


|
The Vosgian Beast posted:I'm not British so I'm probably missing something. Oh, I know this one. It comes from Making Beliefs Pay Rent. See, Christians with their unfalsifiable beliefs in unobservable things are doing it badly, because they don't act like they believe the things they say they believe. Although they pay lip service to Mark and Luke saying that Christians can handle poisonous snakes without being bitten or Christ's statement that you can literally move a mountain with faith, they don't try to do these things: they run away from deadly snakes and drive through tunnels, like everyone else. People who believe in the unfalsifiable unobservable Cthulhu memeplex, however, definitely act like they believe the things they say. They expect opposition to their ideas in popular culture, they are not surprised when people revile them or call them insane; put simply there is no gulf between their professed beliefs and their actions. A LessWronger will say that there's no difference between the Cthulhu memeplex and gravity: both act invisibly but produce predictable effects. A more astute LessWronger will conclude by saying that there's also no difference between the Cthulhu memeplex and phlogiston: they both do an excellent job predicting observed behavior but provide no novel insights.
|
 #
¿
Oct 2, 2015 21:27
#
¿
Oct 2, 2015 21:27
|
|


|

|
| # ¿ May 10, 2024 04:35 |
|
|
The Vosgian Beast posted:loving faithtards Well, yeah, obviously the stupid ones will just ignore the fact that their opinions conflict, and the marginally less stupid ones will go "  grey tribe signalling ", but the question of why stupid people join cults is boring compared to the question of what mental backflips otherwise-apparently-intelligent people use to justify their phyg membership. grey tribe signalling ", but the question of why stupid people join cults is boring compared to the question of what mental backflips otherwise-apparently-intelligent people use to justify their phyg membership.That's why I like mocking LessWrong so much: not only are they mostly intelligent people, they also worship the concept of intelligence, and so their mental backflips have to be more intricate.
|
|
#
¿
Oct 2, 2015 23:17
|
|
|
Dapper_Swindler posted:so what exactly is their angle(besides being bigots)? that he didn't "invent" the clock he only built one? that seems kinda of horrifically petty. Basically they're saying that disassembling a mass-produced item and putting it in a different box is not that interesting, even for a kid, and nobody would be pretending to care if it weren't for the political angle. Which, while obviously true, neglects that the political angle is important. Personally I think they're mostly racists, but they might also be doing that nerd thing where they disclaim all politics as evil intruders in the noble life of the mind (except when doing so would disadvantage them).
|
|
#
¿
Oct 6, 2015 00:36
|
|
|
Merdifex posted:I'm also sure Rev thinks of himself as a "freak", but all he's created is that stupid catchphrase. Is he denying that there are progressives who created anything, or is he limiting the scope of this somewhere? Artists are among the most progressive class of people I know. In fact I would describe roughly 90% of the people I work with as progressive (is that what "prog" is? These people really love their cryptolect). A few of us are also freaks, but the people I'd describe that way are the most progressive of all of us. Probably we don't count as creating for complicated handwavey reasons designed to direct attention away from Rev's position being an unsupported and obviously false statement, phrased to sound clever without any real meaning. What does Rev do? Does anyone know? It would just be really funny if he was another one of those people who only produce blog posts. It would be even funnier if he were a programmer. I get the feeling I've now put more thought into this than he did.
|
|
#
¿
Feb 12, 2016 06:47
|
|
|
Cingulate posted:Also I want to repeat that I'm not a statistician, mathematician, computer scientist or ML researcher. I'm working on cognitive neuroscience, usually of language, and that field is using a lot of ML tools as of recently. So this is basically just the perspective of a layman who's trying to apply these methods. I wanted to chime in and say thanks for your posts, you're dead on. I wish more laypeople had the same knowledge that you do. Your image of common ML algorithms on different classification tasks was an especially great find. I just finished giving a tech talk to a bunch of college students, and I thought the summary might be a useful bit to append to your posts. I summarize the talk with: "Although AI is incredibly powerful, it's usually less powerful than we intuitively feel it should be, and for any nontrivial task you will always find that your intuitions are overestimating the strength of an AI system, and underestimating the difficulty of the task that that system performs." Basically, if you're a layperson who doesn't interact with ML (or other AI techniques) much, I cannot stress enough Cingulate's point that it's so easy to get started. Aside from the resources they linked, you might appreciate Caffe, which is a deep neural net framework which is mostly used with ImageNet, an image-classifying system. All you need is access to a linux box; Amazon will happily rent you one for cheap. Here's the page which provides the list of models they have pre-trained, so that you don't even need the graphics card Cingulate mentioned: http://caffe.berkeleyvision.org/model_zoo.html.
|
|
#
¿
Feb 15, 2016 08:08
|
|
|
Cingulate posted:Like, they'll catch up on some of the flashier findings - Google artificial brains can now paint like Monet! And if you don't understand ML, you assume they're doing that in a similar manner to how a human would do that, so you assume AI is is approaching human-like performance. But this is false. At its heart, the part of AI that really works right now would not be completely misdescribed by calling it "fuzzy statistics", and that means it's really good at something humans fail at (due to, e.g., the cognitive fallacies Yud knows from Kahnemann), and really terrible at stuff humans are great at. "Fuzzy statistics" is a great description of reinforcement learning (like what Google used to make its AI beat those old Atari games), or UCT / Guided Monte Carlo approaches (like what Google used to win Go). I still don't love the phrasing; I feel that it removes a bit too much nuance. For instance, machine learning as a field is probably better described as "naive but powerful pattern finding", and non-ML computer vision is "a pile of simple algorithms mixed with heuristics that work astonishingly well". There's a lot of work in AI that I don't feel is captured by that description. Is there some place I can go to talk about this? I keep making GBS threads up Yudkowsky threads with AI pedantry.
|
|
#
¿
Feb 15, 2016 16:29
|
|
|
Parallel Paraplegic posted:Yeah I realize it's like that in real life but I'm talking about magical future sci-fi matrix skynet AI that is what nerds think of when they think AI, not boring realistic learning machine AI. Ooh, this is legitimately really fun. And your point about debug output on the previous page is also well-taken. Yes, we definitely can see what a neural net is doing. If you really, really wanted to, you'd be able to trace a decision all the way from the output layer back to the inputs. It's all deterministic. But it would take so long and be so complicated that it would be borderline meaningless. You could ask "would similar inputs have caused a similar output or is this a point discontinuity?", and figure out the answer automatically. The thing is, you can't really do much with that data later, because the training process is so hard to grasp (and getting harder to grasp as we put more and more layers into our deep nets). Fun fact: deepdream was invented to give us more insight into what our image processing neural nets are doing. So now we have stuff like this:  And even with that spectacular debugging output, we still didn't hand-trim anything because we just don't know what to trim. We learned a few cool facts, like what training data to focus on adding to our training set, but nothing on the level of "neuron 12_j needs a stronger connection to neuron 13_q".
|
|
#
¿
Mar 4, 2016 22:17
|
|
|
divabot posted:Yudkowsky fellation in Scientific American Blogs. None of his opinions have changed in the years since the Sequences. He's also kind enough to directly state that giving him money for AI pseudoscience is ridiculously more important than mosquito nets, you plebs. Wow, I totally disagree that nothing has changed! Look at how aware he is of the problems with his confident predictions of the future. This is a man who once planned out an entire path to the singularity, believing that he had cracked the whole of it, and that the answer was a new programming language based on XML. He says all sorts of things that indicate his confidence level is lower: he talks about how lack of certainty implies a wide interval of credible guesses, which is a hell of a lot less strong a statement than "I will build it, and it will take less than ten years". He diverges with his past self on a number of issues: for instance, although it was always Hanson who loved the idea of emulated minds, Yudkowsky went along with it; here he rightly dismisses the idea as "underspecified". That's well done. He's still a crank, still wasting money, still not producing a drat thing, but the crank depicted in that article is way closer to the same reality that most AI researchers live in than the author of the sequences was. E: I mean, still not *very* close. For instance, if you ever want to piss him off you should ask him what he means by 'intelligence'. I guarantee he'll produce a long stream of words to try to hide the fact that he has no clue. SolTerrasa has a new favorite as of 10:41 on Mar 11, 2016 |
|
#
¿
Mar 11, 2016 10:34
|
|
|
Zemyla posted:Ooh, interesting. Is that anything like how ANNs use random dropouts to prevent overlearning? No, in my opinion, but I bet you could get a research grant on the topic anyway.  If I were trying to warp my thinking to the point that this sounded plausible I would mumble something about how "both are (probably) regularization processes during which precise detail is lost in order to preserve the usefulness of the general meaning of the learned information", but I would probably have to vomit after I said it. My advisor was really into this whole "biologically inspired" AI fad, and I just never saw the point of it: it doesn't make better intelligent systems and it doesn't teach us anything about neuroscience. It feels a lot like exactly the sort of navel-gazing that AI people are prone to falling into for decades at a time.
|
|
#
¿
Mar 11, 2016 22:39
|
|
|
Cingulate posted:I don't think the point of sleep spindles is regularization. But in the talk I linked to, Hinton says dropout resembles the fact that biological spikes are binary rather than analog and that the purpose of binary spikes is regularization. Haha, me either. But I got really used to twisting things around in my head until totally false comparisons between AI and biological systems sounded remotely plausible. I think at one point I told my advisor that my tweaks to MCTS resembled the mechanism by which babies learned to plan their physical movements. Thank god I took all that poo poo out of my actual papers.
|
|
#
¿
Mar 11, 2016 23:17
|
|
|
Cingulate posted:Hey SolTerrasa, what about the XML-like language Yud wanted to program FOOMAI in? Yeah, here's the Path to Singularity which includes the spec for flare (as much of it as ever existed). http://www.yudkowsky.net/obsolete/plan.html I wrote extensively about this in the mock thread, if you want to go read about it that'd be where. It's really, really something. Notably, two people thought they'd try and donate some time to make it happen but Yudkowsky never delivered a real spec and nothing came of it. Surprise!
|
|
#
¿
Mar 12, 2016 03:07
|
|
|
I can't help but post the most quotable parts again. This poo poo is amazing.quote:At present, I don't even have a publishable Flare whitepaper. I don't even have a finalized design. I am engaging in the sin of aggravated vaporware because I have been told, and convinced, that the timeline does not make any sense without knowing some of what Flare is and what it does. Please consider all discussion of Flare to have whatever degree of tentativeness and subjunctivity is required for that discussion to be an excusable act of speculation. quote:I don't have a Flare whitepaper available; I could probably get one together in, say, a month or so. Since I don't have a complete whitepaper, I was reluctant to say as much as I've said already. I don't want any crippleware versions coming out and depriving Flare of its incremental benefit. See, it's okay, because he has *notes*. If he ever *wanted* to, he'd just finish up those notes and then he'd be published. The reason he didn't do that is because he doesn't feel like it, he has more pressing demands on his time. quote:XML is to Flare what lists are to LISP, or hashes to Perl. (XML is an industry buzzword that stands for eXtensible Modeling Language; it's a generic data format, somewhere between generalized HTML and simplified SGML.) The effects are far too extensive to go into here, but the most fundamental effect is that XML is easy to extend and annotate, and this property extends into Flare programs and the Flare language itself. Yudkowsky had the ~brilliant~ thought that code should be machine readable. Wouldn't that be handy? (metaprogramming was invented before LISP. Go to school, kids, or else you too may end up reinventing the square wheel)
|
|
#
¿
Mar 12, 2016 03:17
|
|
|
divabot posted:The Rocket Alignment Problem has certainly informed me. That's a terrible article! So terrible that my primary criticism of MIRI has changed, it's no longer "They do not produce anything". They do not produce anything except excuses for why we shouldn't expect them to produce anything, which is much worse. They're essentially arguing "sure, it looks useless to you, but we expected it to!", without addressing the obvious question: "how do you know it isn't useless, then?". They've chosen the analogy of developing orbital mechanics prior to building rockets, but the arguments would be identical if they'd chosen the analogy of developing the science of alchemy before attempting to capture phlogiston. Even worse, they've cataloged this EXACT kind of argumentative error before. By their own standards, their arguments are "fully general" (https://wiki.lesswrong.com/wiki/Fully_general_counterargument) and would apply to even a hypothetical MIRI where the direction of research was "how many AIs can dance on the head of a pin?" or something equally insane.
|
|
#
¿
Mar 15, 2016 23:15
|
|
|
Freudian posted:I must have really missed the point of the Rocket Alignment article because I came away thinking it was written about how the Alphas can't actually commit to anything beyond vague pipedreams and the Betas are frustrated because they would also like to go to the moon but how exactly would you like to go about doing this?? I might be Explaining The Joke but the idea is that the Betas are being really irritating by asking that the Alphas exclusively focus on research which will be useful right this second under already understood frameworks. I am in the target audience as an AI professional and amateur space nerd, but the gist is that the Alphas are just about to discover that direct ascent trajectories are inefficient, if only the pesky Betas would let them do their basic research in peace. In the world that is constructed here, that sort of makes sense, but the analogy is a little too on the nose: the Alphas should of course be able to describe the general shape of their research even in vague terms, like "we think we should aim where the moon will be instead of where it is" or even better "we think that if we account for gravity we'll have a better idea of how to do trajectory planning". MIRI, of course, can't do that, so the purpose of the analogy forces the Alphas to look artificially stupid, and the Betas even more so.
|
|
#
¿
Mar 16, 2016 02:03
|
|
|
Cingulate posted:I've never seen any criticism of Sam Harris that was actually fair. Is this? Have you ever read any criticism of anyone that you thought was fair? I appreciate that you're well-informed on some issues but I swear you'd pop up demanding intellectual rigor in a thread criticizing Trump for being racist.
|
|
#
¿
Mar 30, 2016 18:27
|
|
|
Parallel Paraplegic posted:Uhh... what? The idea is that a lot of the time, minority characters (including/especially sexual minorities) are written into movies and TV in order to be killed later. Think about it like this: who does worse in a horror movie? Black guy, gay guy, lesbian woman, or lily-white fraternity bro type? This annoys and upsets people who belong to those groups because we're not in that much media to start with. I've got no opinions on this particular case, but in general it's a mildly upsetting trend. It happens a lot to lesbians specifically going back a decade or more. This ties in to the dark enlightenment because by asking content creators not to fictionally murder people who are part of the same social or sexual or gender minorities as us quite so often, we are members of the cathedral, mindkilled by Cthulhu and oppressing the free speech rights of somebody or other.
|
|
#
¿
Apr 4, 2016 04:36
|
|
|
The Vosgian Beast posted:His reasons for saying this are wrong, but Big Yud is five billion times more right in this particular sentence than he has ever been in his life. Yeah, this is amazing. I knew a lot of stuff about that guy, and I used to hate him very, very much. I devoted so many hours to the hatereading of the FOOM debate, to a bunch of the Sequences articles, to his old Path To Singularity writings (until the thread got GBS'd), but despite all that this is a legitimately good thing for him to say and I'm glad he did it. Rationalists on Tumblr get too much of Scott saying "now now, engage on a level of intellectual honesty with the rampaging mass of anger and rage shouting racial epithets and rape threats at the top of their lungs", and that sort of behavior (the engaging, and the shouting) is getting normalized. Yudkowsky coming out against that unambiguously is excellent, I just wish it has been three to five years ago when he had a much more sizable audience.
|
|
#
¿
Apr 9, 2016 19:55
|
|
|
Silver2195 posted:This Yudkowsky post touches on some related issues: Ugh, it's so weird to agree with Yudkowsky. Yeah, he comes off as smug and he says that hilariously wrongheaded thing about how "the third sin of rationalists is underconfidence"  , but I can't even get mad about that stuff because fundamentally he's right on his main point. , but I can't even get mad about that stuff because fundamentally he's right on his main point.
|
|
#
¿
Apr 10, 2016 00:04
|
|
|
Does that parse to "there is a lot of social psychology which appears to endorse mind-body dualism, therefore social psychology is bullshit", or am I just really confused?
|
|
#
¿
Apr 13, 2016 06:46
|
|


|
ToxicFrog posted:Abjad Soup is saying that there is no better way in Hoon, not that no better way exists ever. I think Hoon has integer overflow, so no, just a very very long time.
|
|
#
¿
Apr 13, 2016 17:46
|
|
|
Curvature of Earth posted:I'll link to at least one for posterity. This review sucks, but in the process of sucking it makes one good point: the beginning of NRxAB says Let Us Assume We Are hosed. I think you could write a review of the book arguing against that, and therefore against the whole book. Maybe this isn't a book for me, because I really don't think we are hosed. The eschatons of Yudkowsky and Moldbug and the SV technofetishists are insane on their face, but so is the dispensationalist Christian eschaton, and that of the fringe groups who claimed apocalypse was coming in 2015, 2013, 1988, whenever Jonestown was... I bet if you included really fringe groups you could go back hundreds of years. And certainly disasters have happened, but nothing that counts as the end of the world, surely. So there's a well-documented phenomenon of people claiming the end is nigh when the end was clearly not nigh. In that light it seems like just assuming that the end is in fact nigh this time would require a lot of justification, a lot of This Time Is Different stuff. Does anyone (maybe someone with a preview copy?) understand the basis of the assumption at the core of the book?
|
|
#
¿
May 11, 2016 04:02
|
|
|
Curvature of Earth posted:Phil's view is that global warming and environmental collapse are an apocalypse-level disaster that civilization has no hope of enduring. Huh. Is that a widely-held belief among experts, is Phil an expert himself, or should I be drawing parallels to Yudkowsky?
|
|
#
¿
May 11, 2016 05:02
|
|
|
Puppy Time posted:Is this something that really matters in the area of "gee, those DE fellers sure are strange"? I considered that, and I think the answer is yes, but only sort of. For the DE / NRx proper, not really. But for Yudkowsky, I really do think it matters. If the tone of the book is "look at this fool trying to escape his inevitable demise with cryonics and mind uploading", I'd agree. I've written on that before with regard to Yudkowsky's unshakeable belief in eternal life. But if the author then substitutes "of course, we'll all be dead of civilizational collapse before they even get the chance to die of natural causes", it seems to me that it sets a pretty different tone. I'll buy the book anyway and give it a shot, but I'm getting the same feeling I got from Dan Lyons' Disrupted, where the book mocks a target ripe for and deserving of mockery, but the author's weird quirks make it hard to really land any solid punches. Or maybe his position will turn out to be well-supported by experts, or maybe it won't turn out to impact the book much, aside from that first page which we've all read by now. E: GunnerJ posted:Are there experts in the field of assessing how robust human civilization is when faced with extreme planet-wide environmental dysfunction? I'm not sure. At a guess I'd say probably yes; there are experts in all sorts of really niche fields. I would imagine that historians can talk about local environmental collapses, at a minimum, right? E2: Yep, those people exist. Dr. Jason Ur from Harvard is an example. He says that climate change is speculated to be partially to blame for a few collapsed civilizations. He doesn't solely blame the climate, though, and his message is a relatively hopeful one, considering. quote:When we excavate the remains of past civilizations, we rarely find any evidence that they made any attempts to adapt in the face of a changing climate. I view this inflexibility as the real reason for collapse. Which is a pretty far cry from "This will happen to us, soon, and we will not survive". I guess we'll see when the book comes out. SolTerrasa has a new favorite as of 05:31 on May 11, 2016 |
|
#
¿
May 11, 2016 05:20
|
|
|
Ash Crimson posted:He even has a card... Ughhhhhh. 1) linguistics does not work that way 2) exolinguistics is a meaningless term that was made up by Star Trek 3) the right word for what Star Trek meant is xenolinguistics 4) it means the study of alien language, not some sort of unclassifiable magic word cloud, so they're even using the made up Star Trek word wrong 5) Anarcho-fascist is an intentional contradiction in terms, not a clever ideological niche. It was invented to make racial separatism more palatable and the entire purpose of the ideology is to be obfuscatory and confusing. Besides that, believing two contradictory things does not make you clever or wise, it just makes you wrong. 6) having ideas that can't be understood using popular conceptions of politics does make you "politically untargetable" but not for the reason you think. It absolutely guarantees your present and future irrelevance: no one who matters will ever notice you, let alone talk about you. gently caress I hate these cards E: ugh it isn't even exolinguistics, it's "exosemantics", which isn't even a loving Star Trek word, it's just meaningless syllables. Come on, whatever you were going for there I guarantee that linguists already have a term for it. "outside meaning"? I dunno, maybe that sounds deep to the sort of dorks who call themselves the loving Dark Enlightenment. SolTerrasa has a new favorite as of 17:15 on May 25, 2016 |
|
#
¿
May 25, 2016 17:10
|
|

|
The Vosgian Beast posted:I see Scott Alexander has been doing well in the months since this thread stopped paying attention to him I forgot about ESR. http://esr.ibiblio.org/?p=7095 Nothing worth reading: he claims credit for the lambdaconf kickstarter meeting its goal because of the awesome power of his Google+ following. He also believes that the skeletons are on the ropes: failing publicly at the height of their powers, they shall never recover, etc etc etc. His commenters are funny: one of them thinks that the skeletons are losing the war because of #TheChalkening, which I have never heard of. E: it looks like the chalkening (ughh) is a hashtag for people who write "Trump 2016" on things. Which hurts the marxist agenda in many ways, such as
|
|
#
¿
May 30, 2016 23:11
|
|
|
I knew a guy who interned at Urbit. He came back with the unshakable belief that Urbit was doing something revolutionary and that it would be huge and that he was getting in on the ground floor, but he had no ability to explain what was revolutionary about it or what it could be used for. When he tried, it came out weird and messy, like "it's a stateful system whose state is a function of a log of previous actions and previous states". Anyone familiar with this corner of information theory will recognize that as an unusually long-winded way to describe a simple state machine. He also emphasized that the contents of storage were a part of machine state, so they could be reconstructed from the log of previous actions. I contend that this has no value other than ensuring that you have a lot of trouble storing your unbelievably gigantic machine log anywhere (which, obviously, is why real computer systems do not do this).
|
|
#
¿
Jun 30, 2016 18:12
|
|
|
Fututor Magnus posted:Redpilled by Moldbug. Does he also believe that billions of people will eventually start using urbit just as they logon to Facebook? He thinks that the project will fail because its genius is just too revolutionary for our time. A hundred years from now someone will revive the long-dead project and perhaps in those times his genius will be respected etc etc etc we've heard this one before.
|
|
#
¿
Jun 30, 2016 18:44
|
|
|
Pope Guilty posted:Isn't the Bitcoin blockchain now so bloated and huge that it's becoming a problem? Is his answer seriously just to throw more storage at it? Yes to both. And this makes me crazy; an inevitable consequence of the contents of your hard drive being reproducible from a log chain is that you will be taking literally constant incremental backups. People who try to take daily or weekly incrementals run out of space if they try to keep them all, and literally constant backups would be way, way bigger. It's not like this is news to anyone.
|
|
#
¿
Jun 30, 2016 22:41
|
|
|
Antivehicular posted:Oh, hey, since we're back to Moldbug and CS, a question I meant to ask a while ago: what does Urbit even do? Not even "what does it theoretically do better than its competitors," just -- what does it do? If I were a dewy-eyed young DE wonk hungry to be the captain of my Urbit-boat, what would I use it for? The important thing to understand is that the purpose of Urbit is orthogonal to what it actually does. Programming languages and environments are measured in a number of ways, but one good way is how much power they give their users. You can do anything you want with assembly, if you're clever enough, but nobody does that now. On Google's App Engine, the user has the power to scale to thousands of machines without thinking about it, and do distributed storage and computation for free. In Visual Studio you get autocompletion that borders on sentience, it basically writes the boilerplate for you, allowing you to focus on writing the good and clever parts. Python gives you insane levels of introspection available programmatically. On AWS you get a database system which scales relational databases well beyond where a normal person should be using them. Java gives you reflection and a clear inheritance model. Any tool a programmer can use should be measured by what it allows the programmer to do which would otherwise be hard. In that context, urbit is not useful. What it actually does, basically, is be a lovely virtual machine that runs a lovely operating system which can only run code written in a lovely programming language. It is not useful. It is about as hard to write code for urbit and use it as a platform as it is to write assembly directly, with the downside that all programmers are at least vaguely familiar with assembly, and no one is familiar with the urbit architecture. The idea that it has, though, the purpose of it, is to extend the idea of property rights onto the internet. You can own space in Urbit land the way you can own land in the real world. That doesn't correspond to real, meaningful economic activity or even any real value at all, but it appeals somewhat to the same people who like bitcoin. It's scarcity on the internet, where normally everything is infinitely reproducible.
|
|
#
¿
Aug 9, 2016 23:20
|
|
|
The Vosgian Beast posted:Being afraid of AI is only slightly above being afraid alien abduction An interesting anecdote is that the thing that they're afraid of is tangentially rooted in something near reality. I'm part of a working group to reduce racism in AI systems, because it's an important problem to solve. Apply a crazy-alt-right filter to that and you get "making intrusive modifications so that AI regards black people as inherently superior to white people #whitegenocide #allfeaturevectorsmatter".
|
|
#
¿
Sep 14, 2016 20:59
|
|
|
It's a really interesting topic, actually. The sorts of AI systems in wide use (deep neural nets, to the exclusion of almost anything else, in my experience) are basically universal approximators. You have a function, with inputs and outputs. Say the input is a 1920x1080 photo, and the output is a score from -1 to 1 saying how photogenic that photo is, to help users of your photo app rank their photos of themselves by attractiveness. You have 2,073,600 inputs (pixels), each of which is a number between 0 and 16.7 million (number of expressable colors). So your function has a huge number of inputs and a single output. You have to teach this system how to compute the output from the inputs. It starts out totally random. So you do this with labeled data: this photo is a 0.7, this photo is a -0.2, this photo is a 1.0, etc. The network "learns" by mutating itself and seeing if it's doing better or worse, until finally it is "good enough". This is highly simplified but the details don't matter for understanding racism in AI. The volume of data you need in order to teach the system is related to the complexity of the function you're trying to teach it. The thing is, you as the programmer don't know the actual details of how the function should be implemented. If you did, you'd use that instead of mucking about with neural nets. This function, where we take 2 million inputs with 16 million values each, is pretty complicated, so we probably need a lot of data. It costs a lot of money to collect and label the ~10ish million pictures you'd need for this (a guess based on experience). The internet is already there, and it's pretty cheap. So, you go scrape the Flickr api, and say that images with a lot of likes / favorites / retweets or whatever are "good", and the other ones are "bad". You see the problem already. The internet is pretty racist. Pictures of white people are way more popular than pictures of black people. It's also the case that the people working on AI are basically all white dudes (I'm a white dude). Not to mention the issue of access to the internet due to highly racially correlated poverty. The AI system is operating with basically no oversight, and it's nearly impossible to get good insight into why it makes the decisions it does. All we know is, it does well on the training and testing sets. But since the internet is so racist, and since access to the internet and free time is so correlated with race, the training and test set underrepresent black people. AI is lazy as hell, by design (if you try to make it unlazy it will do worse things, ask me later if you want to know why). So, if it only rarely sees a picture of a black person, and most of the time the black person is scored low, it'll just learn "dark pixels = bad". And since the engineers working on it will test it with internet data, then *maybe* test it on photos of themselves, or their friends, it's really only going to get tested on white people. So they launch it, and later on a bunch of black people ask "why does this say all my photos of me are ugly?" So, how do we fix it? Well, one solution is to spend the huge amount of money to label the training data yourselves, with your Certified Non-Racist Sensitivity Trained Employees. This works okay if you're Facebook, and you have huge amounts of money that you can throw at silly features just cause it's fun. Not great, because everyone's a little bit racist and cameras themselves are kinda racist (another story, ask me later), but better. And you can go collect the data yourself and spend even more money on that, but nobody does that. It's just too expensive to embark on a ten million dollar data collection every time you want to launch some weird silly tweak to your photo app. We could also try to ban the AI system from making inferences based on racial or racialized traits. But the thing is, AI is really clever about being lazy. You tell it "no inferring anything based on skin tone" (at great expense, since this is actually really hard to do) and you find that it behaves the same, it just decided to use width of nose instead of average skin tone. So you fix that, and now it's something about delta between pupil color and iris color. And you fix that. All the time you're making these changes, your AI system is getting worse, because these changes are invasive, expensive, and actually do negatively effect accuracy and recall. So now you've spent months and millions on making your system worse, and it's still kinda racist, it just works harder at it, and it's a little bit veiled. Upsettingly, there isn't a lot of good research in how to solve this. So we're trying to do some. I can't talk about details, but to summarize: 1) this is a real problem 2) this is a pain in the rear end to fix 3) most companies and people and researchers don't bother 4) they should 5) qualified people are working on it 6) if we are successful we will definitely publish and then I can talk about it And if you thought my example was hyperbolic, that one is pretty realistic: https://www.theguardian.com/technology/2016/sep/08/artificial-intelligence-beauty-contest-doesnt-like-black-people
|
|
#
¿
Sep 14, 2016 23:36
|
|
|
Sure, here goes. The reason you make your AI lazy is not because otherwise it will take over the world. Once you know the math, AI loses all its mystery and mysticism. In my experience, most large modern commercial AI systems have a bit in them that's just pure machine learning, which tends to have a huge number of finicky parameters. Way too many to set by hand. When you create an AI system, during training you try to select these parameters so that the output of the whole system will converge with a set of examples you provide, like I described earlier. There's a lot of ways to do this. For example, some training methodologies just let the system modify itself at random and keep only the "good" modifications, and iterate until it's good enough. Another method that will impose more structure: calculate the derivative of "correctness" with respect to each parameter and bump them all in the "more correct" direction. But if that's all you do, your AI system will work perfectly in tests, then totally fall over when you try to use it for real. One time I was making a system that was supposed to play a really simplified discrete RTS game, like a really straightforward Age of Empires or Starcraft. I skipped this bit about making my AI "lazy". I had a handful of simple example enemies programmed in: one where they start on opposite sides of the map with equal resources, and the enemy just builds as fast as possible to get to a relatively powerful unit then builds them nonstop. And then another one where they start very close to each other with only one peasant, and the enemy runs away to go claim the desirable part of the board. And so on, about 5 examples, in increasing order of what I thought of as complexity. The hardest one was a turtle enemy with strong defenses against the Al's one peasant but lots of resources. So I set that running, and spitting out output "(0/5 scenarios won, X time steps elapsed in Y seconds real time)..." and leave it alone for a while. I come back to it a day later or so and it's looking good! 4/5 won, it never beat the 5th one but still, pretty good. I watch a replay of one of these matches in a visualizer and it looks good. Unconventional solve, but that's to be expected with a new game and an AI unused to normal RTS games. So I fire up a human v AI game and see if I've trained a master Starcraft player, and... Well, I gave an order to a peasant, and then the AI didn't do anything. It didn't even randomly move its own peasant or go mine a useless resource or anything. I was surprised. I won in like a minute, and then I started trying to figure out what went wrong. I checked the games against the preprogrammed enemies, and it still worked there. When I finally figured it out I was annoyed. What happened was, the AI found an easy-win button for 4 of 5 scenarios. In one, it found out that if you attack enemy peasants with your peasants, the preprogrammed enemy didn't respond. In another, it invented a peculiar rush strategy where it'd build a constant stream of entry level ranged units since the AI enemy didn't build any ranged defenses. They all died, but they did a little damage and I never programmed that enemy to repair anything. Anyway, the important thing was, it only learned how to deal with exactly the one set of preprogrammed responses in exactly those four scenarios. Move one peasant's starting position by one square and the AI would have no idea what to do, it'd have to relearn from scratch. Because of this memorization technique, the AI was *huge*. The action-value function had a nonzero term for not just most spaces on the board times most types of unit, but for a startling swath of the entire board state-space. A few more scenarios or a marginally larger board or a few more unit types, and I would have run out of RAM trying to train this thing (and now that I think about it, it must have been swapping to disk). It could never have played adequately against a human, since humans don't use exactly the same moves every single time. This dumb mistake is a special case of what's called "overfitting". The solution is a special case of what's called "regularization", where you penalize the AI for getting too big and smart. So when your system is futzing around randomly trying to learn good parameters for the massive fiddly machine learning pieces, you need to also enforce that it never gets too complicated. Rules like "if there's a peasant on square 1,4 with 3/5 health and also there's a militiaman on square 2,7 with 7/15 health then move the peasant to square 1,3" need to be harder to learn, more expensive, than the more expressive, more general rules like "always move peasants away from militiamen". You (very generally) want your AI system to learn the fewest possible and simplest possible and most generic possible rules. But if you don't apply pressure in that direction, it'll often end up just memorizing the inputs and being completely useless as a generalized solution. So you make your AI lazy. You constrain its resources, or subtract points for complicated or large solutions, or you explicitly ban it from making decisions based on things that are too specific, or you remove neurons or features completely at random, or something.
|
|
#
¿
Sep 15, 2016 19:55
|
|
|
Osama Dozen-Dongs posted:So how are cameras racist? Are you going for something like they can't capture contrasts on dark objects as well as human eyes or something? (See also, any photos of people wearing black) Those things are probably also true, but I was talking about three other pieces: scene metering, color correction, and autofocus. This part is outside my area of direct expertise so I'll be brief. People have probably heard this before. Most scene metering tries to make the average brightness someplace around 18% grey. Almost anything other than manual mode on a nice camera is going to try to do this. Why 18%? It looks good, and it's what they've always done. Originally I'm sure it was selected on the basis of some experiment or other, but it has the effect of dramatically underexposing photos of people with dark skin. Color correction: not as serious a problem anymore now that we have digital photography but it does mean that you end up needing to do post-processing on photos of people with dark skin where you don't really have to do anything for photos of people with light skin. During the film era it was really insane: photo labs were literally calibrated using a stock image of a white woman in a black dress, and that was that. Autofocus: autofocus usually looks for contrast, or if you have a nicer camera it looks for faces, and it looks for faces using old school computer vision techniques which come down to "distance between the eyes" and "shape of cheekbones" and a bunch of other stuff, all of which were tuned for white people. If you're talking about contrast-based autofocus then it'll usually find less contrast between a dark skinned person and their background.
|
|
#
¿
Sep 15, 2016 23:09
|
|
|
Sax Solo posted:Can you just explain what's wrong with it succinctly? I don't want to sift through your comment for the relevant parts that will help me sift through an SSC post; that is like a double nightmare. I can do that. Scott has a lot of beliefs drawn from the unfortunate fact that we called our current industry darling ML method "neural networks". He thinks that the apparently natural analogy to a human brain is a correct one, that reward functions are analogous dopamine and serotonin, that learning-by-example is analogous to ML training, and so on. This is one of those analogies that seems modestly accurate to a layperson but breaks down almost immediately. At one point he says that he finds accurate machine facial recognition deeply alarming, in what I think is the least necessary terror since the Basilisk. It's just uninformed layperson speculation on a complex and technical subject, so it's wrong some places, unoriginal and obvious in others, and in some places it's so off base you can't even call it "wrong".
|
|
#
¿
Dec 11, 2016 21:06
|
|
|
Peel posted:People want to know the error being made without having to read two long posts. There are only so many minutes in the day. Your neural network is receiving 'that's incorrect' signals about how you interact with people, consider reassessing your beliefs. That's one of the not-even-wrong statements, in my opinion. There's no way to phrase that formally enough that it can even be critiqued, it relies on informal understandings of things like "moral", and "principles". Is he imagining a "moral rightness" classifier? A generative model of "right actions"? What sort of inputs to this system is he imagining? "the entire state of the world, plus a proposed action"? How could you even specify those things?These might seem like petty quibbles or implementation details, but once you try to formalize these in a way that you can actually do work with them, you find that you can never quite encapsulate them the way you hoped.
|
|
#
¿
Dec 11, 2016 21:15
|
|
|
divabot posted:So, what's Eliezer Yudkowsky been up to! This is insane. The AI gold rush (which is a pretty good term) is not doing anything that feeds into his preferred disaster scenario. He believes in what he calls the AI FOOM, where an intelligent system is given the task of updating itself to be more intelligent, recursively. He believes, for whatever reason, that intelligence can be quantified and optimized for, and that the g factor is a real quantity rather than a statistical artifact. These aren't majority views, but it's not implausible. Or, at least, I'm the wrong kind of expert to say that they are implausible. I'm an AI guy, not a human intelligence guy. https://en.wikipedia.org/wiki/G_factor_(psychometrics) So, let's generously take those as true. He believes that optimizing g is something that's possible. He's never addressed it directly, but a necessary piece of his belief in FOOM is that the upper bound on g is sufficiently high that it counts as superintelligence (or else the upper bound doesn't exist). As far as I know, there's no research on these points because the field of AI doesn't really include these sorts of questions, but let's pretend that these are true as well, and that we live in Ray Kurzweil's future. Keeping score, we're at two minority beliefs and two completely unresearched propositions accepted on faith. He believes that, while optimizing its own g factor, the intelligent system in question will have a high rate of return on improvements, that one unit of increased g factor will unlock cascading insights that contribute to the development of more than one additional unit of increased g. This is argued here: http://lesswrong.com/lw/we/recursive_selfimprovement/, and you'll find there's not a shred of argument there. It's bald assertion. He also baldly asserts that the "search space" (which is not the right term, but remember, he's a high school dropout autodidact with no formal AI education) for intelligence is smooth, with no "resource overhangs". I'm pretty sure he means to make the point that he expects to find relatively few local minima*. That's just unknowable, but while working on much much simpler optimizations, I have found absolutely no end of local minima. There are almost no complex problems without them. I would not be inclined to believe this if he had already done it, that's how unlikely it is. So now we're at two minority views, two unresearched but cogently phrased propositions, one bald assertion, and one deeply, deeply unlikely belief. This doesn't carry us all the way to his nightmare scenario, there's a lot more stuff in the house of cards that makes up his FOOM beliefs, but that's enough, really, to get the point of my next paragraph. We are not studying any of those things. The AI gold rush is almost entirely about deep neural networks in new and weird variations, or, if he's really up on the AI field, GANs, which are deep neural networks in new and weird variations plus a cute new training mechanism. (As I write this I realize he's almost certainly terrified of GANs for a misguided reason. I'll come back to that if someone wants to hear it.) None of this validates any of his beliefs. Deep neural networks are entirely inscrutable. No one anywhere can tell you why a deep neural network does what it does, so there's no reason to suspect that they will spontaneously evolve a capability that have proven to be beyond the very best AI experts in the world out of nowhere. Deep neural nets also have severely limited inputs and outputs. They are not capable of learning anything about new types of data or giving themselves new capabilities; the architecture doesn't support it at all. The sort of incremental increase in capabilities that Yudkowsky needs for his FOOM belief to come true does not exist, and really just can't be brought about. I'm not even halfway done with the reason that neural nets can't be the Yudkowsky bogeyman. They train too slowly for a FOOM. They don't use any of the Bayes stuff that's so essential to his other beliefs. They don't have any mechanism for incremental learning outside of a complete retraining**. They can't yet represent sufficiently complex structures to write code, let alone complex code, let alone code beyond the best AI programmers in the world. I'll stop here. It makes no goddamn sense. Maybe his beliefs have evolved from the AI FOOM days. I don't know. I've been impressed with how some of his other beliefs have changed to reflect reality. I'll go read what he has on Arbital and let y'all know if I'm way off base here. *minima on a loss function, maxima on "intelligence"; by habit I use the former but it might be more intuitive to think it terms of the quantity being optimized. If so, read this as "maxima". **someone might call me on this one; I should say instead that everyone I've ever worked with has done complete retraining, and if a better mechanism existed they'd probably be using it, but I can't say that there's definitely *not* such a mechanism. It's not impossible due to the nature of the architecture. SolTerrasa has a new favorite as of 10:15 on Jan 9, 2017 |
|
#
¿
Jan 9, 2017 04:31
|
|


|
Quote not edit, whoops
|
|
#
¿
Jan 9, 2017 04:36
|
|
|
gently caress, I don't know why I even try to read this poo poo anymore. https://arbital.com/p/real_world/ This is Yudkowsky's attempt to address what I'd regard as the core problem of his beliefs. quote:Acting in the real world is an advanced agent property and would likely follow from the advanced agent property of Artificial General Intelligence: the ability to learn new domains would lead to the ability to act through modalities covering many different kinds of real-world options. "By definition God is omnipotent, so it has all capabilities, including the capability of acting in the real world. Checkmate." And of course "advanced agent property" links to ten thousand words about what AI God will be able to do. Don't read them; I did and it was a huge waste of time. They're not even funny-wrong, it's like reading a cyberpunk worldbuilding forum, or the character options chapter in Eclipse Phase.
|
|
#
¿
Jan 9, 2017 05:15
|
|
|
BobHoward posted:I'd enjoy an effortpost about GANs, and perhaps also what distinguishes a "deep" neural network from the stuff that has been around since (I think?) the 1990s. If you're up for it. Sure! It's not too hard, really. What makes a deep neural network deep? So, the very first neural "network" was back in the 1950s, this thing called the perceptron. It has some number of inputs, and one output. It's wired up internally so that it can draw a single line through its parameter space. Wikipedia has a good graphic for explaining what that means. 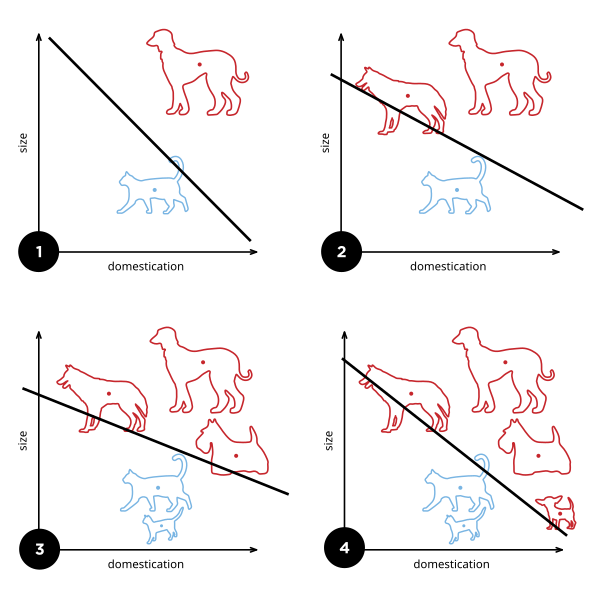 Funny story, AI hype is actually older than the term AI; the perceptron was heralded by the NYT as "the embryo of an electronic computer that [the Navy] expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence." No poo poo, they thought a linear combination of inputs with a threshold was going to be conscious of its own existence. Anyway, in the 1960s they discovered that a single perceptron was pretty limited in what it could represent; the canonical example of unrepresentable data is anything that requires an XOR-like function. 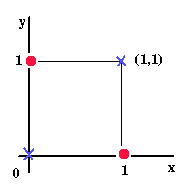 See, no way to draw a single line separating the red dots from the blue ones. All of this is not very exciting anymore, but it was really interesting in 1960, and there was a big fight over who proved it first, standard academic stuff. So, what you do is, you hook up three perceptrons. Two of them draw the lines in this picture (from a totally different website; the XOR thing is super common) 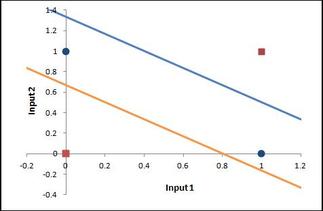 The third one combines the input of the other two. That's now a neural network, in that there's a network of these neurons. It happens that two layer networks can answer the XOR problem. Actually, it's since been proven that two-layer networks can do literally everything; they are "universal approximators". Any function you care to state, a two-layer network can approximate to an arbitrary fidelity. A deep neural network is a neural network that has a lot more than 2 layers. 15 - 30 layer networks are pretty common, and those are definitely "deep". There's no hard line, but 3 layers is probably not "deep", and 10 probably is. The reason deep neural networks weren't popular earlier is that it is a lot harder, computationally, to train a 15 layer network than a 2 layer one. And you might reasonably ask "why would anyone build a deep neural network if 2-layer networks can approximate any function?" The answer is, deep neural networks are better at it, usually. For some reason, and literally no one in the world can tell you why, deep neural networks are way more effective at complex tasks, especially at image recognition. By "more effective" I mean that they need way fewer neurons to perform at the same level. Again, no one knows why for sure. There are some guesses, but nothing solid or definitive. What are GANs? Three parts: "Generative" "Adversarial" "Networks". Networks we covered, GANs are deep neural networks. "Generative": There are two different types of neural networks. There are discriminative models, which do things like decide whether a particular picture is a picture of a fish. More formally they directly learn the function P(x|y), where x is the class ("fish") and y is the input data (the picture). P(x|y), then, means the probability that the image, y, belongs to class x ("fish"). The way that those are set up, they have input neurons for the image, and a list of outputs for the different classes they know about, each of which gets P(x|y) output to it. So you might have P(fish|image) = 0.8, P(pig|image) = 0.01, P(bird|image) = 0.02, etc etc. Second, there are generative models, which learn P(x,y). That's the joint probability of the image and the label. So they have inputs for the image, but they also have an input for the class, and a single output, for P(x,y). If you know the probability distribution of the labels (which you almost always do), you can convert this to P(x|y) using Bayes rule, so generative models can almost always do everything that discriminative models can. Sometimes they're harder to work with and they usually train slower and require more data, in my experience, but YMMV; I don't know of any formal findings on that subject. They can also do some other things, too, though, like you can use them for creating new (x,y) pairs, that is, new images and labels. If you provide "x", then you can use them to make new y; so you can use a generative model to make a new image of a fish. Usually you don't care about this capability so you won't bother with the extra overhead of building a generative model. So, the third part is the fun one: "Adversarial". What you do is, you train two neural networks. One of them is the discriminative one, which is usually your actual goal. You usually want to determine if a particular picture belongs to some class, I'll stick with the fish example. So you train one network which is supposed to be able to tell if an image in a training set is an image of a fish. Then, you train a generative model, which is supposed to be doing the same thing. At some number of iterations of training (some people start at 0, but I personally wouldn't), you start adding in the generative model's "fish" as negative examples in the training set for the discriminative model. So, the discriminative model gets punished for thinking that the generative model's fish is a real fish. And then you teach the generative model how to read the "wiring" of the discriminative model, so it can see how to make a more effective forgery. You let these things run against each other for a while and bang, you have a really good discriminative model and a really, really good generative model. Here are some pictures generated by the generative model in a GAN. 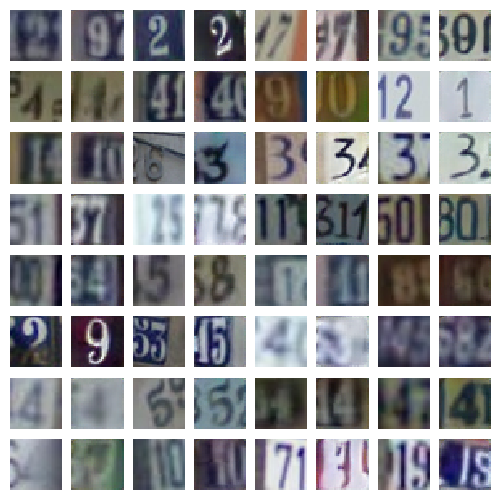 Fake "pictures of house numbers"  Fake "celebrity faces" Honestly those are pretty persuasive; I looked at a few of them and thought "huh wait isn't that... nope, never mind". Let me know if that made sense. I guess it's pretty obvious why that might terrify Yudkowsky, right? I mean, this is all conjecture on my part since he didn't come out and say what he thought was so scary, but it seems to hold together and it's the best I can do absent actually talking to him. I realized while I was thinking about it earlier today, his whole ideology folds back in on itself. That's why he's got 5,000 links in every post he writes, so that he gives the appearance of having well-supported opinion. He probably thinks he has well-supported opinions, but if you try to hold the whole thing in your head at once, you see it's circular. The essential circular argument at the distilled core of the whole thing is "AI research is dangerous because the impending superintelligence will allow 3^^^3 units of pain to be distributed to every living human", and "Superintelligence is impending because of the dangerous irresponsibility of AI research". Usually you have to step through 3 or 4 intervening articles to find the loop (or bare assertion), but my sense is that there's always one. If I could ask Yudkowsky for anything at all it would be a single, self-contained argument, in less than 3,000 words, for why superintelligence is imminent. So, starting from those two premises (which of course I believe to be false), that superintelligence is imminent and that AI research is dangerous, you can see why he'd be scared of GANs; it's exactly the sort of introspective AI that he is normally terrified will run away and become God. It looks like self-improvement, if you squint a little bit, and it is recursive, and you add those two things together along with a baseline belief that something is going to become superintelligent and end the world, and some AI technique is going to be responsible, you could pretty reasonably come to the conclusion that it's going to be this thing, this time. And Yudkowsky already believes that GOFAI ("Good Old Fashioned AI"; expert systems and decision theory and so on) techniques are not going to create God (source: http://lesswrong.com/lw/vv/logical_or_connectionist_ai/), so GANs are my best guess about his best guess for the end of the world. Invented in 2014, which is when he said that this whole situation got started ("The actual disaster started in 2014-2015"), so that fits too. I think I already covered why it's not going to be a deep neural net (or any neural net) which ends the world, unless you count the brain of the guy with the nuclear codes. I've been reading too much Yudkowsky, I'm going to go drink. If you have any questions or want any followups, I'll get back to you tomorrow.
|
|
#
¿
Jan 9, 2017 09:02
|
|
|
|
| # ¿ May 10, 2024 04:35 |
|
|
BobHoward posted:Thanks, SolTerrasa! That was an amazing post. I really like this question, because I had to think about it. (since I had to think about it, I'm only pretty sure about my answer.) It's definitely possible for the generative model to be perfect and output an image which a human would consider to be correct, or even better, a pixel for pixel copy of something actually in the training set. If that happens, the network does face a little bit of a problem in that it'll be penalized no matter what it does. And sometimes the generative model does get so good that the discriminative one loses the fight, overall. But it's pretty unlikely to be a big problem, assuming you designed your generative model correctly (either pretraining it on a separate held-out dataset, or not pretraining at all, plus regularizing so it avoids memorization). Probably. I got a masters and turned down a PhD program to go into industry, so a lot of what I know is the pragmatic-but-kinda-gross-and-wrong techniques used in practice. Like, if your GAN discriminative network starts losing accuracy, just stop training. Or if your network habitually overfits, chop some layers out and add them back in one at a time until it works. If there's an actual academic in the thread, please speak up. divabot posted:could I please quote your post (with or without attribution) on tumblr? I want to make rationalists cry. If you like, but I didn't write it for an adversarial audience, so if they yell about some part of it being wrong they might very well be right. And without attribution ("AI engineer at Google" is fine if you like it better that way), please. Some of those people scare me, I don't know how you go around posting photos of yourself and still engage with them on a regular basis. ate all the Oreos posted:This is really cool, thanks! I'm biased by the whole Google employee thing, but I love the tensorflow MNIST tutorial. Recognizing handwritten digits is an exactly perfect balance of "obviously useful task" and "easy to do". https://www.tensorflow.org/tutorials/mnist/beginners/
|
|
#
¿
Jan 9, 2017 19:24
|
|