

|
Starring this thread 
|
 #
¿
Apr 30, 2015 13:26
#
¿
Apr 30, 2015 13:26
|
|


|

|
| # ¿ Apr 29, 2024 00:48 |
|
|
In the SICP vein (I really enjoyed the classic one) The Lisp-Flavored-Erlang people are currently rewriting the code sample and exercises to work with their variant of the language: http://lfe.gitbooks.io/sicp/ I've put a lot of Erlang resources in the Erlang thread, but I'm ready to rewrite them shorter for this thread if anyone would like that.
|
|
#
¿
May 1, 2015 12:52
|
|
|
This has been the major challenge of functional programming, IMO. Most of the algorithms you'll see out there that do any form of dynamic programming will use a mutable array somewhere in there, or will make assumptions of things like O(1) hashtables. In an immutable language, O(log n) with a high branching factor is as good as it gets without special runtime support to hide that poo poo, most of the time, or possibly amortized O(1), which still ends up having a high cost here and there. Almost every time you want to use an algorithm you know, you end up having to find a clever way to transform it to work a bit differently (or to invent your own variation of it) so that it meshes well with the stuff supported by your language and its constraints.
|
|
#
¿
Jul 20, 2015 13:25
|
|
|
Pollyanna posted:What sort of techniques are good for handling data structures in FP? I've already noticed that things like recursion and tail-call optimization needs you to pass in something like an accumulator, your previous value, and you current value, but it's never quite sunk in. So that's quite a topic, and there's a lot of stuff to optimize for. The big two are always memory and CPU. Tail-recursion with an accumulator goes for the memory argument. The idea there is really to avoid growing the stack for pending operations and to instead do them progressively, one at a time, with a constant-depth stack. But more generally, the big issue with functional data structures is going to be that a mutable model will tend to use an O(1) access data structure as it's major building block for a lot of them: an array where each element can be modified individually and accessed 'instantly'. The usage of pointers and references also helps there under the same kind of optimization because you can keep a view of any part of a data structure (like the two ends of a linked list) to get fast append and prepend operations. Those will be at the core of a lot dynamic algorithms and simple data structures like buffers of all kinds and whatnot, and will help you shave off large factors of complexity by using pointers or reference to cache a given part of a data structure and access it instantly. The cost of these, obviously, is that any dangling pointers or references to individual elements is risky. Either they need to be copied explicitly (and deeply) or they need to never be held for too long unless you feel like risking funny mutations here and there. So you can deep copy and that's super expensive. To cope with that problem, functional languages like Haskell or Erlang introduce sharing. Let's say I have a tree T: code:code: Basically, the entire unchanged subtree starting at b is kept for both Old and New trees, but the rest changes in some way. The h node is also shared because it had no reason to change. The F node had to be copied and rewritten to allow to change what child it has, but note that if the content of F is large, that can be copied literally. I.e. if my node is {Current, Left, Right}, I need to change the node, but could still point to the existing 'Current' value from the older tree. This is efficient and useful, and lets you allocate O(log n) memory only for each new element across trees, rather than copying the whole thing. So what about arrays? Well let's imagine an array of 10 elements: [0 1 2 3 4 5 6 7 8 9]. If those 10 elements are stored in the array directly, then every time I modify the array, I have to copy 100% of it to avoid mutability. If I instead point to 10 elements, I can update one of them, then create a new array with 9 pointers in it that go to the same data as the old one, and a new in there: code:So that's the big secret of functional data structures, and immutable ones in general. All you have is trees and singly-linked lists (which are just very flat trees by the way), and you make do with it. The vast majority of work with functional data structure is therefore going to go in something like:
The compiler people (and people in Rust) will spend a lot of time in 1. The Functional people (such as Chris Okasaki) will spend a lot of time in 3. So you end up with the fancy Okasaki data structures and others:
There's plenty of sources for such data structures. What makes the Okasaki book (Purely Functional Data Structures) so interesting is that he's made the analysis in a way such that the cost of expensive operation can be considered to be a kind of 'debt' accumulated over the lifetime of the data structure. So the cost is equivalent to each operation done (and is therefore O(1) if you were to spread it over the lifetime of things). To illustrate it, let's use the doubly-ended queue. If I were to use a single linked list as a queue, I would have the following stuff: code:code:code:code:and that's where the amortization handwaving takes place: if reversing the list is O(N) and I pay the cost only once per element, then I can, over a long time, smudge its cost into each insertion or each removal (which is O(1)). As such, because I have to pay 1/N of the cost of reversal for each element, and only once, I can pretend that over the lifetime of the program, the reversal is costing O(1) per element. As such, I say that my amortized cost for the queue is O(1) for insertion and removal. So functional data structures often end up having the right kind of tree to optimize the very common use case we have, and then make sure (as much as possible) that all other rarer and costlier operations only need to be done once per element in the data structure, letting us handwave it as a lower amortized cost. ... There's one last category which is "I want to represent circular references doubly-linked data structures the way I can with pointers", and the result for that are zippers. I'm a bit short on time for now but can expand on this if asked to.
|
|
#
¿
Aug 3, 2015 18:47
|
|
|
QuantumNinja posted:For zippers:  QuantumNinja posted:The rebuilding process in MononcQc's last post is part of the rub. If each process has a pointer to D at the top of the tree, then how do they each learn that D has changed to the new D because a single process needed to add something? They need a shared pointer, right? And if each thread needs to put things into this tree, they all need to update not just that shared pointer, but maintain the new nodes that another tree may have generated during insertion. You end up needing a safety mechanism like an atomic lock on that reference; otherwise, process A may read node D, rebuild part of the tree, then yield to Process B, which reads node D, rebuilds part of the tree, then yields, then process A updates D to be D_A and yields, then process B updates D with D_B. D_A's updates are entirely lost because the nodes build as part of D_A were only ever contained in Process A and its update. An atomic lock on the structure will solve this, but that's a huge slowdown in the program. The other thing you can do is 'queue' updates into a single thread that has final say over everything, but even then requesting values from D means that the manager has to discharge all of the updates pending that might be relevant to looking up the value. That's one of many ways. The thing there is that you still do your parallelism from a point of view of having a central authority, so yes:
This is still complex, but the advantage of most functional languages is that any breakage to nothing shared/immutability everywhere will be the exception rather than the norm; you can't easily end up accidentally writing code that isn't thread safe. In languages like Haskell, the restrictions on global state also means that generally, all the weird rear end interaction that cause problems are restricted in ways most languages won't do, and that's where a lot of the ease comes from. Different languages do different stuff. Mercury or some Schemes will do automatic parallelism, Erlang has everything explicit (processes and message passing, some tables with shared global write spaces, though the data from them is copied to processes), Haskell has various options (say, software transactional memory), and so on.
|
|
#
¿
Aug 3, 2015 20:24
|
|
|
The book shows a bunch of data structure; the amortization analysis really boils down to mathematical proofs of "this operation happens once per element at most, ever, therefore amortized!", and the usage of laziness (with delay/force) is mostly so that if someone reuses the same data structure many times (so that I re-pop the same element 500 times because I use old references of the immutable datastructure), I can have memoization to make sure I never paid the cost more than once. You can look at the annex (for the Haskell code) or just paper over to the ML code and reimplement it as is and you'll get a bunch of useful data structures. As a non-academic who does a bunch of functional programming, I'd say I'd found a few main usages for the book: - a dictionary of data structures I can steal and reimplement - a way to see how I could rig my own data structures and think about their performance -- the book has trick in things like how or when to rebalance - a bunch of tricks that can be readapted from one datastructure to the next and gotchas about use cases (it is possibly faster to do a negative lookup ['thing doesn't exist'] in a trie than a hash) The big analysis bit is useful to wrap your head around, but being able to replicate it has not proven essential to me once you get a kind of intuitive feel for things you do.
|
|
#
¿
Aug 4, 2015 16:05
|
|
|
Almost every function is the same: extract players off game state, do an operation on one or the other, and then replace the players in the game state. I'd probably make an abstract function for these that takes care of doing that. Pass in a pair of players, expect a pair back. Then the function that calls it just has to deal with extracting/reinserting them. That will save up a bunch of lines on repeated abstractions.
|
|
#
¿
Feb 18, 2016 20:30
|
|
|
Pollyanna posted:I'm doing some Elixir practice projects and the concept of OTP and functions as processes is definitely interesting, but I'm having a hard time understanding the real world application of it and why you would want to structure a system that way, and what kind of common problems/notable systems and products call for OTP. What is it usually used for? Phoenix always talks about chat apps 'n stuff, but that seems like a different thing to me. Rather than making a very long post about this from scratch, I'll source a transcript of a talk I gave on 'The Zen of Erlang' that mentions what OTP can bring to system structure: http://ferd.ca/the-zen-of-erlang.html 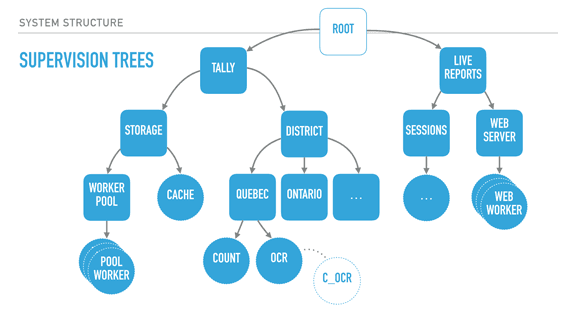 With supervisors (rounded squares), we can start creating deep hierarchies of processes. Here we have a system for elections, with two trees: a tally tree and a live reports tree. The tally tree takes care of counting and storing results, and the live reports tree is about letting people connect to it to see the results. By the order the children are defined, the live reports will not run until the tally tree is booted and functional. The district subtree (about counting results per district) won't run unless the storage layer is available. The storage's cache is only booted if the storage worker pool (which would connect to a database) is operational. The supervision strategies (one-for-one, one-for-all, rest-for-one) let us encode these requirements in the program structure, and they are still respected at run time, not just at boot time. For example, the tally supervisor may be using a one for one strategy, meaning that districts can individually fail without effecting each other's counts. By contrast, each district (Quebec and Ontario's supervisors) could be employing a rest for one strategy. This strategy could therefore ensure that the OCR process can always send its detected vote to the 'count' worker, and it can crash often without impacting it. On the other hand, if the count worker is unable to keep and store state, its demise interrupts the OCR procedure, ensuring nothing breaks. The OCR process itself here could be just monitoring code written in C, as a standalone agent, and be linked to it. This would further isolate the faults of that C code from the VM, for better isolation or parallelisation. Another thing I should point out is that each supervisor has a configurable tolerance to failure; the district supervisor might be very tolerant and deal with 10 failures a minute, whereas the storage layer could be fairly intolerant to failure if expected to be correct, and shut down permanently after 3 crashes an hour if we wanted it to. In this program, critical features are closer to the root of the tree, unmoving and solid. They are unimpacted by their siblings' demise, but their own failure impacts everyone else. The leaves do all the work and can be lost fairly well � once they have absorbed the data and operated their photosynthesis on it, it is allowed to go towards the core. So by defining all of that, we can isolate risky code in a worker with a high tolerance or a process that is being monitored, and move data to stabler process as information matures into the system. If the OCR code in C is dangerous, it can fail and safely be restarted. When it works, it transmits its information to the Erlang OCR process. That process can do validation, maybe crash on its own, maybe not. If the information is solid, it moves it to the Count process, whose job is to maintain very simple state, and eventually flush that state to the database via the storage subtree, safely independent. If the OCR process dies, it gets restarted. If it dies too often, it takes its own supervisor down, and that bit of the subtree is restarted too � without affecting the rest of the system. If that fixes things, great. If not, the process is repeated upwards until it works, or until the whole system is taken down as something is clearly wrong and we can't cope with it through restarts. There's enormous value in structuring the system this way because error handling is baked into its structure. This means I can stop writing outrageously defensive code in the edge nodes � if something goes wrong, let someone else (or the program's structure) dictate how to react. If I know how to handle an error, fine, I can do that for that specific error. Otherwise, just let it crash! This tends to transform your code. Slowly you notice that it no longer contains these tons of if/else or switches or try/catch expressions. Instead, it contains legible code explaining what the code should do when everything goes right. It stops containing many forms of second guessing, and your software becomes much more readable. 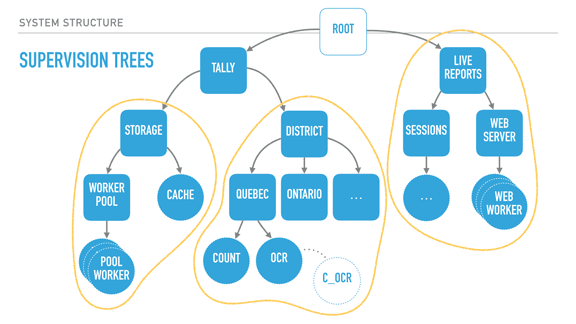 When taking a step back and looking at our program structure, we may in fact find that each of the subtrees encircled in yellow seem to be mostly independent from each other in terms of what they do; their dependency is mostly logical: the reporting system needs a storage layer to query, for example. It would also be great if I could, for example, swap my storage implementation or use it independently in other systems. It could be neat, too, to isolate the live reports system into a different node or to start providing alternative means (such as SMS for example). What we now need is to find a way to break up these subtrees and turn them into logical units that we can compose, reuse together, and that we can otherwise configure, restart, or develop independently. 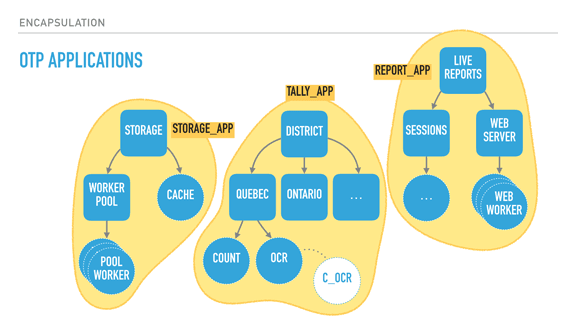 OTP applications are what Erlang uses as a solution here. OTP applications are pretty much the code to construct such a subtree, along with some metadata. This metadata contains basic stuff like version numbers and descriptions of what the app does, but also ways to specify dependencies between applications. This is useful because it lets me keep my storage app independent from the rest of the system, but still encode the tally app's need for it to be there when it runs. I can keep all the information I had encoded in my system, but now it is built out of independent blocks that are easier to reason about. In fact, OTP applications are what people consider to be libraries in Erlang. If your code base isn't an OTP application, it isn't reusable in other systems. [Sidenote: there are ways to specify OTP libraries that do not actually contain subtrees, just modules to be reused by other libraries] With all of this done, our Erlang system now has all of the following properties defined:
In a nutshell, the Zen of Erlang and 'let it crash' is really all about figuring out how components interact with each other, figuring out what is critical and what is not, what state can be saved, kept, recomputed, or lost. In all cases, you have to come up with a worst-case scenario and how to survive it. By using fail-fast mechanisms with isolation, links & monitors, and supervisors to give boundaries to all of these worst-case scenarios' scale and propagation, you make it a really well-understood regular failure case. That sounds simple, but it's surprisingly good; if you feel that your well-understood regular failure case is viable, then all your error handling can fall-through to that case. You no longer need to worry or write defensive code. You write what the code should do and let the program's structure dictate the rest. Let it crash. OTP is pretty much instrumental to that.
|
|
#
¿
Jan 4, 2017 16:31
|
|
|
Ochowie posted:Any chance you have a recording of this? First conference was a private corporate one. I made a second presentation at reactive summit in austin earlier this year which was recorded though. https://www.youtube.com/watch?v=4ZIPijEqrNI The matching slide copies are at http://www.slideshare.net/Reactivesummit/the-zen-of-erlang
|
|
#
¿
Jan 5, 2017 02:09
|
|
|
Doc Hawkins posted:Informative and entertaining. You got multiple laughs out of me, so I assume the audience's silence was from awe at your sheer presence. Thanks. Audience was pretty sparse (was much more of a scala+kafka crowd, didn't get a lot of ears there) and without having listened to the recording, I'm guessing a directional microphone wouldn't help either.
|
|
#
¿
Jan 9, 2017 00:33
|
|
|
Mr Shiny Pants posted:I saw a talk once that talked about transforming OOP minded RFCs to Actor-Model architecture. Are there any resources that you know of that can help with translating OOP designed code to more of an actor based approach? Do you have any specific RFC in mind?
|
|
#
¿
Jan 15, 2017 22:14
|
|
|
Mr Shiny Pants posted:Of the top of my head, the guy was talking about how you would implement a webserver in Erlang and instead of one process that handles the connections and kicks of threads you would have a process for every connection coming into the server. The thing with the actor model is that it can feel like a better Object Oriented environment than actual OO languages, but that's not a great way to structure systems. That way leads madness and frustration. The idea for Erlang is really to use processes to hold independent program units. That's the major difference with OO, where all pieces of data you have tend to materialize as objects. If you have a program that operates on a data structure (they pretty much all do!), you don't represent the data structure as a process. Instead you represent them as regular pieces of data that you operate on functionally with the functional subset of Erlang, in a good old sequential/declarative program. The level of concurrency and processes will come around when you take a given data flow or continuous piece of living state, and want to give it its own place to run. So yeah, for a webserver, there's two traditional designs depending on the server you use. In either case, a process is started that will listen on a socket. Then the split takes place: One one side (yaws, mochiweb), the server spawns a pool of processes that act as acceptors. Once a connection is accepted, the process itself becomes the connection: it will defer itself to custom code by the programmer based on a regular interface to handle requests and responses. A worker elsewhere receives a message asking to spawn a new acceptor, and the pool is maintained to a roughly stable size. There is a serialization point to spawn new acceptors On the other side (cowboy), the server spawns a pool of process that act as acceptors, but whenever a connection is accepted, they hand it over to a new process that will handle the request. The pool remains fixed in size, but if you want to implement a limit on the number of web workers, you require more complex coordination with the process pool, and more calls to shift control of sockets to processes (any process can send to a known socket, but only one may listen at a time, so they have a concept of ownership). In all cases, you end up using one process per connection. Pipelined or keepalive requests over a single connection can share the same local cache and state, though most servers don't make this explicit.
|
|
#
¿
Jan 17, 2017 03:56
|
|
|
Pollyanna posted:So the common idea of "HTTP is stateless and you must assume the connection and requests are too" still holds, but individual connections are considered their own processes? What advantage does this have over the previous one-process model? I can see the obvious picks of parallelization, but there's also concerns like database access that could limit the benefits from that...I'm not a web dev genius, just a monkey, so maybe I'm missing something. As a general system architecture, too, I can see how it'd be useful, but I still need some practice and experience to really grok it. The process model for cgi and fcgi still makes sense, it's just that it's a ton cheaper to run in a VM like Erlang's. Database pools and access do represent a similar problem, except that now, the pool is usually a tweakable and configurable thing that lives within your VM along side the app. One of the benefits there is the ability to efficiently have bidirectional communication with the pool, on your own terms. That being said, the problems of contention, control flow, and back pressure don't change. They just take a different form, one that may be more explicit (I wrote on this at http://ferd.ca/handling-overload.html) Overall you can think of a large Erlang system of the way you could build a microservice architecture, but with all the apps living within one VM under a single memory space in a single runtime. There's huge benefits from having the proper isolation and architectural divide, but you don't have to pay the cost of the network overhead in most cases.
|
|
#
¿
Jan 17, 2017 23:32
|
|
|
Mr Shiny Pants posted:This also how I am imagining the system, so you could say the Erlang VM is kuburnetes? And a process is a docker instance? Ehhh... analogies like that can help make things click, but you can't program by holding them like a mantra or to that degree of precision. Erlang was made open 19 years ago, and existed for 30+ years before. It has grown in isolation from these things for the most part, and mostly came before them (OO has had many incarnations, so don't hold me to too much precision there). The patterns it uses and allows are disconnected conceptually and come from different motivations. While it may help to compare broad properties to OO (encapsulation and message passing) and to microservices (isolation and separation of concerns), you can't really bring things much further than that, and sooner or later, it's easier to just abandon preconceptions and just dive in. The blog post / presentation I linked is as abstract I've managed to word things without losing too much, but nothing would beat getting some experience or looking at existing systems or libraries.
|
|
#
¿
Jan 19, 2017 00:02
|
|
|
Mr Shiny Pants posted:Cool, I've watched some talks about Erlang and I think I got a good idea how it conceptually works. Elixir and Phoenix seem to be going together the way that Ruby and Rails ended up an indistinguishable thing for most of their respective communities. Elixir has a few niceties and capacities it adds on top of Erlang (protocols are the biggest one), but by all means both maintain very similar semantics overall. I think the divide that seems to happen now between both communities is that Elixir gets to be used for web and web-related stuff, whereas Erlang keeps seeing more usage at the infrastructure level. There's of course outliers in both directions, but I wouldn't be surprised if <10% of Elixir's usage was non-web stuff, and <5% of Erlang's usage was primarily web stuff (excluding bolting on HTTP APIs on an otherwise non-web service) While the Elixir community is also still not on solid ground when it comes to OTP -- that stuff takes a while to internalize as a group and I'm not too worried about it -- it still entirely applies and remains valid as a set of design rules, so I'm pretty happy about that.
|
|
#
¿
Jan 19, 2017 14:04
|
|
|
Shinku ABOOKEN posted:What *is* OTP anyway? A design pattern? A library? An API? OTP is basically the evolution of all the patterns that kept being rediscovered at Ericsson in their big products in the 90s, and then their continuous updating since then. They found out common design patterns (how to do request/response, how to encode state machines, how to fan-out events, how to handle failures through supervision, and so on), and then turned them into core libraries for generic/specific components. So for a stuff like a 'server' pattern, where a process holds a bit of canonical state and responds based on it to a bunch of randos sending it messages, they abstracted away the common core: sending/receiving messages, maintaining and storing state in memory, handling debug messages, tracing, suspending/resuming workflow, the usage of hooks for introspection, and so on. They did all of that into a core 'gen_server' module (called a 'behaviour'), and what you specify is how to handle messages of various types. They did this with the most common patterns, and wrapped it with the idea of supervision trees ('supervisor' is one of these behaviours). They took these supervision trees and put them into 'applications' (basically stateful libraries), and built a system of 'releases' around it that handle things like booting, restarting, shutting down, and doing live upgrades of these application and supervisor subtrees. To make a short story of it, Erlang is a very small language with processes, links, monitors, message passing, and the VM. OTP is the general development framework that specifies how you organize code, write libraries, distribute and boot them no matter the kind of industry you're in.
|
|
#
¿
Jan 19, 2017 19:48
|
|
|

|
| # ¿ Apr 29, 2024 00:48 |
|
|
Hypnobeard posted:I'm trying to create a lexer using leex in Erlang 19/Elixir. I'm having problems matching angle brackets. The lexer compiles fine, but trying to let the string ">" results in an error: That looks like Elixir syntax; Elixir strings are actually Erlang binaries by default, and are incompatible with the string module. Try binary:part/2 or one of the string module functions (starting OTP-20 the one in Erlang supports unicode properly)
|
|
#
¿
Aug 25, 2017 21:41
|
|