


|
Vanadium posted:I'm actively startled that I can't find a variation of int foo(unsigned *x, unsigned y) { if (*x <= UINT_MAX - y) { *x += y; return 1; } else { return 0; } } that doesn't compile to something with cmp in it. code:
|
 #
?
Nov 5, 2015 00:22
#
?
Nov 5, 2015 00:22
|
|


|

|
| # ? Jun 1, 2024 12:34 |
|
|
Continuing my adventures with a rather popular shipping service, I've gotten this error: Value '20' does not match regular expression facet '[0-9]*(.)[0-9]{2}' (the reference defines the given field as float). Um... so... it's checking the format of given thing by regexp. Without escaping the dot. Probably it's true for every float value that is being used (I've not bothered to check because the service is already... precious to use) Of course, I wondered what will happen if I pass 5a55 as a value - the XML succesfully passed the validation, but the server returned a 124 as a response, so I triggered some kind of internal error 
|
|
#
?
Nov 6, 2015 18:47
|
|

|
That's so loving weird. This isn't the first time I've seen that, but I when I saw I thought it was just the stupid government agency. Does XML validation only has integer validation for numbers?
|
|
#
?
Nov 6, 2015 19:16
|
|

|
What does it do with 5e55?
|
|
#
?
Nov 6, 2015 19:20
|
|


|
HardDisk posted:That's so loving weird. This isn't the first time I've seen that, but I when I saw I thought it was just the stupid government agency. We think it's SAX (as the order of fields in XML matters), so indeed you might have seen it somewhere - as far as I recall it only does float(?) validation and int validation, however, you can pass float values in int (according to reference) fields and nothing happens. You can also pass ints to floats and nothing happens. This one is the first field that requires float float. On the other hand reference defines certain order of fields and server returns errors when that order is kept - fortunately it also returns the proper order of fields. Yes, the reference is up-to-date. The entire thing is just  Karate Bastard posted:What does it do with 5e55? Haven't tried it - will see what it does with that one and the 0x05 on monday. Probably it's eval'ing the value or whatever is the equivalent in java and saving the value into the database, so I should be able to cause an integer overflow with 5e55, will see.
|
|
#
?
Nov 6, 2015 19:40
|
|
|
canis minor posted:The entire thing is just Working with XML in a nutshell.
|
|
#
?
Nov 6, 2015 23:48
|
|
|
XML is fine. Proper schemas come with predefined data types for validating any kind of number you like.
|
|
#
?
Nov 7, 2015 03:36
|
|
|
XML is terrible if you treat it as "text with funny angle brackets". If you treat it as structed data that just happens to be human-readable, you'll be fine.
|
|
#
?
Nov 7, 2015 15:06
|
|
|
Also helps to be extremely generous with your definition of "human readable", and to remember that nobody ever says "human writable".
|
|
#
?
Nov 7, 2015 15:50
|
|


|
Facebook�s code quality problem
|
|
#
?
Nov 7, 2015 16:28
|
|



|
The rise and fall of xml was amusing to watch. It kind of popped onto the scene one day as the perfect way to make data portable, everyone started using it even in situations where it made no sense, and then this big wave of "loving poo poo xml blows stop using it" hit the internet and people have been trying to kill it off ever since.
|
|
#
?
Nov 7, 2015 16:57
|
|

|
Greatest gift javascript ever gave was json as an xml alternative.
|
|
#
?
Nov 7, 2015 17:14
|
|

|
I don't particularly care about syntax. XML at least has schemas, where you can sort of verify that things are mostly in the correct place. The problem is that it's near impossible to query -- XPath might be one of the worst syntaxes I've seen. JSON doesn't have any standard query language, though the a subset of the one jq invented seems to be pretty popular. XML schemas do indeed have definitions for standard types like numbers and booleans, but I've never, ever, ever seen anybody appropriately use them.
|
|
#
?
Nov 7, 2015 18:23
|
|

|
Pavlov posted:Greatest gift javascript ever gave was json as an xml alternative. That's kind of like leaving a bag of flaming poop on the doorstep and considering it a gift. JSON is awful and the fact that it's used as data transport but can't be validated with built in tools (unlike XML schema) is awful and introduces so much development time and error. It makes me mad thinking about how badly XML was abused and then tossed away when it's the perfect format for data transport.
|
|
#
?
Nov 7, 2015 18:58
|
|


|
I think I hate you.
|
|
#
?
Nov 7, 2015 19:06
|
|
|
oh, and I forgot how we couldn't agree on a schema format for XML, so we now have six of them. ddml, dsd, dtd, xsd, relax-ng, schematron probably more
|
|
#
?
Nov 7, 2015 19:22
|
|
|
Pretty much the only downside to XML is the verbosity in terms of characters used. JSON is appealing because it's concise and you can transfer a lot of info without moving a lot of data.
|
|
#
?
Nov 7, 2015 20:10
|
|
|
And the fact that you can eval() it. Not that I would do such a thing.
|
|
#
?
Nov 7, 2015 20:18
|
|
|
Fear not! IBM (as only they in particular possibly could) has created something to give us the best of all possible worlds! https://www-01.ibm.com/support/knowledgecenter/SS9H2Y_7.1.0/com.ibm.dp.doc/json_jsonx.html code:BigRedDot fucked around with this message at 21:12 on Nov 7, 2015 |
|
#
?
Nov 7, 2015 21:07
|
|

|
That's useful because you only gotta write a schema for JSON once and can encode arbitrary JSON to schema-having XML!
|
|
#
?
Nov 7, 2015 21:16
|
|

|
BigRedDot posted:
Doesn't XML have dumb af whitespace rules that makes this not work? I thought it would need to be > 640
|
|
#
?
Nov 7, 2015 21:41
|
|
|
Suspicious Dish posted:oh, and I forgot how we couldn't agree on a schema format for XML, so we now have six of them. ddml, dsd, dtd, xsd, relax-ng, schematron Oh nobody use those schema formats nowadays, forget them, they are just useless cruft and boilerplate, no serious xml coder writes that by hand anymore but you just generate that (and also any number of theroretical upcoming schema formats) under the new abstracted generic universal generalized schema format factory paradigm.
|
|
#
?
Nov 7, 2015 21:48
|
|
|
Suspicious Dish posted:Doesn't XML have dumb af whitespace rules that makes this not work? I thought it would need to be > 640 No, that's HTML you're thinking of. NBSP actually refers to U+00a0 "no-break space", which is different from U+0020, the regular space. It just so happens that a non-breaking space is exactly as wide as a regular space, so it's useful for working around HTML's whitespace collapsing. Proper XML parsers leave all spaces as-is, also in things like: XML code:pre:root + text: "\s\s" + element: foo + text: "\n\s\s\s\ssome stuff here\n\s\s"
|
|
#
?
Nov 7, 2015 21:58
|
|




|
That something I actually wondered about. Doesn't that mean that:code:code:
|
|
#
?
Nov 7, 2015 22:56
|
|
|
XML doesn't specify what to do if xml:space is default, but if it's preserve then that would be the case. IIRC.
|
|
#
?
Nov 7, 2015 23:06
|
|


|
But the content model usually only permits elements or character data in a given element's content, so I think it's not commonly a problem.
|
|
#
?
Nov 7, 2015 23:09
|
|
|
Huh. I never knew about xml:space. But I'm still generally confused by XML's namespaces. Normally, you have:XML code:XML code:I'm using the syntax ("foo", X) to define an element named X in namespace "foo". Usually namespace values are URIs, but my understanding is that they are just strings, without any URI semantics (so "http://www.w3.org/butts/" and "http://www.w3.org/butts/../butts/" are two different namespaces, even though they parse to the same URI) We can also define other namespace shorthands using the magic xmlns:baz="foo" attribute and we can say <baz:bar /> and such, and it means the same thing. It's weird because xmlns is both an attribute name and also a special predefined namespace, both of which affect parser behavior from that element down. But now you're saying there's also a magic xml:space attribute / xml namespace, even though it doesn't expand do anything, that's implicitly defined by default? I can't find any expansion for what namespace xml maps to. And this attribute, unlike most others, also affects parser behavior. It's this sort of complexity that makes me really frustrated working with XML. The data model seems inconsistent and hard to grasp, because there are so many special cases.
|
|
#
?
Nov 7, 2015 23:19
|
|
|
!CDATA
|
|
#
?
Nov 8, 2015 00:30
|
|
|
BigRedDot posted:Fear not! IBM (as only they in particular possibly could) has created something to give us the best of all possible worlds! JSONx is one of the few things which preserves key ordering and duplicate keys in JSON objects.
|
|
#
?
Nov 8, 2015 01:10
|
|
|
Biowarfare posted:!CDATA I'm the <![CDATA[]]]]><![CDATA[>]]> fish. Also - there're these things: http://json-schema.org/ and http://json-ld.org/, both of which feel completely unnecessary qntm posted:JSONx is one of the few things which preserves key ordering and duplicate keys in JSON objects. edit: huh - it's hilarious that duplicate keys in JSON is an undefined behavior. canis minor fucked around with this message at 01:36 on Nov 8, 2015 |
|
#
?
Nov 8, 2015 01:29
|
|
|
Blinkz0rz posted:Pretty much the only downside to XML is the verbosity in terms of characters used. JSON is appealing because it's concise and you can transfer a lot of info without moving a lot of data. Wait, are we actually saying that JSON is an efficient format? Maybe compared to XML, and for particularly short or heterogeneous data it isn't too terrible, but I'd hardly consider that an advantage.
|
|
#
?
Nov 8, 2015 04:58
|
|

|
Jesus christ, it's not that complicated: They're both terrible and never ever should've been adopted. JSON is terrible because it attempts to represent structured data without a schema or metadata and with only a handful of datatypes. XML is terrible because it allows so much complexity that it's basically code. In fact, some people thing using XML as code is a good idea. Also it totally fails at being human readable. As with all engineering problems, we've had a wonderful, expressive transport format for many many years. It defines a tight, well defined syntax and it works great. Of course, it's not the sexy new thing so no one uses it: 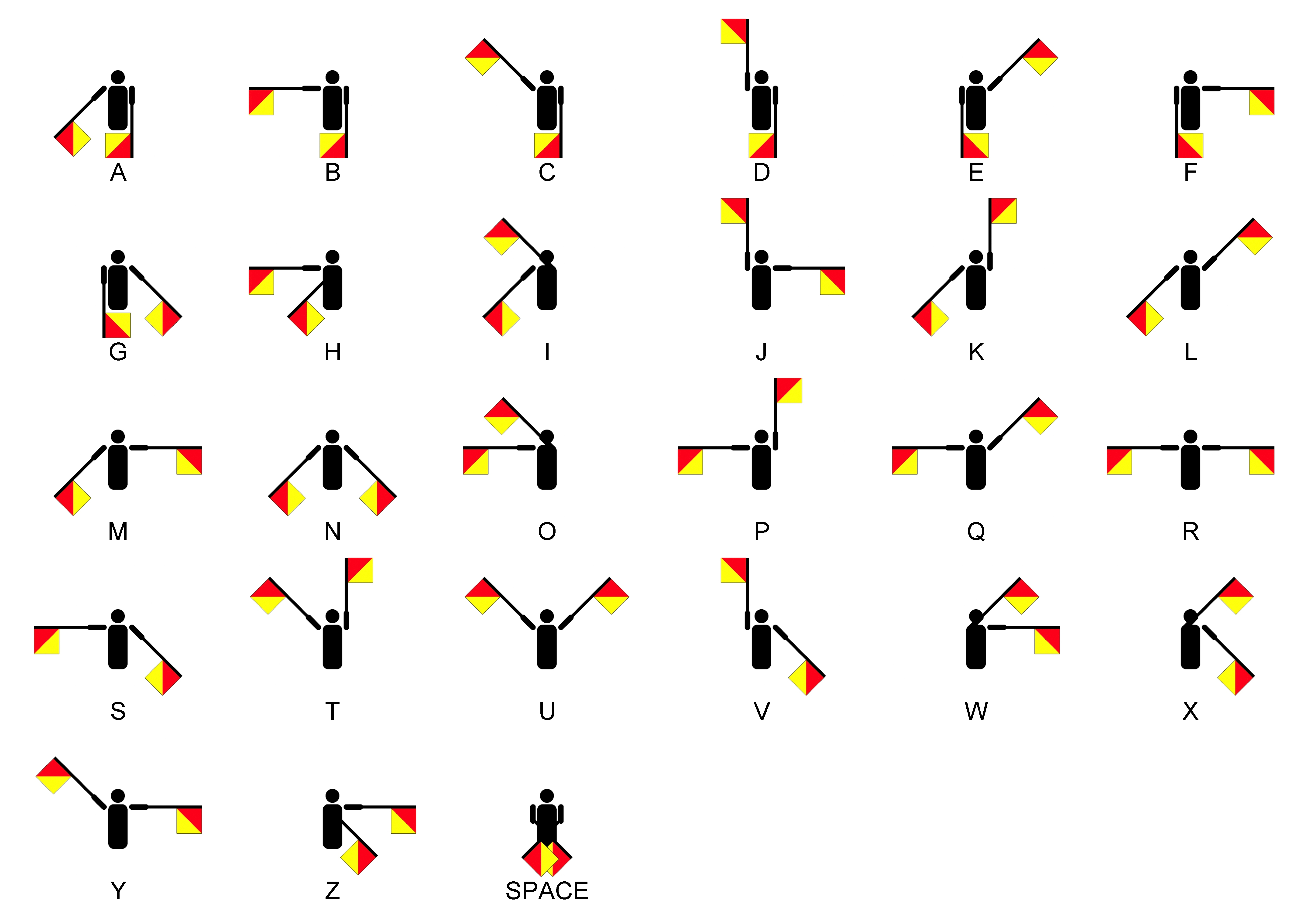
|
|
#
?
Nov 8, 2015 05:28
|
|

|
MALE SHOEGAZE posted:Of course, it's not the sexy new thing so no one uses it: Whatever dude, I use semaphores all the time
|
|
#
?
Nov 8, 2015 05:32
|
|

|
Winter Stormer posted:Whatever dude, I use semaphores all the time Wish your posts used semaphores!
|
|
#
?
Nov 8, 2015 07:29
|
|
|
I don't see what is inadequate about the types of data JSON supports. It seems a more reasonable than XML on that count actually.
|
|
#
?
Nov 8, 2015 08:56
|
|


|
Suspicious Dish posted:I thought most XML parsers just threw out the whitespace (or perhaps all text nodes?) when you go through the children because nobody cared about them. At least the parsers I've worked with do that when given a schema-less XML document. fleshweasel posted:I don't see what is inadequate about the types of data JSON supports. It seems a more reasonable than XML on that count actually. XML by itself only has text, but I think XML Schema specifies allowed formats and their interpretations for element contents?
|
|
#
?
Nov 8, 2015 09:01
|
|
|
just do what i do and base64-encode an entire binary file like image or executable and store it in <data>[giant blob]</data> easy
|
|
#
?
Nov 8, 2015 09:59
|
|
|
fleshweasel posted:I don't see what is inadequate about the types of data JSON supports. It seems a more reasonable than XML on that count actually. You can just encode everything as a string element, sure, but the primitives are annoying due to inherited Javascript brain damage, most notably by treating all numbers as double-precision floating point. (That said, these format wars are silly. Writing a parser is not hard when using modern combinator techniques.)
|
|
#
?
Nov 8, 2015 10:10
|
|

|
Athas posted:(That said, these format wars are silly. Writing a parser is not hard when using modern combinator techniques.)
|
|
#
?
Nov 8, 2015 11:52
|
|


|

|
| # ? Jun 1, 2024 12:34 |
|
|
Volte posted:Writing a parser is not hard, but the problem with data interchange formats is that we need to write a parser (and serializer, probably) for every target language, and those parsers must have identical semantics. Even worse than a parser that rejects input that another parser accepts (or generates, even) would be one that accepts the input but interprets it differently, resulting in data that gets transformed arbitrarily as it is transferred. JSON in this regard is already hosed with Dates and other non-primitive types, so you're pretty much stuck either manually encoding everything to strings and numbers before you let any JSON dumper touch it, or making drat sure that that both ends are using the same JSON serialization/deserialization semantics. If any format has a show-stopping flaw as an interchange format, it's JSON simply because of that. It's fine for simple persistence and data transfer where you control both ends but it's awful for trying to get data from one place to an arbitrary other place without its meaning getting hosed up along the way. The best part is that json isn't even compatible with the javascript specification.
|
|
#
?
Nov 8, 2015 11:58
|
|