU, so that's pretty much why Oculink is only a niche thing and Thunderbolt is everywhere. priznat posted:I had always assumed that thunderbolt just passed the pcie lanes through but I guess there is more to it than that. TB is a packet protocol designed to encapsulate other protocols. As far as I know the PCIe layer they chose to encapsulate is transaction - they're wrapping TLPs inside thunderbolt packets. Similar stuff applies to other things which can be tunneled through thunderbolt like USB and DP.
|
|
#
?
Jul 31, 2023 08:08
|
|


|
 https://archive.org/details/maximum-pc-the-nearly-complete-collection/Maximum%20PC/2001/038%20Maximum%20PC%2011-1-2001/page/n29/mode/2up
|
|
#
?
Aug 1, 2023 10:08
|
|

|
Pretty much why Crysis runs like dogshit over a decade later.
|
|
#
?
Aug 1, 2023 10:09
|
|

|
Rinkles posted:
I'm honestly surprised we're seeing +5GHz nowadays. Zedsdeadbaby posted:Pretty much why Crysis runs like dogshit over a decade later. This is further complicated by how nobody has yet find a way to offload anything but some background calculations, netcode, and a few other things onto multiple threads. BlankSystemDaemon fucked around with this message at 10:42 on Aug 1, 2023 |
|
#
?
Aug 1, 2023 10:40
|
|



|
I remember when I was an undergraduate electrical engineering student, the fastest transistor in the world was 500GHz*. That was almost 20 years ago. *It was Indium Galium Arsenide
|
|
#
?
Aug 1, 2023 21:56
|
|



|
Rinkles posted:
I was trying to remember how far away it got using XOC methods and found that as of 6 months ago the single core frequency record is held by an Intel again: 9008MHz on a 13900k using Liquid Helium. https://youtu.be/RSUlvaE6N1U?si=ifIYpYnM55lc_-85 It�s still funny that for 10 years nothing came close to piledriver of all things. It looks like the netburst record on hwbot is 8362MHz
|
|
#
?
Aug 1, 2023 22:45
|
|

|
????? net burst double pumps though, which clock is that talking about
|
|
#
?
Aug 1, 2023 23:29
|
|

|
JawnV6 posted:????? https://hwbot.org/submission/2440102_wytiwx_cpu_frequency_celeron_d_352_8543.71_mhz 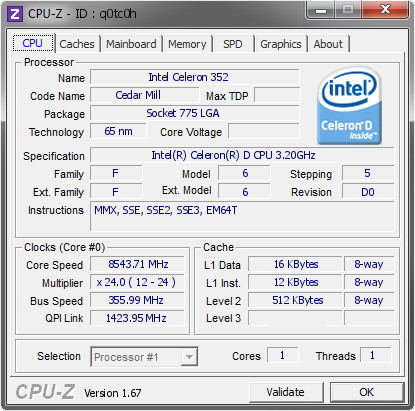 It�s really funny to me that the rankings for single core frequency on LN2 (or loving Helium now I guess) now go Raptor Lake, Piledriver, Cedarmill but hitting an absurd number at -250C for 5 minutes isn�t a design goal.
|
|
#
?
Aug 2, 2023 01:55
|
|
|
repiv posted:turning big dials that say "number of scalar registers" and "vector register width" and looking back at the silicon teams for approval like a contestant on the price is right well, getting away from that is what keller did with the royal core series. "rentable units" are supposedly the replacement for hyperthreading in the royal core series, starting with arrow lake. it's not quite clear what "rentable unit" means, but presumably some kind of execution resource that can be allocated to a thread, or a shared unit between multiple threads that is shared in a module (like FPUs in CMT)? But either way they are thinking about managing that balance of registers/visibility complexity/etc bloating area per core etc. Someone recently asked me where the term "scoreboarding" comes from, and the answer is the CDC 6600. Which uses barrel processing as well, where threads get scheduled onto shared physical cores as they're ready to execute. And the Peripheral Processor concept is an interesting one too. The idea is you have 12 big processors you can do an async launch onto and they'll go load some file from disk or do some processing subtask etc. And that's not too dissimilar from the idea of modern async promise/await coding. So the central vector processor can just blast along doing its thing and let the Peripheral Processors worry about the administrivia. Maybe rentable units are something like the idea of thread-level barrel processing. Like you have a bank of thread contexts for a 4c or 8c cluster, and the cores themselves just grab a thread in the ready-to-run state, run it, and put it back into the bank when it needs to wait. How do you really describe the core count in that situation? If it's 8 p-cores and only one thread is executing at a time per core... it's an 8/8 processor. But there are a lot of other ones in a close-to-running state. GPUs do the same thing with warp scheduling to cover for the latency of memory access... if a thread wants to go out to memory, sleep it until it comes back and process some other thread in the meantime. (And that's an interesting development in light of the Thread Director - it totally seems like overkill for big/little but maybe it makes sense to have this facility that knows about process state and scheduling and priority, living on the die.) In general I still def feel that at least SMT2 is worth it, let some other thread have a crack at any spare execution resources. Even if you are barrel-processing it's still units that are getting filled that weren't before. But I think it's really an increasing nightmare for speculative correctness etc. If a core has to track two threads at once, it has to track two sets of state and speculative visibility etc. And the overhead of that may be more than it appears at first crack, on top of just being more complex to do correctly. On top of that if it produces even a marginal reduction in area/complexity that can be plowed back into having more of them. But you've taken a crack at execution unit waste - if it's stalled, move it back to the bank, or move it to a slower core, or whatever. So hopefully that would translate into better occupancy on the units such that there's less waste for SMT to exploit. the other weird one is IBM's thing where there is no L3 but you have superfast L2s that can be read by any other socket in the machine at essentially line speed, and they build a tagged cache thing where evictions from one machine are pushed into the others, so everyone lives in one space and you have private caches built on top of a shared virtual cache infra Paul MaudDib fucked around with this message at 05:34 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 05:22
|
|

|
Intel is restoring pay and benefits and apparently the junior level engineers are getting $250-$500 in RSUs. That�s a lol Senior engineers are getting lost wages back in the form of RSUs too?
|
|
#
?
Aug 2, 2023 16:58
|
|

|
WhyteRyce posted:Intel is restoring pay and benefits and apparently the junior level engineers are getting $250-$500 in RSUs. That�s a lol Lol I�m on sabbatical right now and� what?!? That�s gotta be a fuckin joke. I really don�t want to open my laptop and read about a colossal shortcoming in restore & reward. E: you made me look into this. The $250-500 is only for people who weren�t eligible for the pay cuts. But they are dressing up a batch of RSUs as the �reward� portion even though it�s really just part of the �restore.� The cool part is they don�t even vest for another 15 months, so gently caress you if you leave Intel before then; you just gave the company money for nothing. lovely. Henrik Zetterberg fucked around with this message at 18:45 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 17:29
|
|

|
Paul MaudDib posted:well, getting away from that is what keller did with the royal core series. "rentable units" are supposedly the replacement for hyperthreading in the royal core series, starting with arrow lake. it's not quite clear what "rentable unit" means, but presumably some kind of execution resource that can be allocated to a thread, or a shared unit between multiple threads that is shared in a module (like FPUs in CMT)? But either way they are thinking about managing that balance of registers/visibility complexity/etc bloating area per core etc. This is all really interesting, thank you. Can you link to some resources so I can read more about this?
|
|
#
?
Aug 2, 2023 18:48
|
|

|
Henrik Zetterberg posted:Lol I�m on sabbatical right now and� what?!? That�s gotta be a fuckin joke. I really don�t want to open my laptop and read about a colossal shortcoming in restore & reward. Yeah I meant the 6s and lower who didn�t get paycuts but also haven�t gotten a compensation bump. Can�t imagine a talented junior engineer sticking around if given $250-500 as yearly retention carrot quote:But they are dressing up a batch of RSUs as the �reward� portion even though it�s really just part of the �restore.� The cool part is they don�t even vest for another 15 months, so gently caress you if you leave Intel before then; you just gave the company money for nothing. lovely. You can also look at it as an interest free loan to Intel from the employees in the best case WhyteRyce fucked around with this message at 21:18 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 21:13
|
|
|
WhyteRyce posted:You can also look at it as an interest free loan to Intel from the employees in the best case I really, really want someone on an investor call to ask this question framed in the same way.
|
|
#
?
Aug 2, 2023 21:35
|
|

|
canyoneer posted:I really, really want someone on an investor call to ask this question framed in the same way. So that you can hear the roar applause from the investors?
|
|
#
?
Aug 2, 2023 21:45
|
|



|
I once had to give a quarterly bonus to a report that was $172. It was extremely embarrassing. It would have been better if instead they just treated everyone to a nice dinner or something. It wasn�t intel but was another microchip type company (ie Microchip)
|
|
#
?
Aug 2, 2023 21:46
|
|

|
WhyteRyce posted:Yeah I meant the 6s and lower who didn�t get paycuts but also haven�t gotten a compensation bump. Can�t imagine a talented junior engineer sticking around if given $250-500 as yearly retention carrot If you were a 5 and under you didn't even get RSUs as the "raise" this year, you got a ~$5k cash award that vests over 3 years (or something like that). Lol at the idea of trying to retain newbie engineers with that kind of package. Just submitting a wifi reimbursement every month will net more than that entire RSU.
|
|
#
?
Aug 2, 2023 22:47
|
|


|
priznat posted:I once had to give a quarterly bonus to a report that was $172. It was extremely embarrassing. It would have been better if instead they just treated everyone to a nice dinner or something. A friend managed to get the QPB+ award (a 50% boost IIRC compared to regular Quarterly bonus), just as the bonuses went to poo poo. Lol at the extra 0.2 days of pay for exemplar work.
|
|
#
?
Aug 2, 2023 23:14
|
|


|
Bonuses are never proportional to the extra hours required to earn them.
|
|
#
?
Aug 2, 2023 23:44
|
|
|
I think I put it somewhere in this thread, but i want to say my last quarterly bonus was like $20.
|
|
#
?
Aug 2, 2023 23:53
|
|
|
Henrik Zetterberg posted:I think I put it somewhere in this thread, but i want to say my last quarterly bonus was like $20. Wow. That has less value than a year-long membership to the "Jelly of The Month" club.
|
|
#
?
Aug 3, 2023 00:07
|
|
|
ConanTheLibrarian posted:Bonuses are never proportional to the extra hours required to earn them. You have to go to the dark side sales for that
|
|
#
?
Aug 3, 2023 00:54
|
|
|
Plus the larger the bonus, the worse the human being.
|
|
#
?
Aug 3, 2023 02:02
|
|



|
are quarterly bonuses really a normal thing in that industry? don�t think i�ve heard of that anywhere else why not roll it into the annual (if your industry does those either)? quarterly seems like a lot of work
|
|
#
?
Aug 3, 2023 02:06
|
|


|
Cygni posted:are quarterly bonuses really a normal thing in that industry? don�t think i�ve heard of that anywhere else And 500 four times a year is still embarrassing, like what are you doing Intel
|
|
#
?
Aug 3, 2023 02:08
|
|

|
wait until you find out about most jobs lol. no idea if that�s competitive in that industry tho
|
|
#
?
Aug 3, 2023 02:13
|
|
|
My co does 2x a year but previous was quarterly and it lined up with the earnings so if they weren�t great tough nuts.
|
|
#
?
Aug 3, 2023 02:13
|
|
|
Intel used to not do it quarterly but corporate figured out that they can sell giving you your money quicker/more frequently vs. not making your bonus suck in the first place BK pitched it as just giving you your money faster
|
|
#
?
Aug 3, 2023 02:16
|
|
|
Cygni posted:wait until you find out about most jobs lol. no idea if that’s competitive in that industry tho It's not, which is why Intel's corporate strategy has always been to hire a thousand fresh college grads and lose most of them to Broadcom, Samsung, or other after a few years.
|
|
#
?
Aug 3, 2023 02:17
|
|
|
Just from the outside looking in, the internal bureaucracy at Intel must be pretty insane. We have access to the Intel PDK site and the hoops we have to go to get things we should be able to access unlocked is nuts. For the granite rapids cscripts the applications engineer swore to us that we should have access, and we kept saying no we don�t, and finally he came back and sheepishly said another internal group�s permissions were overriding his so yeah, that�s why we were locked out. Should be open now though! It was not, so he has to go back and figure out if there is another lock on it preventing it, lol. It has been literally months of asking at this point.
|
|
#
?
Aug 3, 2023 02:24
|
|
|
Twerk from Home posted:It's not, which is why Intel's corporate strategy has always been to hire a thousand fresh college grads and lose most of them to Broadcom, Samsung, or other after a few years. If you're looking for a chuckle or want to put a smile on the face of an ex-Intel engineer who moved elsewhere, ask them how hard was it to walk away from their unvested Intel RSUs. Or what their old group's counter offer to stay was (if offered). Also I once had to explain the whole grade 3/5/6/7 progression thing to a boss who has been in the tech industry for over 20 years but never interacted with Intel and he thought it was a stupid treadmill to jerk around junior engineers. priznat posted:For the granite rapids cscripts the applications engineer swore to us that we should have access, and we kept saying no we don�t, and finally he came back and sheepishly said another internal group�s permissions were overriding his so yeah, that�s why we were locked out. Should be open now though! I want to murder whoever wrote those cscripts WhyteRyce fucked around with this message at 02:57 on Aug 3, 2023 |
|
#
?
Aug 3, 2023 02:54
|
|
|
mmkay posted:A friend managed to get the QPB+ award (a 50% boost IIRC compared to regular Quarterly bonus), just as the bonuses went to poo poo. Lol at the extra 0.2 days of pay for exemplar work. I got one in q3 and yeah it was like 170 dollars or something.
|
|
#
?
Aug 3, 2023 02:58
|
|

|
WhyteRyce posted:I want to murder whoever wrote those cscripts  I enjoy how they are forever locked to python 3.8 and ONLY 3.8. Also I am going to attempt to build the hwapi driver for Fedora so I can run them inband (would make automating easier!), pray for me.
|
|
#
?
Aug 3, 2023 03:05
|
|
|

|
| # ? May 30, 2024 11:20 |
|
|
wet_goods posted:I got one in q3 and yeah it was like 170 dollars or something. 
|
|
#
?
Aug 3, 2023 10:01
|
|
