


|
fret logic posted:What are some good resources/books on programming theory? What aspect are you interested in? Algorithms? Data structures? Programming Languages (either specific language or in general)? Program design? Numerical Analysis? Operating Systems? Something else? Also a bit about your background may help so you don't get recommended something that is either too simple or too hard.
|
 #
¿
Feb 24, 2008 08:55
#
¿
Feb 24, 2008 08:55
|
|


|

|
| # ¿ Apr 28, 2024 22:15 |
|
|
fret logic posted:I'm just a CS freshman with little to no background in anything beyond basic Java/C syntax. Was just wanting to get some basic theory in my head while I'm learning these languages. In that case I'd recommend two books. First, The Practice of Programming by Kernighan and Pike. It will help get some good practices in your head and is a good choice for someone still pretty new to programming. Second is Code Complete by McConnell. It is a handbook of practical advice.
|
|
#
¿
Feb 24, 2008 09:29
|
|
|
fret logic posted:I'll check those out, thanks! Should I wait until I have a language down pretty well to read Code Complete? If you've taken a course or two of programming, you'll be adequately prepared for a large chunk of Code Complete. Of course if you have less experience it may take longer to wade through, but with some motivation you could do it. Also a note about Knuth's books. They are very good, but I'm not sure Avenging Dentist's warning is quite strong enough. To be able to digest any of it you'll want to have at least some experience with discrete math (proof techniques, some set theory, etc) and algorithms/data structures. For many topics TAOCP is the best reference you'll find. However it is very dense, and not really friendly to someone just starting out. I'd strongly recommend you look at a copy from the library before you even think of anything like buying them. If you look at them and find them to be too much, look for the book Concrete Mathematics by Graham et al. It is designed to contain the math one needs to tackle TAOCP and would be a good intermediary step (and I'd still recommend some discrete math before tackling Concrete Mathematics).
|
|
#
¿
Feb 24, 2008 10:23
|
|
")
|
fletcher posted:Is it more common to write variables as someVariable or some_variable? I can't decide which to use. I like using someMethod() instead of some_method(), so I'm thinking it would make more sense to use some_variable. The popularity of that kind of style issue depends on the language in which you are working.
|
|
#
¿
Feb 27, 2008 00:55
|
|
|
Appa Time! posted:I tried your suggestion and used the new number for the problem, it still did the same thing, ran for about four minutes and I gave up. I'm skipping evens in the primality test and the main method that checks if it's a factor of 600851475143. What kind of prime test are you using? If you're more specific about exactly what you are doing someone can probably point out what you are doing that is slow. Also the thing JawnV6 mentioned is known as the Sieve of Eratosthenes.
|
|
#
¿
Feb 27, 2008 02:58
|
|
|
Triangulum posted:The TIcalc site has a quadratic solver that expresses the answer as a radical but I don't have a link cable. Maybe I can convince the one person in my class with this version of the quad EQ program to give me a look at the code so I can figure out how the gently caress it was done. It's not a huge deal or incredibly important but it's driving me nuts and I would like to learn how to do it. If the program posted is actually TI-Basic you should be able to open the file in just a text editor to view the source without a cable. Granted you'd have to reimplement the program yourself if you want it on your calculator, but it would tell you how it is done.
|
|
#
¿
Feb 27, 2008 23:12
|
|
|
Triangulum posted:I had assumed that as well until I opened the files in Notepad and got a huge string of gibberish. I could also be a moron, who knows! Interesting. I remember just opening the files in a text editor when I used to play with programs on my TI-86 and then 89. Maybe it was the linking software allows you to view the programs? This was many years ago though, so my memory is a little fuzzy on some of the details. 6174 fucked around with this message at 23:56 on Feb 27, 2008 |
|
#
¿
Feb 27, 2008 23:54
|
|
|
axolotl farmer posted:I'm writing a bash script that involves a long series of pipes. I also want to make it readable. What you are looking for is called a line continuation character. In the case of bash it is \
|
|
#
¿
Feb 28, 2008 17:45
|
|
|
nbv4 posted:edit: by the way, adding backslashes doesn't fix it either. Avenging Dentist didn't suggest adding backslashes. He suggested slashes, aka forward slashes.
|
|
#
¿
Mar 4, 2008 18:23
|
|
|
N.Z.'s Champion posted:This is a bit of a weird question but what programming languages use :: (double colon) as part of their syntax and for what? Info on any language would be appreciated, particularly if the syntax has different uses. Fortran 90/95 (and maybe 2003, but I'm not as familiar with it) uses it in variable declaration. code:
|
|
#
¿
Mar 4, 2008 18:42
|
|
|
I've been playing around with Project Euler and I've come across a small portion that I think has to have a better solution. In particular I'm working on problem 35 which has a rotation element. The idea is to take the least significant digit radix ten and make it the most significant with the remaining digits each becoming slightly less significant. For example 12345 would become 51234. I've come up with the following solution to this.code:edit: In case you are curious the converter<unsigned int, double> comes from Boost's numeric conversion stuff. I'm also more interested in the algorithm than an implementation which I can easily code up myself. 6174 fucked around with this message at 03:50 on Mar 22, 2008 |
|
#
¿
Mar 22, 2008 03:46
|
|
|
floWenoL posted:Sure. First, you want floor(log10(number)) + 1, and not ceil(log10(number)). That avoids the need for the extra test after. You can do discrete log10 (floor . log10) easily by trial multiplication of 10; there's no known efficient solution, though, but for the size of integers you're working with, it doesn't really matter. You can also do pow(10,x) easily by repeated multiplication, or repeated squaring, which is a bit faster, but again, it doesn't really matter for the size of the numbers you're working with.  I really should have seen those. Stupid being sick. Thanks floWenoL. I really should have seen those. Stupid being sick. Thanks floWenoL.
|
|
#
¿
Mar 22, 2008 05:49
|
|
|
JawnV6 posted:What's a good resource for learning how to implement a hashing algorithm? Have you looked at TAOCP vol 3?
|
|
#
¿
Apr 1, 2008 04:37
|
|
|
I've got some Fortran code I'm working on and I'm trying to find an automated way to find a class of bugs I've just come across. Basically if you're trying to specify a double precision constant and don't explicitly mention that they are double precision, some compilers will interpret them as single precision and throw off the calculations. An analogous error in C would be not putting "L" after a constant if needed. It seems to me that I should be able to come up with a regexp that would identify such constants. But I don't seem to be getting anywhere. What I'm looking for is numbers that look like XXXX.YYYY (with the . and Y optional) that are not of the form XXXX.YYYYDZZZ. The futzing I've done with grep/egrep haven't come up with anything that doesn't generate way too many false positives. A few false positives are fine as I need to sort through by hand anyway, but any false negatives would be bad. Does anyone know of a good way to find these constants? (Unfortunately the compilers I've got don't have warning flags that indicate if it truncates constants like this)
|
|
#
¿
Apr 2, 2008 17:34
|
|
|
tef posted:This seems to work for me: /(\b(\d{1,4}(?!\.)|\d{1,4}\.\d{1,4})(?!D\d{3})\b)/ This looks like it will work. This should be much better than trying to wade through 20K LOC, thanks.
|
|
#
¿
Apr 2, 2008 18:02
|
|
|
JawnV6 posted:I don't know what that is. "The Art Of C Programming" is coming up with several hits with different authors. TAOCP is The Art of Computer Programming by Knuth. edit: Since posting in the first place I've read (but not personally verified) that there is some discussion about hashing in the Dragon book as well (Compilers: Principles Techniques and Tools by Aho et al). 6174 fucked around with this message at 18:39 on Apr 2, 2008 |
|
#
¿
Apr 2, 2008 18:31
|
|
|
JawnV6 posted:I'll look into those two, does CLRS have any clear discussion on hashes? I've got that on my shelf at home, not quite sure why I didn't check it in the first place. CLRS has some discussion according to the table of contents.
|
|
#
¿
Apr 3, 2008 00:56
|
|
|
magicalblender posted:Why doesn't this program see the arguments I pipe to it? First off, wrong thread. Second, you misunderstand what the pipe does. It ties stdout of the first program to stdin of the second, it doesn't put stuff on the command line for the second program. If you printed values put to stdin in your showargs program you'd see the contents of myfile.
|
|
#
¿
Apr 16, 2008 18:55
|
|
|
magicalblender posted:As a follow-up, why is it that "cat myfile | ./showargs" works, but "cat myfile | showargs" does not work? What is the significance of the dot and slash? The dot and slash specify where to find the file "showargs". The "." means the current working directory, and the "/" is the standard directory separator. When those are not present the shell looks for the file "showargs" in the directories listed in the PATH variable (in the order they appear). Since the current directory is normally not part of the PATH, if you do not put the ./ the shell can't find "showargs".
|
|
#
¿
Apr 16, 2008 22:03
|
|
|
shodanjr_gr posted:Im gonna be doing a small project for uni on steganography (which is the hiding of data into other data - in my case, its messages in images). http://www.wotsit.org/
|
|
#
¿
Apr 30, 2008 20:03
|
|
|
csammis posted:This was the exact site I was thinking of to answer his question, but goddamn if I could remember the address and Googling wasn't helping I couldn't remember it offhand either, but it was #2 for "file specifications" at Google.
|
|
#
¿
Apr 30, 2008 20:10
|
|

|
I was making an ASCII table in LaTeX because the ones I've come across don't have the all info I want or aren't a single page to look at. The problem I'm having is of vertical alignment. Basically the layout is 4 tables. What I'd like is the tables to be vertically aligned. Unfortunately they don't seem to want to do that. The problem: 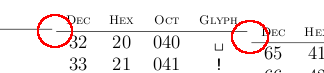 Full code at http://pastebin.com/m3ec6f484
|
|
#
¿
May 28, 2008 20:22
|
|
|
Gingerbread Wife posted:This isn't so much of a programming question, more of just a quick UNIX script. There is probably a better way to do it, but you could do something like code:
|
|
#
¿
May 28, 2008 20:28
|
|
|
JoeNotCharles posted:That checks the actual time the file was written, though - I think he wanted to sort by the date in the filename. (Makes a difference if the whole thing was backed up or copied, for instance, which might give them all the same last modified date.) Very true. To do it based on filename would potentially be much more complicated based on how the files are actually named.
|
|
#
¿
May 29, 2008 18:32
|
|
|
Lexical Unit posted:So in general, how do I write a loop like this in such a way that I get correct values for $I when dealing with the possibility of files with spaces in them? See points 1 and 2 at http://wooledge.org:8000/BashPitfalls
|
|
#
¿
Jun 3, 2008 20:51
|
|
|
Montalvo posted:So this a Fortran 95 question. I've got a data file with about 4 columns of 50000 entries consisting of numbers each. I want my code to scan through lines 30000 - 35000 of column 4 and find the highest entry there. How exactly would I go about doing this? When you open the file you need to specify the record length. It has been a while since I've done it, so double check my syntax with a reference, but basically open(LUN, file='filename', recl=rl, access=direct) Then to read read(LUN, rec=##) number1 number2 number3 number4 Where the rl is the line length in bytes (which must be the same for everyline otherwise this won't work). And ## is the record number you want to read (ie line number). And LUN is the LUN you want to use for your file (don't forget to close it at the end). Then to find a max, simply read each record 30k - 35k and do a simple check to see if the just read value exceeds your current max (held in a different variable). If is is too hand-wavy, let me know and I can code something up this weekend. edit: If the line lengths aren't consistent you'll have to resort to a stupid styled loop that reads every line, and skips to the next line when you are below 30k and bails out of the loop at 35k.
|
|
#
¿
Jun 11, 2008 23:26
|
|

|
At work there is a problem with a printer. Basically when I try to print to it there are particular colors that will not work (specifically if Red is at 1.0 and Blue and Green are some combination of 0.0 or 1.0). Instead of trying to track down the bug in this stupid host-based driver I have to use, I was thinking it would be possible to write a small program to fix this (basically search and replace the bad colors to something that will print). Since I primarily need to print postscript files, which are plain-text documents, this seems like it should be straight forward. However I've got no real experience with Postscript. Is writing a filtering type program here really as simple as my mind thinks it is?
|
|
#
¿
Jun 13, 2008 22:03
|
|
|
ShoulderDaemon posted:Postscript is a turing-complete programming language. You can't, in general, programatically replace some colors with others. Hmm... So it seems that it might be a little more complicated than I had hoped. But what I do have going for me is almost all of the files I need to print are generated from the same program which should mean that it will use colors in a uniform manner (It is output from IDL). So I guess I'll make sure to check that it was created by IDL first (which is conveniently a comment at the top) and then proceed to replace colors with how IDL sets things up. Hopefully that will allow it to become doable without writing a whole Postscript interpreter. Of course this isn't ideal, but it sounds better than manually printing ~1000 files by copying them to another computer and printing them one by one (and then doing that same process whenever I have something to print). edit: I just had a potential idea. Since Postscript being Turing complete is the big problem, would it be reasonable to leverage that by inserting some postscript code into the file that changes the colors? 6174 fucked around with this message at 23:16 on Jun 13, 2008 |
|
#
¿
Jun 13, 2008 22:53
|
|
|
Emo.fm posted:Quick, probably embarrassing, only tangentially programming related question. I'm using X11 on a Mac to ssh to a server for work, and I need to get a .zip file from said server. I can find the file on that server just fine, but how can I copy it from there to my computer? I've tried using the cp command with a destination path on my computer, but that doesn't work and I didn't really expect it to... Any ideas? Have you tried using scp or sftp on your local machine? ie scp user@remote:/path/to/file localfilename
|
|
#
¿
Jul 10, 2008 00:15
|
|
|
Nahrix posted:(Language: C) Is there a simple way to read a char array[x] -> array[last_element], where y > 0? Nahrix posted:I just want to read a string, starting from a given index. (eg. read "ello" from "hello"). I don't want to make a for loop for this. Also, there is a C/C++ thread for questions like this.
|
|
#
¿
Nov 4, 2008 22:08
|
|
|
My brain is being dense right now and I'm having problems getting gfortran to link to a library. I know that I have the library I'm trying to link to: /usr/lib/liblapack.so.3.0 (has a symlink pointing to it at /usr/lib/liblapack.so.3) It successfully links if I do the following: gfortran -o program /usr/lib/liblapack.so.3 filename1.o filename2.o .... I am used to linking to a library by using -l, so something like gfortran -o program -llapack filename1.o ... (potentially with the -llapack at a different location on the line, I normally let a build system take care of this so I don't remember the exact placement) However this second version always produces the following error: /usr/bin/ld: cannot find -llapack I'm using 64-bit Ubuntu Linux, ld 2.18, gfortran 4.2.1, and LAPACK comes from the packages lapack3. What do I need to do to get so that I don't need to specify an absolute path to the library? The program is normally built with GNU Make and built on lots of different systems so relying on an absolute path for a library isn't an option.
|
|
#
¿
Dec 11, 2008 22:57
|
|
|
No Safe Word posted:If it's anything like gcc/g++ you just need to put the library path after a -L option: gfortran is very much like gcc/g++ since it is also part of the GNU Compiler Collection (The gfortran info page even tells you to read the gcc info page for the language independent options). However I still get the error. code:
|
|
#
¿
Dec 12, 2008 00:12
|
|
|
simux posted:Try symlinking liblapack.so to liblapack.so.3. I seem to remember that ld only maps -lfile to libfile.so. I could be wrong but that's the first thing I'd try. That works. It allows just -llapack to find the library. This brings up a related question. If ld simply maps -lfile to libfile.so, then why is it that quite a few of the libraries I've got in /usr/lib do not have a .so variant? Many of them are named libfile.so.# for some number #. But there are also quite a few that have a .so symlinked to the .so.# version. Presumably with as many libraries that have this, the Ubuntu packagers didn't botch this many packages, so I'm missing something. I do see that if I run ldd on the executable, it points to liblapack.so.3. Does this mean that a .so symlink is only needed if you are linking to a specific library, and since most people aren't doing that (at least using ld), the .so symlink isn't needed and thus the package maintainers don't put it in?
|
|
#
¿
Dec 12, 2008 00:56
|
|
|
floWenoL posted:It's been a while since I've worked with Linux packaging, but I believe you won't get the symlinks unless you have the package <FOO>-dev (or similar) installed. At least according to the Debian Policy Manual that is correct. Thanks for the clarification.
|
|
#
¿
Dec 12, 2008 18:36
|
|
|
I've got a problem and I'm not sure of the best way to proceed. Basically I've got a flat file database that I need to ensure is in the correct format. It is a high-resolution molecular absorption database, so it basically has information saying that at a specific wavenumber, a particular molecule has a set of properties. This database gets used to provide a priori estimates and so forth when running simulations and the like. Each line is a fixed width, and basically in a fixed Fortran format. They all follow the same general format, ie the first three characters specify the molecule and isotope, next ten specify the wavenumber etc. There are also variable fields whose format depends on the molecule/isotope of the line. There are also lots of exceptions. I have a working C++ prototype, but it is going to become an unmaintainable mess if I continue with it in its current direction. Right now it is progressing line by line. It breaks the line up by substrings, and by what amount to large switch statements it determines the format that each of the substrings should be. Each substring/format of substring is passed off to a subroutine that validates the substring based on some work I did going backwards from some DFAs based on Fortran FORMAT statements. What I would like to do is get the format out of the program itself, and have that be separate text file, particularly since there are a couple formats this database could be in. That way I can add exceptions and new formats more easily. What should I be looking at to do this? Would it actually make things maintainable? Speed is also a bit of a concern. My prototype goes through 1.73 million lines in about 6.75 minutes, and in different situations could be asked to deal with up to 2 million lines. However, maintainability is much more of a concern than speed since these validations aren't too frequent. I'm also willing to move to a different language if it would make the process significantly simpler/easier. Edit: The level of errors that need to be reported are along the lines of saying "X field of Y line failed". 6174 fucked around with this message at 19:21 on Feb 5, 2009 |
|
#
¿
Feb 5, 2009 18:48
|
|
|
rjmccall posted:Your external specification idea sounds like it will inevitably become a domain-specific parsing language. You really, really don't want to write one of those; That is what I expected, and you're right, I don't want to write one which is why I made the post in the first place. And no, unfortunately the format isn't context-free (or at least if it is, I don't see how). rjmccall posted:However, unless these subfields are very complex, I think you could just write a very simple stream parser, which really can be quite efficient and maintainable if you design it properly. I think this will work better than what I'm doing right now. Eventually I need to add checks along to the lines of if you see a line with a set of properties that means there must be a mate to it with a similar set of properties. But those checks are much more specific and only need to be run on a subset of say 100k of the lines instead of the whole thing. They should probably be separate programs or at least a second pass through the file after the format has been validated.
|
|
#
¿
Feb 5, 2009 20:08
|
|
|
rjmccall posted:Unless you're dead-set on performance � and you said you weren't � I would write this parser as if you were really going to use all the data in the file; My main concern would more be memory usage. Most of the lines are going to need inter-row comparison (sometimes set of rows too). I also wouldn't necessarily be able to discard lines from comparison until the file is completely read. Since we're talking a couple million rows (the version of the database in beta form right now is about 2.09 million), it would seem to me that unless I very carefully manage memory here I could easily consume so much that I'd waste a lot of time swapping to/from disk. Of course I could be mentally overestimating the memory usage. edit: A little more info on size here if someone is willing to sanity check my memory estimate: Each line is 160 characters in length, containing maybe 20 parameters, of which 4 are variable format. Each one of those variable parameters is 15 characters in length and can feasibly be expected to store another 15 parameters each (though none are quite that high yet). There are about 30-35 molecules, each with between 1 to 6ish isotopes. The format is generally dictated by molecule, but there are a couple where each isotope has its own format. All told there are about 100-150 distinct line formats including the various exceptions to the standard rules. Also the development machine I've got only has 1 GB of memory (with no funding to increase it anytime soon). In plain text format the database is already 323 MB (for the 2.09 million line version). 6174 fucked around with this message at 21:40 on Feb 5, 2009 |
|
#
¿
Feb 5, 2009 21:24
|
|
|
rjmccall posted:You still use a constant amount of memory this way, but it makes it easy to decide to keep things around, and you don't have to rework your parser to do so. Ahh, I understand what you are saying now. I thought you were saying I whould only parse a line once ever and apply all the inter-row checks based on that single parsing, which led my thinking to the potential memory problem. I can restrict the inter-row comparisons a lot by saying that all inter-comparisons will always be dealing with at least the same molecule if not isotope. These subsets are then on the order of like 100k-200k for the larger ones, which is definitely feasible to store in memory. What I can't say is where the elements of these subsets are in the file since it is not sorted by molecule. In fact there isn't a fixed sorting of the file (it is sorted by wavenumber, but two lines can have the same wavenumber and how those are inter-sorted is not specified and varies through the file). I'm thinking at this point it might be the simplest to have the initial parse validate the format and then write out the rows to temporary files based on molecule/isotope. Then for the inter-comparisons simply read in the temporary files using the same parser and conduct the checks based on the second parsing. That way at no point should I be trying to store too much in memory at once and the flow of the program should still be comprehensible enough that someone with only basic programming skills would be able to use/modify later if need be.
|
|
#
¿
Feb 5, 2009 23:57
|
|
|
rjmccall posted:I would strongly suggest using a relational database for this work if possible, instead of temporary flat files. Postgres is quite good for being free, and it really does have very efficient algorithms for processing large quantities of data within the limits of available memory. I understand your sentiment, but unfortunately there is no way that would fly with my boss. This program is step one of putting this flat file database into a relational database (and the data doesn't go well into a relational model anyways). The goal there is to have tools that takes the existing flat file database, convert it to a relational database, and also have the tools to export to existing formats since there are a lot of existing programs written by others that depend on the flat file format. This parser will be used to verify that the output is correct, and hammer down the format of the flat file since the documentation about the database is incomplete and inconsistent. I also have to keep the requirements of the tool relatively simple since it will almost certainly be distributed to people who have a technical upper limit of typing make. Those that can go further only know Fortran and would never trust a tool that used a database as an intermediary step (they would assume it is wrong since they are superstitious when it comes to computers).
|
|
#
¿
Feb 6, 2009 00:32
|
|
|

|
| # ¿ Apr 28, 2024 22:15 |
|
|
Avenging Dentist posted:Why not do both and use SQLite? I'll have to read up on SQLite, but assuming I don't hit a wall on total memory usage when creating the temp files to begin with, that seems like a good option. Also, thanks for the help rjmccall, you've certainly saved me from banging my head on the wall a few times if I had gone with my original thoughts.
|
|
#
¿
Feb 6, 2009 02:12
|
|