


|
optikalus posted:Well, my "SAN" has just turned itself into a pile of crap. I'm an employee of NetApp and I can try to put you in touch with someone more responsive if you're still interested.
|
 #
¿
Nov 10, 2008 23:21
#
¿
Nov 10, 2008 23:21
|
|


|

|
| # ¿ Apr 27, 2024 15:38 |
|
|
Maneki Neko posted:I think you might needs the CIFS license if you plan to also use snapdrive on the windows hosts, but I could be wrong. A. No. SnapDrive no longer requires a CIFS share for the host to access the storage system volumes. And... Minimum required version of Data ONTAP: 7.1 Table of licenses you need, depending on what you want to do. code:
|
|
#
¿
Nov 19, 2008 22:33
|
|
|
Mierdaan posted:Is there a good online resource for finding out what Netapp's different software licenses actually allow you to do? Their online doc on SnapDrive is horrible, horrible marketing garbage. Unfortunately the only good source is the NOW support site. What would you like to know?
|
|
#
¿
Nov 20, 2008 22:54
|
|
|
Wicaeed posted:Can someone explain to me how Netapp does their licensing? I bought these F720 filers but I'm having some issues getting it to run properly (which isn't related to licensing), but I've read a blog where if you don't have the right license to run a specific software (NFS/CIFS) the thing is pretty drat useless anyways. Can you describe your problem in more detail? Also, please post the output to "license" on the CLI.
|
|
#
¿
Dec 11, 2008 20:25
|
|
|
Unknown may be right. code:I can send you the field service guide if you give me an email address. The NVRAM card is located in slot 9.
|
|
#
¿
Dec 11, 2008 23:14
|
|
|
NetApp has had something called System Manager out for a couple months now. It's meant as a Filerview replacement. It's also free and you can download it from NOW. For more info click here: http://blogs.netapp.com/storage_nuts_n_bolts/2009/03/sneak-preview-netapp-system-manager-nsm.html You'll need mmc 3.0 and all your snmp ports to your filers open. I can't comment on its reliability because I've never used it though. The 2000 series filers are all clusterable btw. In fact, I've only ever come across one customer that bought a 2000 series with one node. With respect to expandability, the 2020 can be expanded with FC or SATA shelves. This is rather odd because the 2020 is populated with SAS drives. Also, last week NetApp released Ontap 8, Ontap 7.2.3, the 2040 and the DS4243 SAS shelf. The big deal with Ontap 8 is that it supports aggregates bigger than 16 TB.
|
|
#
¿
Sep 6, 2009 19:59
|
|
|
lilbean posted:Oh absolutely. My last big order was six Sun T5140 systems and a couple of J4200 disk arrays for them, and our CDW sales rep was falling over himself to get us to order it by the end of the month (in January). He called me twice a day to check on the status and what not, and then I finally e-mailed him to tell him to calm down. That's appalling. It's common for sales cycles to last 6 months in the storage industry. In fact, the cycle often stretches beyond 6 months and not just for high end arrays.
|
|
#
¿
Sep 16, 2009 22:08
|
|
")
|
1000101 posted:I think NetApp GX may address this particular need. Ontap 8 running in "classic" mode overcomes the 16 TB aggregate limit. http://www.ntapgeek.com/2009/09/64-bit-aggregates-in-data-ontap-8.html GX or cluster mode as it is known in ontap 8 has several limitations, including an inability to snapmirror. namaste friends fucked around with this message at 20:57 on Sep 20, 2009 |
|
#
¿
Sep 20, 2009 20:55
|
|
|
adorai posted:On our NetApp 3140, when running the command: priv set diag; stats show lun; priv set admin Are you using Operations Manager? If so, can you create a graph for iSCSI latency? That should tell us how well your iSCSI SAN is performing. When you created your iSCSI LUNs, did you use snapdrive or did you create them manually? If you created them manually did you remember to align the VMFS formatting? Also, do you have the ESX host utilities kit installed?
|
|
#
¿
Jan 3, 2010 07:05
|
|
|
Serfer posted:This might not be the right crowd, but any idea how something like a Netapp box has a pool of drives which are connected to the two head units? They can assign which drives go to which in software as well. The only solutions I can come up with involve a single point of failure (eg, using a controller and serving up the drives each as their own LUN to the heads). If you're asking what I think you're asking, it works like this; with ONTAP 7 and above, the disks contain metadata written at the RAID level which assigns the disks to their respective controllers. This is called software disk ownership. Generally in NetApp clusters which are described as "active/active", each node owns some portion of the disks. During normal operation, i/o is written to the NVRAM and shared to each node through the cluster interconnect. Once the NVRAM is full for a node the data is then written to disks which it owns. In the event of a failover, the node which has "taken over" its partner's disks can continue serving data and writing data to its partner's disks, all thanks to the magic of software disk ownership. In the old days of hardware disk ownership, each node in the cluster owned disks plugged into a specific HBA port/loop on the filer. With software disk ownership, it doesn't matter what loop is plugged into where as ownership only depends on the RAID metadata written to the disk. I've seen systems where disk ownership is scattered all over the stacks of disk trays.
|
|
#
¿
Mar 7, 2010 20:54
|
|
|
H110Hawk posted:Via magic, faeries, pixie dust, and most importantly lots of money. Just wanted to add that all of NetApp's current product line, except for the 6000 series have interconnects on a circuit board backplane.
|
|
#
¿
Mar 7, 2010 20:58
|
|
|
Serfer posted:Well, I was trying to figure out how they had drives connected to both systems really. I wanted to build something similar and use something like Nexenta, but it's looking more like these things are specialized and not available to people who want to roll their own. Hmm sorry I can't help you there.
|
|
#
¿
Mar 7, 2010 21:53
|
|
|
Serfer posted:Yeah, that's pretty much where it's going. 100% overhead. But still cheaper that way than buying Netapp or EMC. Which reminds me, despite calling a half dozen times, and having a conference with Sun, they never sent me a quote despite promising that it would get there in x<7 days every time I called. I would imagine Sun staff are busy trying to find new jobs right now.
|
|
#
¿
Mar 7, 2010 22:29
|
|
|
Insane Clown Pussy posted:What the hell is up with NetApp's pricing? Their "Windows bundle" that includes the VSS-aware snapshot tech is $3k per controller on the 2020 or $16k per controller on the 2040 for the exact same feature-set. I was leaning towards EMC until their AX4 pricing doubled when they added the VSS software. At this rate we're either going to go for Equallogic or bite the bullet and get some more HP/Lefthand boxes. Compellent are dropping by next week though, so we'll see what they say. Do those prices include any disk?
|
|
#
¿
Mar 28, 2010 05:26
|
|
|
Cyberdud, I think you may want to go through the following exercise: 1) figure out how much it will cost your company per hour of down time 2) figure out what your company's tolerance is for down time, given the cost You need to have a conversation with management about the managey, business stuff like this because ultimately you need to be accountable for your design decisions. Finally, you need to document this stuff. It sounds like you work for a pretty small shop and you guys may be pretty informal about decisions like this, but I can definitely tell you that this exercise is worth performing. Not only that, future employers would consider this sort of exercise positively in your favour. Also if the whole set up blows up in your face you can pull the report out and show it to management and tell them why you made the decisions you did.
|
|
#
¿
Apr 25, 2010 04:15
|
|
|
FISHMANPET posted:Anyone know a good way to get a Mac to connect to an iSCSI network? There are software initiators, but our Xserve is a piece of poo poo, and I'd rather just get a dedicated card. Does anybody make a card with OSX drivers? I know QLogic doesn't (at least according to their site). Apple seems to be all on board the Fibre Channel bandwagon, and ignoring iSCSI. Why not just use NFS? edit: Generally speaking, TCP offload engines don't give you that much advantage over using a dedicated NIC. If you've got a good amount of RAM in your Mac, it's more trouble than it's worth. namaste friends fucked around with this message at 20:16 on Jul 15, 2010 |
|
#
¿
Jul 15, 2010 20:10
|
|
|
FISHMANPET posted:RAM, Hahahahahahaha. Like I said, our server is a POS. I think it only has 3 GB. The guy who was paying for it wanted to be a cheapass, and my boss didn't have the balls to tell him to gently caress off, so we turned everything down to -11. We've got like 10T that we can share out via NFS from our thumper, but it's being a bastard in OSX. We were trying to use NFS reshares and that just sucked. Our next step is to try and get each client to mount the NFS share directly from our thumper, instead of from the Xserve. What kind of data is stored on your thumper?
|
|
#
¿
Jul 15, 2010 22:08
|
|
|
GanjamonII posted:Does anyone here run oracle on iscsi? we're having some performance issues. Is this a new oracle install? Are you using snapdrive? What initiator version? How have you configured your target NICs on the filer? Are they vif'd? What ontap and snapdrive versions are you running? What oracle version? Are your servers clustered? How complicated is your networking? ie multiple vlans? Misogynist and Adorai asked very good questions about your network. I'd also take a look at basic stuff like duplex and autonegotiate on the switches. Finally, have you opened a case? If not, I suggest you do so now. You're paying for support anyway. Might as well use it. This sort of problem is well within the responsibilities of the support centre.
|
|
#
¿
Jul 29, 2010 06:50
|
|
|
Misogynist posted:Anyone know the standard log write size for Exchange 2010, perchance? I know the DB page size was increased to 32k, which actually makes it possible to run on RAID-5 in our environment, but I can't find anything about the transaction logs. From here: http://technet.microsoft.com/en-us/library/bb331958.aspx quote:If a database suddenly stops, cached changes aren't lost just because the memory cache was destroyed. When the database restarts, Exchange scans the log files, and reconstructs and applies any changes not yet written to the database file. This process is called replaying log files. The database is structured so that Exchange can determine whether any operation in any log file has already been applied to the database, needs to be applied to the database, or doesn't belong to the database.
|
|
#
¿
Aug 6, 2010 08:01
|
|
|
ghostinmyshell posted:Also don't be afraid to open a case with NetApp, they don't mind these kind of cases if you think something is weird as long as you act like a reasonable human being. I'd like to emphasize this post. You are probably paying a lot of money to keep your equipment within support. Use it!
|
|
#
¿
Aug 12, 2010 18:53
|
|
|
adorai posted:i always see how many nics people use for iSCSI and wonder, are they going overkill or are we woefully underestimating our needs. We use 3 nics on each host for iscsi, 2 for the host iscsi connections and 1 for the guest connections to our iSCSI network. We have 6 total nics on each of filers, setup as 2 3 nic trunks in an active/passive config. We have roughtly 100-120 guests (depends if you include test or not) and don't come close to the max throughput of our nics on either side. It's worth your while to install Cacti or Nagios somewhere to monitor the switches your filers are plugged into. Are we talking about NetApp filers here? If so you can also check autosupport for network throughput graphs.
|
|
#
¿
Aug 12, 2010 18:57
|
|
|
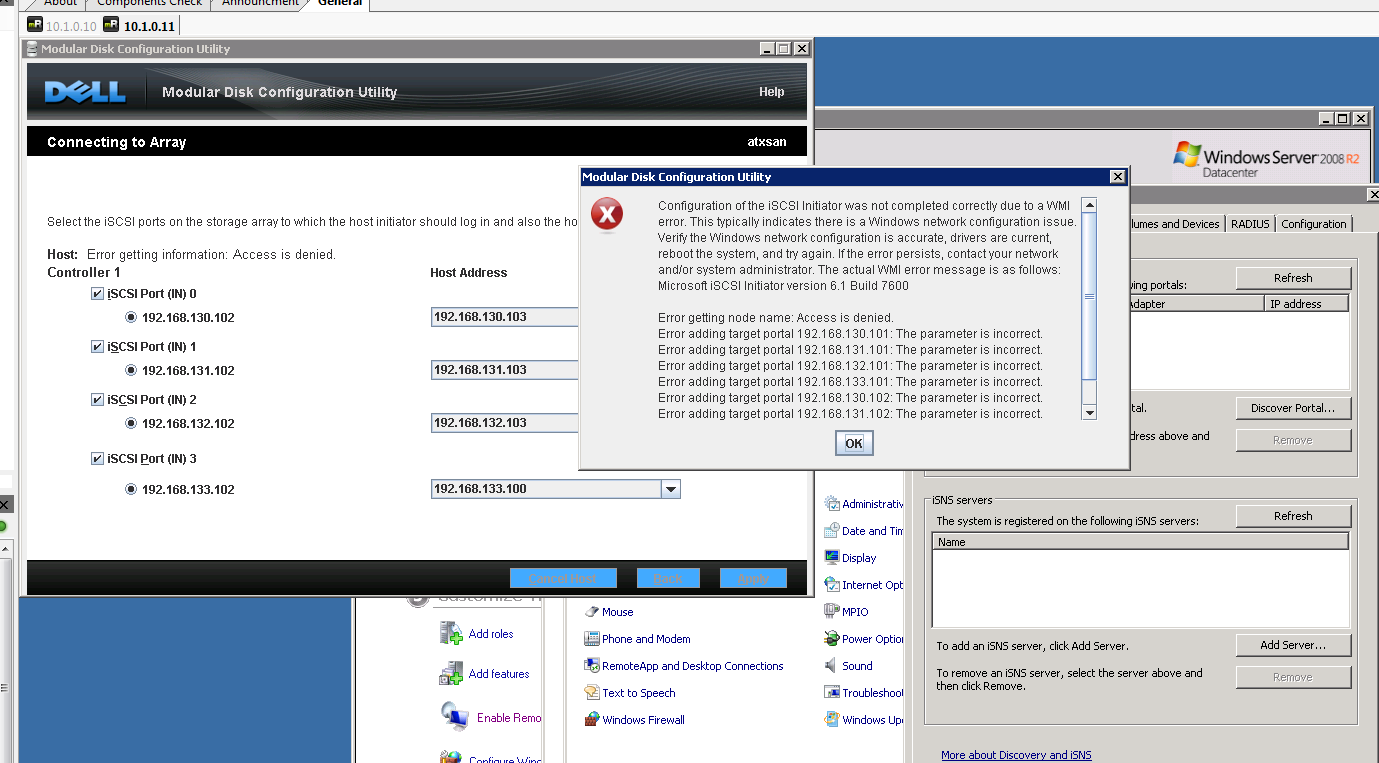
vty posted:Alright, I'm completely stumped and need some assistance, this has been a major headache. Is your Dell storage device a member of the same Windows domain as your server? As well, do you see anything in your event logs? edit: I'm reading through this manual: http://www.google.co.uk/url?sa=t&so...N4O4y6nS-mr7quA Have you gone throught the host access configuration stuff on page 43? namaste friends fucked around with this message at 15:29 on Aug 14, 2010 |
|
#
¿
Aug 14, 2010 15:10
|
|
|
Eyecannon posted:Building a new fileserver, would like to use ZFS, but I would rather use linux than solaris... is this legit now?: http://github.com/behlendorf/zfs/wiki And while we're at it, what's the difference between ZFS on linux and btrfs?
|
|
#
¿
Aug 23, 2010 23:22
|
|
|
Intraveinous posted:Any recommendations on RAID controllers for a small array of SSDs (4-6). Will be in either Raid 10 or RAID 5/6 if the controller is good enough at it. Read heavy database (95%+), so R5/6 write penalty shouldn't be too big an issue. That's impressive! What's your rationale for RAID10? What's the database?
|
|
#
¿
Aug 31, 2010 18:42
|
|
|
Is anyone out there looking at 10GbE?
|
|
#
¿
Sep 21, 2010 21:44
|
|
|
Reading all these posts about people aggregating 6+ ethernet ports together, I was curious if anyone had thought about using 10GbE instead.
|
|
#
¿
Sep 22, 2010 19:42
|
|
|
oblomov posted:Our 2U VMware servers each used to have 8 cables (including Dell drac) and now we have 3. Is that 3 10GbE interfaces? I'm curious about how people are using 10GbE with esx.
|
|
#
¿
Sep 24, 2010 07:34
|
|
|
conntrack posted:It got unmounted ok, double checked in the logs. The restore deleted about 60% of the files before i called it quits for taking to long and remounted it. What version of ontap and snapdrive are you using? edit: Try your test again but with the following snapdrive restore command: snapdrive snap restore /mnt/goon -snapname goon_snapshot -vbsr preview https://now.netapp.com/Knowledgebase/solutionarea.asp?id=kb47140 The default behaviour for snapdrive restores is single file snap restore. The -vbsr flag will tell snapdrive to do a volume based snap restore. namaste friends fucked around with this message at 23:18 on Sep 24, 2010 |
|
#
¿
Sep 24, 2010 22:59
|
|
|
three, this is an oracle db right? Has anyone run an oracle statspack to see that the Oracle db isn't doing anything funny? edit: Oracle Statspack: http://download.oracle.com/docs/cd/B10500_01/server.920/a96533/statspac.htm A quick and very very dirty analyser for a statspack: http://www.txmemsys.com/statspack-reg.htm This analyser is tuned for performance on SSD but still provides useful information for Oracle tuning newbs. namaste friends fucked around with this message at 04:59 on Oct 20, 2010 |
|
#
¿
Oct 20, 2010 04:49
|
|
|
ferrit posted:Is there any way to increase the write performance on a NetApp FAS3140 running OnTap 7.2.6.1? It appears that our options, according to NetApp support, are: 7.3.x has significant performance improvement over 7.2.x. Ontap 7.3.x was written to take advantage of multiple core filer heads by running more threads to take care of background processes. I'm surprised support didn't mention this to you. Is it possible for you to upgrade ontap?
|
|
#
¿
Nov 20, 2010 01:50
|
|
|
madsushi posted:SMB2 is in 8.0.1, but not SMB2.1, which I guess Windows 7 is capable of. For everyone that has access to NOW, here's the release notes: http://now.netapp.com/NOW/knowledge/docs/ontap/rel801rc2/html/ontap/rnote/frameset.html
|
|
#
¿
Nov 28, 2010 18:58
|
|
|
idolmind86 posted:Two questions... Sometimes I run into clients that use NFS without any consideration for the type of workload they require. That is you end up seeing them mount up their exports without putting in the right options. The problem is that databases treat the filesystem differently than conventional applications. Oracle is an example that has intimate knowledge of filesystems, particularly local filesystems. Sometimes this results in some pretty messed up performance over a NAS protocol like NFS. One way of overcoming this problem is to get rid of NFS and use FC or ISCSI. Another way is to simply tune your NFS options to suit your database workload. What follows below is a crib of a NetApp techinical report (TR3322, get it here: http://media.netapp.com/documents/tr-3322.pdf ) . I want to try and explain what NetApp considers to be problems with respect to configuring NFS to suit a database workload. There are 4 considerations in using NFS instead of a local filesystem to store your database. 1) Data Caching Mechanisms 2) Data Integrity 3) Asynchronous I/O 4) I/O pattern With respect to 1) Conventional file I/O doesn't have a facility to deal with the caching of data. The file system will have a mechanism to cache data to reduce I/O. On the other hand, a database is likely smart enough to have its own caching mechanism. This presents a problem where it may be possible that a 'double' caching effect can occur which is undesirable. 2) File systems will often defer the writing of data to disk until some point in time as determined by the operation system. Sometimes databases require that data is immediately written to disk to provide data integrity. The deferral of writes (known as write back) to the file system can cause unwanted latency to the db. 3) Asynchronous I/O (AIO) is a feature of an OS that enables your application to continue processing while the file system I/O requests are being serviced. AIO is relevant to databases because they can control their read-ahead and write-back behaviour. Read-ahead and write-back behaviour are intimately intertwined with AIO. 4) I/O patterns of databases, particularly online transactional processing, are generate a high amount of small, random, highly parallelized reads and writes. NFS performance improvements (as far as I'm told anyway) have neglected this sort of workload. So what do you do about this? Without knowing what your proprietary database does and how it works, I would suggest generating some sort of workload and then benchmarking the I/O when it is run against local attached storage. Then I'd suggest running the same workload and benchmark against ISCSI and FC attached storage. Finally, run it against NFS mounted storage. If you think you're seeing problems with performance which may be related to any of the above problems, the next step is to start playing around with your mount options. The problem with this is that you could be playing around for a long time and the options you end up using depend on the OS and version. Maybe taking a look at NetApp's NFS options for Oracle might provide a starting a point: https://kb.netapp.com/support/index?page=content&id=3010189 . On Solaris it's possible to mount an export with forced direct io - forcedirectio, no attribute caching - noac. As far as I've seen, lock problems generally arise when something is interrupting the network or communication with the storage device. There's no easy way to deal with this but take a look at the nointr option. I believe Veritas is usually referred to as VxFS.
|
|
#
¿
Nov 30, 2010 04:44
|
|
|
what is this posted:Just use iSCSI for your database, that's what it's meant for. While I think your approach has merit, I've done work with a significant number of clients (national utilities, oil & gas, investment banking) that use NFS with Oracle. I think there's a lot of problems with any particular protocol you use and it just depends on the amount of time and energy you're willing to dedicate to solving the problem that makes sense in your choice in the end.
|
|
#
¿
Nov 30, 2010 04:47
|
|
|
toplitzin posted:Woohoo! I just made it through the third round of interviews for NetApp support. I asked them some areas of study to try and brush up on. The rep suggested looking into LUN's, mounting and configuring exchange, maybe a little mild SQL, but really stressed the LUN-NAS/SAN side. Any suggestions? Congratulations on making it this far. I'd suggest spending some time to review networking, particular anything that you think would aid in troubleshooting network problems. Any NAS implementation I've come across has always been delayed because of misconfigured networks. I always come across misconfigured VLANs, dns problems, firewalls tightened up like fort knox and routers sending traffic across ISLs. Have you ever used wireshark? It might be worth thinking over how you would use wireshark to solve any of these problems. Are you sure the third interview will be tehcnical?
|
|
#
¿
Nov 30, 2010 04:53
|
|
|
adorai posted:Ultimately it is probably a matter of preference, unless the storage vendor provides tools for snapshot management like NetApp does. One thing to consider is that using the default block size of 1MB in a VMFS volume, the maximum VMDK is 256GB. This means if you will need more than that you will need to either use iSCSI luns directly attached to your guest, or you will need to use multiple VMDKs with windows combining the disks into a single volume. On our WSUS servers we use iSCSI luns connected to the guests. How big do WSUS repositories get these days anyway?
|
|
#
¿
Dec 9, 2010 02:26
|
|
|
If the size of a windows patch that you push out is smaller than the read cache on your NAS, it's probably not going to make much difference what block size you specify. The best thing to do, if you're really worried about performance is to try both block sizes and run some benchmarks on them.
|
|
#
¿
Dec 9, 2010 04:45
|
|
|
Misogynist posted:We're talking about VMFS block sizes, which has implications far above and beyond (and irrelevant to) the NTFS cluster size. Ah, gotcha.
|
|
#
¿
Dec 9, 2010 16:38
|
|
|
what is this posted:You keep ignoring the posts telling you to use a SAN. Why is this? Respectfully, I think you're oversimplifying the problem. As a vendor, idolmind's company is going to have a tough time trying to tell his clients to throw out their NFS infrastructure because they don't support it. If his company's competitors do support NFS, it might result in a lot of lost sales. As I've stated in a previous post, it might be worth looking at tuning NFS mount options based upon the performance profile of the application. At the moment I can think of at least 2 large corporations that would make it difficult for idolmind's company to make a sale if someone were to state that the application only supported block storage protocols.
|
|
#
¿
Dec 21, 2010 00:31
|
|
|
adorai posted:If they will only provision storage as NFS from whatever device they have, the solution is simple: use an opensolaris/openindiana/openfiler/plain old linux VM stored on NFS that presents that storage as iSCSI. Problem solved, cost: $0 and the storage admin doesn't know any better. I can appreciate that someone as astute as yourself can develop a multitude of workarounds to accomodate a requirement for block storage. However, from a manager's point of view, particularly one that is evaluating your solution as part of an RFP, would you consider this an acceptable solution in comparison with other application that may support NFS? As an account manager working for idolmind's company, would you even entertain it as a proposal?
|
|
#
¿
Dec 21, 2010 00:54
|
|
|

|
| # ¿ Apr 27, 2024 15:38 |
|
|
adorai posted:I'm not sure how it is any more of a 'hack' than trying to run a database off of NFS. I know of at least two large telecoms/outsourcers that standardize their oracle databases on NFS. One of these telecoms runs the billing system for a national utility company using 10 GbE with NFS.
|
|
#
¿
Dec 21, 2010 03:45
|
|