


|
Is there a recommended dummies book for understanding the basics of SQL? I just started a new job in hospital clinical informatics. I doubt I'll ever write to a database but I'm sure it would be handy if I knew how to read and pull reports from them. I'm trying to teach myself VBA and Python to that end.
|
 #
¿
Jul 3, 2014 03:54
#
¿
Jul 3, 2014 03:54
|
|

|

|
| # ¿ May 21, 2024 04:55 |
|
|
I need to learn how to write SQL queries for work. I just stepped through the free Stanford Relational Algebra videos and they were surprisingly engaging. Next is the SQL section of videos. I know that often times theory can be learned in the classroom but never knowingly utilized in the field. For those who write queries, how often (if ever) do you think about relational algebra? Hughmoris fucked around with this message at 01:55 on Dec 31, 2017 |
|
#
¿
Dec 31, 2017 01:52
|
|
|
Is there a recommended formatting/style guide I should adhere to as I start learning to write SQL queries? I'm using SSMS but the computer is pretty locked down and I don't think I'll be able to use plugins to help.
|
|
#
¿
Dec 31, 2017 19:37
|
|
|
Thanks for the answers. One more beginner question: Should I be spending my time learning how to use the query builder/designer in SSMS, or should I focus instead on writing queries by hand for a while?
|
|
#
¿
Dec 31, 2017 21:23
|
|
|
NihilCredo posted:I work in an office full of young support people who use SSMS four out of eight hours a day but who couldn't tell you what a trigger is. I warned them several times that by blindly following wizards and menus, instead of learning the actual SQL commands and how they work, they're practically leaving money on the table (in the form of valuable skills and future job prospects). Please don''t do the same. Thanks for the advice. I'm not interested in taking short cuts if it'll possibly handicap me down the road. I just finished up the Wise Owl: SQL Server Queries series, and am working my way through some practice problems. Are there any SQL rooms in IRC or Discord that people hang out in, to get feedback on some simple queries I'm writing? For this particular problem: I have a Movies DB, and I want to know who the oldest actor is for each movie. My query returns the results but are there any easy improvements to be had?  SQL code:
|
|
#
¿
Jan 1, 2018 23:50
|
|
|
NihilCredo posted:One mistake: your query will return, for each movie, all the actors that share the same birth date as the oldest actor in the movie, even if those actors didn't appear in the movie. I've been trying my hand at fixing this for the past 45 minutes, can't figure it out. Any tips? I can explain what I need to do in pseudo code but I'm not sure how to tackle it in SQL. Hughmoris fucked around with this message at 02:58 on Jan 2, 2018 |
|
#
¿
Jan 2, 2018 01:27
|
|
|
kumba posted:You want to rank the birth dates within each movie, and only select the person with the lowest birthdate for each movie, so I'd use a ranking function in your CTE: Thank you. I haven't seen ROW_NUMBER() or PARTITION BY in my adventures yet, so I'll do some reading along with the ranking functions. NihilCredo posted:The subquery is fine. I'll give that a try. Thanks!
|
|
#
¿
Jan 2, 2018 03:16
|
|
|
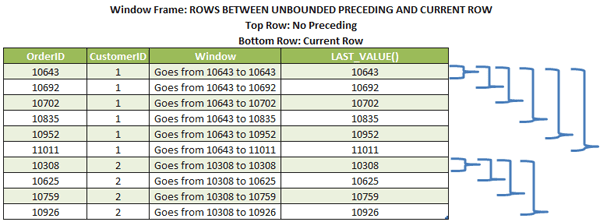
Ruggan posted:Windowed functions are really awesome and powerful, and I use them a lot. However, you need to be really careful with the window's frame. The frame of a window defines the subset of rows in which the function will work. The default frame is "BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW". That basically means, when analyzing this function across all your returned rows, only analyze rows that are between the beginning of your PARTITION and the row being calculated (not the end of your PARTITION). Thanks for the write up and link. What type of problems make you think "Hmmm, I need to use a window function here"?
|
|
#
¿
Jan 3, 2018 02:28
|
|
|
Ruggan posted:The classic example is to find the value associated with a local min or max. Let's use an example - we'll do something intuitively simple: stock prices. First, let's create some data: You're awesome. I really do appreciate you typing that up, and now windowed functions make much more sense. Another question for you: I did notice that you're using the '#' symbol throughout your code. This is the first time I'm seeing that symbol. A quick google tells me that it is "Prefix local temporary table names". Are you using it because you need it for this example, or do you use it in your day to day work too?
|
|
#
¿
Jan 5, 2018 01:54
|
|
|
Nth Doctor posted:# means a temp table, which is similar to a table variable except that it is actually created as a SQL object in the Temp database. I use then for scratch pad type stuff on sets of data, or for dashing up an example for this thread. They are basically scoped to one connection and should get explicitly cleaned up when you're done with them. Thanks for the clarification. I just wrote my first basic query that actually produces data I can use for my job. Feels good. Hopefully this is the beginning of the end of submitting data requests and waiting on others to create reports for me. I have a question about how to think about a different problem in SQL. I've solved it in Python but I have to go through the headache of splitting queries in to different CSV files and writing more code. I have two tables. TABLE A is occurrences, TABLE B is time windows. For each occurence in TABLE A, I need to see if it fell within any of its available time windows. I just need a Y/N or 0/1 to signify if it did or not. Any guidance on how to approach this is appreciated. TABLE A:  TABLE B:  FINAL RESULT: 
|
|
#
¿
Jan 12, 2018 06:37
|
|
|
Kuule hain nussivan posted:My first, possibly inefficient mock for this. I'll give this a shot. Thanks!
|
|
#
¿
Jan 13, 2018 01:03
|
|
|
Still learning my way through SQL, a bit stumped on how to tackle something with SQL Server. I have a query that returns the results I want code:Ideally, the end result is: code:Any guidance is appreciated.
|
|
#
¿
Feb 2, 2018 05:34
|
|
|
Nth Doctor posted:
You're a saint. Thanks!
|
|
#
¿
Feb 2, 2018 17:13
|
|
|
SQL rookie question: I was given an excel report with 4,000 account IDs and they want me to look up the associated account names in SSMS. It's a single table that contains both but it is greater than 5 million rows. I initially tried exporting all account IDs and account names from SSMS to Excel and do a simple VLOOKUP but Excel had a heart attack. What's good practice for something like this? My second thought was a simple: SQL code:
|
|
#
¿
Mar 20, 2018 23:10
|
|
|
Thanks for the ideas. I did the Excel method mentioned above and it worked great. As a learning exercise I'm going to try to create a table and figure out how to slurp in the Excel sheet, since I haven't dealt with creating tables yet.
|
|
#
¿
Mar 21, 2018 03:41
|
|
|
I'm still learning the basics of SQL Server and need a little guidance on a problem: I have a table of hospital admissions and I'm joining it to a table of lab procedures. I end up with something like this: code:code:Hughmoris fucked around with this message at 05:14 on Jun 19, 2018 |
|
#
¿
Jun 19, 2018 04:50
|
|
|
anthonypants posted:Dunno what flavor of SQL you're in but you're probably looking at a Common Table Expression here. Something like this: Thanks for taking the time to type that up. I'm using SQL Server, and am starting to explore CTEs. I believe I see how your solution is working, and will give it a go in the morning. Thanks again! Hughmoris fucked around with this message at 05:25 on Jun 19, 2018 |
|
#
¿
Jun 19, 2018 05:13
|
|
|
quote:Hospital Lab SQL stuff... Thanks everyone for the tips, I was able to get the results I needed.
|
|
#
¿
Jun 20, 2018 01:57
|
|
|
I have a beginner T-SQL question that is tripping me up: I have a table: code:So my end result is ideally something like this: code:
|
|
#
¿
Jul 15, 2018 01:40
|
|
|
Hammerite posted:There are multiple ways of achieving this sort of result IIRC. One way to do it is to construct a subquery that gets the minimum and maximum for each order, then join it against two copies of the original table so as to get the PERSON data from that table. I was able to apply this concept to my problem and it worked like a champ. Thank you!
|
|
#
¿
Jul 15, 2018 20:21
|
|
|
I'm continuing my journey of learning SQL, specifically T-SQL. I'm starting to explore how to set a query to run weekly on a specific weekday. I'm an analyst that is not part of the server or date warehouse team. Assuming my company has all the typical SQL reporting tools (SSRS?), what should I read up on for the simplest way to schedule a T-SQL query to run every Tuesday? Ideal world, the query runs every Tuesday and it emails the resultant CSV file to somebody. Hughmoris fucked around with this message at 05:39 on Aug 2, 2018 |
|
#
¿
Aug 2, 2018 05:33
|
|
|
Cold on a Cob posted:Read up on the sql agent jobs. If all you want is csv results, you can use sp_send_dbmail from inside your sql job. Thanks for the guidance and links! Say I wanted to end up getting fancier than a CSV. I have an Excel workbook that I use as a reporting template. Basically I open the workbook template, refresh my data with the latest CSV file which in turn updates my pivot tables, then save and email out. I'm all for automating as much as possible. Do you see a path to accomplish this given the need to run the query first? I've fairly comfortable with VBA and basic scripting (not T-SQL related) but my workstation isn't always on when it needs to run. *Well that sucks. Looks like I dont have access to SQL Agent Jobs. Hughmoris fucked around with this message at 16:00 on Aug 2, 2018 |
|
#
¿
Aug 2, 2018 15:05
|
|
|
Thanks for the ideas on how to schedule a weekly query and email. I have an older coworker who is a Microsoft Excel and Access guru. He pretty much exclusively uses the Query Designer (visual designer) in Access, and he is struggling a bit in transitioning to T-SQL since the Query Designer in SSMS is poor compared to Access's (per him). Are there any third party tools I can point him at that have a great visual query designer, and can hook in to SQL Server?
|
|
#
¿
Aug 5, 2018 15:20
|
|
|
T-SQL novice, and I see a little guidance on how to approach a problem. I have a table that contains patients and their ordered medications. I have a second table which contains those patients and their lab results. What I want to do is evaluate what impact a medication order can have one their follow-up lab value. Medication_Table: code:code:code:Is this something that Window functions / Lead functions are meant for?
|
|
#
¿
Aug 19, 2018 01:35
|
|
|
Ruggan posted:Windowed functions are intended for doing some sort of partitioned or ordered calculation on your dataset. Lag and Lead are specifically for finding the last or next value of a row without needing to do some crazy joins and filtering. Usually you would use windowed functions on a single dataset (like an individual table or maybe a product of joins in the right situation). Let�s say you were trying to find the value of the prior lab result for the same lab: using Lag lets you skip hairy aggregations and self-joins. I learned something new today! I've never used the outer apply method before so I tried that out and it worked like a charm. To your point though, the performance is not great due to having to read through a lot of rows. I'll try my hand at the left join technique you spoke to. Thanks for the help!
|
|
#
¿
Aug 19, 2018 18:16
|
|
|
Hmm. Yeah, I think I'm going to have to figure out how to use the second method you recommended. The outer apply query is taking about 7 minutes for 1 month.
|
|
#
¿
Aug 20, 2018 01:39
|
|
|
In TSQL, is there a difference between putting a clause in the JOIN statement versus in the WHERE statement? I'm still learning SQL and I've seen it mentioned but I'm not sure I fully understand what occurs. SQL code:SQL code:
|
|
#
¿
Dec 1, 2018 21:17
|
|
|
kumba posted:There can be a difference, yes. See: Thanks for the links, and the other helpful information.
|
|
#
¿
Dec 2, 2018 03:49
|
|
|
Is there any recommended reading for SQL performance tuning for beginners? I'm using SQL Server, and have a query that takes roughly 2 minutes to run. The query runs overnight and is not mission critical but I'd like to try my hand at speeding it up. I'm not quite sure where to start reading/digging. *I'm not a DBA, just an analyst pulling data.
|
|
#
¿
Dec 8, 2018 17:10
|
|
|
Ruggan posted:I think you�re both expressing the same thing - that SQL is (mostly) declarative - and that you should generally write queries in the most human parseable format as the optimizer is usually pretty good at determining an efficient control flow. Thanks for the link, was an interesting read. rt4 posted:The biggest thing for reads is to EXPLAIN and see if it does any table scans. Another important pitfall to beware of is correlated subqueries. I'll take a look at EXPLAIN, thanks!
|
|
#
¿
Dec 9, 2018 17:53
|
|
|
Thanks for all the ideas. This is dealing with healthcare data so I err on the side of caution in regards to posting relevant details but I'll research the topics pointed out. I do have a problem that has turned out to be a stumper for me and two others I work with: I have a table that contains alarms and acknowledgements. An acknowledgement can clear multiple alarms. For a given alarm, when was the next acknowledgment that occurred? Original Table code:code:I've started utilizing window functions more but mainly for first and last values. This feels like I could use LEAD but I'm not sure how to use the conditional of AcknowledgeTime > AlarmTime. Hughmoris fucked around with this message at 00:49 on Dec 11, 2018 |
|
#
¿
Dec 11, 2018 00:37
|
|
|
Nth Doctor posted:Good stuff... Thanks for this! Nth Doctor posted:Ugh. I don't like schemas like this. I don't know on the first two questions. I need to read up on indices. Its a patient numerical ID, which is unique to the patient encounter. The event type is generic. The only unique things are the patient ID and the (relatively unique) timestamp. The gist of the basic query that returns the original table above is: SQL code:
|
|
#
¿
Dec 11, 2018 01:13
|
|
|
downout posted:Are you asking what query gets the results in "Ideal Endstate"? If so, you can join two data sets based on timestamps. The first data set is Alarms and the second is Acknowledgements. The join is pretty complex because you need the first row from the Acknowledgement set where the timestamp is greater than the Alarm timestamp. I can't remember exactly what the syntax was, but it's possible. Actually it might be cross apply. Correct, looking for a query to get the Ideal EndState. I believe I figured it out using a correlated subquery. The performance is a hot garbage fire but it returns the correct results (that I've validated so far).
|
|
#
¿
Dec 11, 2018 03:03
|
|
|
Nth Doctor posted:Query... PhantomOfTheCopier posted:At the risk of sounding prophetic, are you sure you really want the timestamps in the results? That is, are you really just looking for the final state for the user (a much easier problem), or do you truly need the alert and acknowledgement matched in that fashion? My understanding of the data is that an acknowledgement will acknowledge all of the alerts that have fired since the last acknowledgement. The timestamps are needed because the person requesting the report wants to the see stats around when during the day they typically fire, and how long on average until an alarm is acknowledged.
|
|
#
¿
Dec 12, 2018 01:15
|
|
|
Ruggan posted:
You are a wizard. Utilizing this method allowed me to query 11 months worth of data in about 10 seconds. My correlated subquery for 1 month of data took 8+ minutes. Nth Doctor, thanks for taking another crack at. I need to rewrite the query using your approach to see how it compares. I also need to start working on understanding execution plans. It's really great to see how other people approach a given problem, and storing those concepts for future problems. Hughmoris fucked around with this message at 03:59 on Dec 13, 2018 |
|
#
¿
Dec 13, 2018 03:50
|
|
|
Vague question here: When writing queries, do you typically familiarize yourself with the indexes before you start, or only when the performance needs improvement? I just learned about SP_HELPINDEX on SQL Server and am thinking I need to start using it.
|
|
#
¿
Dec 23, 2018 23:25
|
|
|
Nth Doctor posted:Only when the performance is a problem. Premature performance tweaks can have detrimental effects of you lock the query optimizer out of performing its magic. Ruggan posted:I never start by looking at the indexes. I write the query with the cleanest and most sensible syntax I can come up with, and 95% of the time that gives me a query that is good enough. At that point I�m done. Thanks for the insights. I recently took a SQL Assessment exam that my software vendor requires. Thanks to this thread, I aced it. In 2018 I've gone from barely being able to spell SQL, to creating executive facing dashboards. In 2019, I look forward to deepening my knowledge of SQL beyond simple data retrieval. Thanks for the help everyone!
|
|
#
¿
Dec 24, 2018 22:11
|
|
|
Bobcats posted:Are correlated sub queries bad practice? I’m trying to pull across a ton of tables(last events for whatever into their own column) and I see no other way to accomplish what I want to do. Other people can speak to practice but they've been dirt slow when I've had to use them. I replaced a corellated subquery with a window function and dropped the query time from 8 minutes to 11 seconds.
|
|
#
¿
Jan 13, 2019 20:11
|
|
|
Anyone here mess with Cerner and their CCL? With the help of this thread, I was just getting comfortable with writing basic queries in SQL Server. Recently changed jobs and this new places uses Cerner, which sounds like its built on top of Oracle and uses a proprietary SQL layer called CCL. One thing I've noticed immediately is how great SSMS is compared to this in-house Cerner tool.
|
|
#
¿
Jan 22, 2020 00:19
|
|
|

|
| # ¿ May 21, 2024 04:55 |
|
|
I might have an opportunity to take a BI/data warehouse job. I can write basic SQL and I've created data viz dashboards for leadership, both which I enjoy. The data warehouse part will be new to me. Stuff like ETL and SSIS etc... For those that do this type of work, what are your thoughts? Do you enjoy it? Is it a snooze fest? Does being an administrator for a data warehouse and ETL stuff have a lot of variability and things to learn?
|
|
#
¿
Mar 4, 2020 03:17
|
|