


|
Comment before the if is about "why is there a branch here?" Comment inside the if is about "what is the purpose of this path?"
|
 #
?
May 9, 2019 21:35
#
?
May 9, 2019 21:35
|
|


|

|
| # ? Jun 10, 2024 11:53 |
|
|
Thermopyle posted:I prefer the comment before the if block. Just think of a comment as a freestyle decorator
|
|
#
?
May 9, 2019 21:49
|
|




|
I use both and treat under the if like a docstring and above the if like a strong warning to whichever poor soul is using my code
|
|
#
?
May 9, 2019 21:56
|
|

|
When working with relational data, do you keep it in relational format or just flatten it all? I'm pulling a bunch of stuff out of a database and the tables are all normalized correctly, and I'm not sure whether to keep the small id:text tables. So for example, each item has a "language_code" parameter, in the database it might be 1/2/3 for en-US/fr-FR/de-DE but I could easily pull that out and have it be "en-US" instead of 1 and not even maintain this separate table at all. Advantages of being more human readable might outweigh the bloat and slowness of trying to update all 5k items if we changed to "en_us" or something. I'm used to working with databases, so normalized data is totally standard to me but maybe in Python / JSON this becomes an antipattern? Anyone ever dealt with this one way or the other and then regretted it?
|
|
#
?
May 9, 2019 22:18
|
|

|
I mean, I can imagine settling all style arguments with Black. https://github.com/python/black It's being used to format core python code now and is part of PSF.
|
|
#
?
May 9, 2019 23:23
|
|


|
I'd say before the if and never use elif. Before the if because it's clear that the comment expresses something about the comparison as a whole, if that makes sense. Never use elif because you should return or continue instead; or use a dict with (nested) functions if you want to switch on a value. E: oh jeez I'm a page too slow.
|
|
#
?
May 10, 2019 01:08
|
|
|
pmchem posted:I mean, I can imagine settling all style arguments with Black. I use Black everywhere I can (aka, where there are not other styling conventions). But, I don't think it has a stance on this particularly styling thingamajig.
|
|
#
?
May 10, 2019 01:26
|
|

|
dougdrums posted:I'd say before the if and never use elif. What does switching like that on a dict look like in practice?
|
|
#
?
May 10, 2019 01:47
|
|

|
I'm phonepostin' and otherwise preoccupied so to speak, so this isn't really a useful example but somehing like:Python code:Python code:Oh and if you want to match on regex or an expression, you can filter with a comprehension over the dict then reduce. Else Statement Considered Harmful dougdrums fucked around with this message at 02:41 on May 10, 2019 |
|
#
?
May 10, 2019 02:14
|
|
|
mr_package posted:When working with relational data, do you keep it in relational format or just flatten it all? I'm pulling a bunch of stuff out of a database and the tables are all normalized correctly, and I'm not sure whether to keep the small id:text tables. So for example, each item has a "language_code" parameter, in the database it might be 1/2/3 for en-US/fr-FR/de-DE but I could easily pull that out and have it be "en-US" instead of 1 and not even maintain this separate table at all. Advantages of being more human readable might outweigh the bloat and slowness of trying to update all 5k items if we changed to "en_us" or something. I tend to keep things relational by having my DB models represented as classes with relevant methods for accessing related objects. So in your case, I'd have something like: code:You can even add a @property decorator above the method so it can be accessed as Text().lang. I would recommend looking into ORM and datamapper design patterns for more ideas.
|
|
#
?
May 10, 2019 02:44
|
|

|
skull mask mcgee posted:This way you can have the human readable value without de-normalizing the database. One wrinkle is I'm basically migrating from a database to JSON (seems friendliest serialization format). But your approach would still work, it would just be reading it out of a dictionary (which is itself parsed JSON) instead of directly querying the db. I'm essentially doing SQL export to JSON, and trying to decide on what the schema/design of what that JSON should be. I am not sure how much 'first normal form' style of data modeling to maintain in this case. The DBA in me says 'don't throw away this data / schema, it's useful and correct' but pragmatically I look at this and say 'actually YAGNI, just write it out as a config and forget the old database'. I suppose the fundamental question is: if you're writing an app that is using a kind of medium-small data set (20k records or so?) but not using a database backend or even SQLite, would you still always always always model that data as relational? Or would you kind of cheat and make it a slightly bloated JSON config file and not worry about it too much? Is there a rule I just don't know about, like "No, it doesn't matter, you don't need a database so just use whatever format is most readable" or maybe "Yes for the love of god keep the data normalized it will save you so much pain in six months when you need to add another platform/target /os".
|
|
#
?
May 10, 2019 05:43
|
|
|
fourwood posted:I think I prefer a comment before the if but then after the else.... I�m a monster. I do this too which is why I asked! Comment above the if makes sense to me, but comment above the elif (or the else) looks misplaced so I bring it into the elif/else block. But then I lose 4 characters  pmchem posted:I mean, I can imagine settling all style arguments with Black. Black is great and I use it when I can, but yeah it doesn�t come into the equation for what I�m asking (and for good reason? I�m fine with code formatters deciding my comment was too long and making it into multiple lines� but it probably shouldn�t touch where I put the comment). dougdrums posted:I'd say before the if and never use elif. I guess I was talking more about 1:1 math functions, like the one I stole from here: 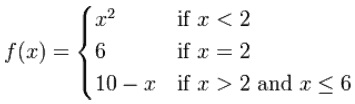 It normally ends up programmed like so: code:Boris Galerkin fucked around with this message at 07:23 on May 10, 2019 |
|
#
?
May 10, 2019 05:51
|
|

|
Nippashish posted:Comment before the if is about "why is there a branch here?" Comment inside the if is about "what is the purpose of this path?" Yeah I do it that way, too. Thermopyle posted:I prefer the comment before the if block. This is how i write docstrings: Python code:
|
|
#
?
May 10, 2019 09:03
|
|

|
dougdrums posted:I'd say before the if and never use elif. I don't think that this is good advice; if/elif/else give you much more control and capability than a dict and I can think of numerous examples where I'd want to use these builtin Python keywords instead of hacking together some sort of dictionary implementation (which I assume would also be much slower on repeated calls?) QuarkJets fucked around with this message at 09:08 on May 10, 2019 |
|
#
?
May 10, 2019 09:06
|
|
|
Boris Galerkin posted:I guess I was talking more about 1:1 math functions, like the one I stole from here: For the example given, I'm of the opinion that it is always better to write a seperate function in the form: Python code:
QuarkJets posted:I don't think that this is good advice; if/elif/else give you much more control and capability than a dict and I can think of numerous examples where I'd want to use these builtin Python keywords instead of hacking together some sort of dictionary implementation (which I assume would also be much slower on repeated calls?) In the case where you're simply matching by equality (or equality of a type) like a more traditional switch construct, I definitely prefer it. Calling this simple case 'hacky' is naive. A lot of times when I'm writing a switch, I really just want a table of calls, possibly wrapped in another call. A dict with functions as values expresses my intent exactly. If the performance of this is really an issue, you shouldn't be using python. If you must and are are still concerned that it is creating a dict object each time (no idea if this is the case, but I would also assume so), you can define an instance of it immediately before the function definition and refer to that.
|
|
#
?
May 10, 2019 10:58
|
|
|
QuarkJets posted:
TIL you can use syntax highlighting in code blocks� and also that comments don't get rendered 
|
|
#
?
May 10, 2019 11:39
|
|
|
dougdrums posted:If the performance of this is really an issue, you shouldn't be using python. If you must and are are still concerned that it is creating a dict object each time (no idea if this is the case, but I would also assume so), you can define an instance of it immediately before the function definition and refer to that. Python is a commonly used language in the HPC domain for its ability to act as a glue language, but inevitably performance-impacting code will sometimes get written in Python. Don't assume that people who use python don't care at all about performance. It's fine if you prefer using dictionaries as switch statements and lots of function calls, but it's not reasonable to call that combination a one-size-fits-all approach that's always superior to if/elif/else statements. There are cases where I'd rather have those kinds of blocks, and others where a function call will serve nicely instead
|
|
#
?
May 10, 2019 11:39
|
|
|
QuarkJets posted:Python is a commonly used language in the HPC domain for its ability to act as a glue language, but inevitably performance-impacting code will sometimes get written in Python. Don't assume that people who use python don't care at all about performance. QuarkJets posted:It's fine if you prefer using dictionaries as switch statements and lots of function calls, but it's not reasonable to call that combination a one-size-fits-all approach that's always superior to if/elif/else statements. There are cases where I'd rather have those kinds of blocks, and others where a function call will serve nicely instead
|
|
#
?
May 10, 2019 12:19
|
|
|
I had a longer response typed out but I'll just say this: In an ideal world all code would be bug-free, tested, documented, and just work and I would have all the time in the world to do all the things that should be done. But that's not the world I live in, and sometimes I have to trade performance vs convenience by computing stuff directly in Python or Matlab on my laptop with limited RAM and a crippled mobile CPU, instead of spending time chasing better implementations for a thing that I'm only going to run a handful of times.
|
|
#
?
May 10, 2019 13:36
|
|
|
Python excels at sketching things out, and getting poo poo done, but those things aren't necessarily mutually inclusive. Whether or not you use else statements vs. a separate function is splitting hairs, especially if it's something you only use a few times. If it's something you only need to run a few times and you find yourself optimizing a python program in detail for it to finish in a reasonable timeframe, it should've been written in a different language from the start. You've wasted time having used python in the first place. Python won't meet the requirements, and it was a mistake to assume that it would. On the topic of not using else statements, or writing switches as dicts, it doesn't really take extra time or effort to figure out or implement, so I'm a bit confused if that's what you're referring to. If it's something you later intend to run on a cluster, hashing it out it python is good for a proof of concept. Ime if you have an application for HPC and the performance of python code is a pain point, trying to optimize it is a waste of time and money vs. porting it.
|
|
#
?
May 10, 2019 14:40
|
|
|
I've had a few cases that writing better code and running with pypy instead of cpython has solved whatever performance troubles I was having. Incidentally pypy with 3.6 syntax/features is now considered beta and the unicode improvements haven't half made string processing fast as hell.
|
|
#
?
May 10, 2019 15:11
|
|



|
Pypy is good poo poo. I've had people tell me that they didn't want to use pypy because they thought tracing was bad but I was like, ok, you're paying anyways.
|
|
#
?
May 10, 2019 15:19
|
|
|
QuarkJets posted:
There's always someone who has to be difficult.
|
|
#
?
May 10, 2019 16:14
|
|
|
Anyone have any package suggestions for extracting tables of data from image files (.png/.jpg) ? I tried using Tesseract/pytesseract and while it's doing a great job of detecting the text, the tabular aspect of it is totally lost and I couldn't find a straight forward path to processing tables with it. I've used Camelot with PDFs before, and it worked OK (at best), but I'm hoping to use something else this time around.
|
|
#
?
May 10, 2019 16:19
|
|

|
Thermopyle posted:There's always someone who has to be difficult. If it's consistent, this is at least easily parsable via inspect.getcomments(), which means one can automatically rewrite it as proper docstrings. It's unnecessary, but at least fixable. 
|
|
#
?
May 10, 2019 16:32
|
|

|
punished milkman posted:Anyone have any package suggestions for extracting tables of data from image files (.png/.jpg) ? I tried using Tesseract/pytesseract and while it's doing a great job of detecting the text, the tabular aspect of it is totally lost and I couldn't find a straight forward path to processing tables with it. I've used Camelot with PDFs before, and it worked OK (at best), but I'm hoping to use something else this time around. Can you extract the information into a tuple and create a table in something like pandas?
|
|
#
?
May 10, 2019 17:54
|
|

|
Thermopyle posted:I prefer the comment before the if block. thaaaaats python. putting shame into your coding style for no good reason.
|
|
#
?
May 10, 2019 18:13
|
|


|
EVIL Gibson posted:thaaaaats python. putting shame into your coding style for no good reason. That and not having a switch, we hit all the high notes on one page
|
|
#
?
May 10, 2019 18:25
|
|




|
a dingus posted:Can you extract the information into a tuple and create a table in something like pandas? This is the kind of thing I'm trying to make sense of with OCR: https://images.app.goo.gl/aDrkvVibCzvGnbNy7
|
|
#
?
May 10, 2019 18:48
|
|
|
shrike82 posted:There's an amazing Python ebook bundle on Humble bundle - https://www.humblebundle.com/books/python-oreilly-books A little late, but thank you for linking this deal.
|
|
#
?
May 10, 2019 18:50
|
|


|
mr_package posted:Thanks that is something I was thinking about too-- keep the schema as-is and then just try to provide a clean interface (if only to myself) to it. I probably would, but I also try and keep my models fairly agnostic of where the actual data is coming from. Common properties would come from a base class/mix-ins or sometimes stored in an object/dict passed into the instance. When it comes to serialization, I'm definitely doing a bit of flattening. 2-column id:text tables are probably just going to be represented as the text. Related tables with more fields get an object(take care if your db structure allows for recursive dependencies ) and/or locator uri if this is being served as a REST API. I personally try and avoid de-normalizing an already normalized database, especially as a shortcut to what my bespoke ORM should handle in code anyways. I totally believe you can make an educated decision to do so and be fine. For instance, with the lang table you mentioned in the first post, one could argue that since language tags are already standardized, keeping them in a separate table is excessive. OTOH that sort of table structure can be a real benefit if you need to track down / prevent typos or other invalid data. I've actually been doing basically the opposite of what you've been doing, which is writing a wrapper for a REST api I pull data from pretty regularly, which will probably end up in a sqlite database. I made heavy use of dataclasses, which I highly recommend looking into(namedtuples, too). Here's my base model class and one of the child classes. Python code:susan b buffering fucked around with this message at 19:06 on May 10, 2019 |
|
#
?
May 10, 2019 18:57
|
|
|
punished milkman posted:Anyone have any package suggestions for extracting tables of data from image files (.png/.jpg) ? I tried using Tesseract/pytesseract and while it's doing a great job of detecting the text, the tabular aspect of it is totally lost and I couldn't find a straight forward path to processing tables with it. I've used Camelot with PDFs before, and it worked OK (at best), but I'm hoping to use something else this time around. I cannot remember the specifics, but I feel like Microsoft or Google have an Azure/Google Cloud API to do this.
|
|
#
?
May 10, 2019 19:35
|
|
|
dougdrums posted:Sure, but this construct is probably not going to be the slowest part of your python program. If it comes to that, you should consider implementing it in a compiled language. (Or at least that part of your program.) It doesn't matter whether it's the slowest part. The point is that you're trying to convince people to change convention in a way that sacrifices some performance for no tangible benefit. Lots of people combine compiled code with Python, it's an extremely common usecase. The tradeoff between developer time and software performance is not always simple, and I would rather continue using a style that costs no additional time, is highly legible, and is naturally performant for the myriad cases where I don't intend to apply a profiler to a project.
|
|
#
?
May 10, 2019 22:31
|
|
|
skull mask mcgee posted:I made heavy use of dataclasses, which I highly recommend looking into(namedtuples, too). code:edit: also kind of looks like a lot of work to make @dataclass objects JSON serializeable but maybe that's just me being lazy. This feels like a lot of boilerplate just to make the json module happy. https://martin-thoma.com/make-json-serializable/ But I did also find jsonpickle which I'd never seen before which solves this problem http://jsonpickle.github.io/ mr_package fucked around with this message at 23:25 on May 10, 2019 |
|
#
?
May 10, 2019 22:56
|
|
|
punished milkman posted:Anyone have any package suggestions for extracting tables of data from image files (.png/.jpg) ? I tried using Tesseract/pytesseract and while it's doing a great job of detecting the text, the tabular aspect of it is totally lost and I couldn't find a straight forward path to processing tables with it. I've used Camelot with PDFs before, and it worked OK (at best), but I'm hoping to use something else this time around. Table detection isn't a solved problem even with current deep learning models.
|
|
#
?
May 11, 2019 01:06
|
|

|
punished milkman posted:Anyone have any package suggestions for extracting tables of data from image files (.png/.jpg) ? I tried using Tesseract/pytesseract and while it's doing a great job of detecting the text, the tabular aspect of it is totally lost and I couldn't find a straight forward path to processing tables with it. I've used Camelot with PDFs before, and it worked OK (at best), but I'm hoping to use something else this time around. This isn't an easy problem. If the images are fairly consistent you can try using one of the tesseract outputs that supplies word coordinates and do your own table determination based on the relative positions of words. It might also be useful to run the images through opencv first to extract the positions of the lines (possibly also removing them from the image, or splitting into several small images prior to OCR). You might look at AWS Textract (still in preview) or the Google/Azure OCR services, too, if someone's paying for it.
|
|
#
?
May 11, 2019 02:57
|
|

|
Extortionist posted:This isn't an easy problem. If the images are fairly consistent you can try using one of the tesseract outputs that supplies word coordinates and do your own table determination based on the relative positions of words. It might also be useful to run the images through opencv first to extract the positions of the lines (possibly also removing them from the image, or splitting into several small images prior to OCR). I think splitting the images up into sections with OpenCV and then extracting/parsing the text is what I'll need to do. This is way more involved than I thought... loving tables
|
|
#
?
May 11, 2019 04:03
|
|
|
Just curious, is there a long story short on why tables are hard?
|
|
#
?
May 11, 2019 04:27
|
|

|
KICK BAMA KICK posted:Just curious, is there a long story short on why tables are hard? From my own experience it's because there are very few rules followed by tables beyond there being some semblance of aligned columns/rows of related data. Our brains are pretty good at contextualizing and making sense of what we see in a table, but there are a ton of potential subtle nuances that make a universal/generic computational solution very difficult.
|
|
#
?
May 11, 2019 04:40
|
|
|

|
| # ? Jun 10, 2024 11:53 |
|
|
QuarkJets posted:It doesn't matter whether it's the slowest part. I already addressed the rest of what you said. Nobody I know personally has felt the need to expresses how my use of a dict for a switch is morally corrupt, and I find it useful so I'm gonna keep doing it. I also provided an alternative example with several concrete arguments for why I find it preferable to using else statements. And there's the slightest chance I was being hyperbolic in my original post, for the sake of internet posting. E: I mean like goddamn how did you read (and quote) what I posted and then decide to write that out. I had to go back and reread them just to make sure I actually wrote what I thought. Use else statements if you want, I'm gonna stop making GBS threads things up with my heresy. dougdrums fucked around with this message at 05:50 on May 11, 2019 |
|
#
?
May 11, 2019 05:35
|
|