


|
You shouldn't use ORM's when the friction encountered because of the relational-OOP impedance mismatch is too high. This doesn't mean ORM's are bad, it means you, someone above you, or someone before you made a bad decision. Note that "too high" doesn't just mean "I had to think more about how to do this thing". You "just" need to choose the right tool for the job. Sometimes you may not know what the right tool will be so you might use sqlalchemy core. Sometimes you understand the problem space well enough that you can decide up front that some ORM will or will not meet your needs. In the general case, if you just default to Method X because you think it's a good middleground, then you're never using the best tool for the job. It's like a carpenter just taking a hammer to work because it can drive nails, pry boards, beat a hole in a wall, and scoop their potato salad for lunch. Of course, some people work on a narrow range of project types and they might never, or very rarely, benefit from an ORM or from not-an-ORM and it's just easier for them to default to whatever. IME, much of the time people say ORMs are bad they've just internalized how ORMs apply to the type of work they were doing when they formed their ORM opinion or they're parroting what their DB instructor told them in school or something like that. Some people then take this "lesson" they think they've learned about ORMs and build projects in a way or select projects that benefit from whatever they think the lesson taught them and this just reinforces what they think they know. Other people just work in a field that benefits from an ORM and then don't see the how people could not be using an ORM...or the opposite. People are very often not using an ORM when they should, or are are using an ORM when they shouldn't and everyone has Very Strong Opinions about the subject. This is a shame. Sometimes when you're using the not-ideal tool and have strong opinions about it, it prevents you from learning about, thinking about, and making the best of that tool. FWIW, with no scientific basis, no survey of my past projects, going completely by my gut impression of my career: 40% of projects I've been significantly involved in have been best served by an ORM. Rocko Bonaparte posted:Ahh I thought I automatically had all this in PyCharm but it turns out I don't. I usually run mypy in addition to using PyCharm's type checker. Neither mypy or PyCharm seem to be a subset of the other. Thermopyle fucked around with this message at 17:49 on Apr 9, 2020 |
 #
¿
Apr 9, 2020 17:46
#
¿
Apr 9, 2020 17:46
|
|


|

|
| # ¿ May 15, 2024 12:28 |
|
|
One thing to remember about the post starting this recent conversation is that the poster only provided one example. He also mentioned config values. Many python projects use a .py file as a general config file. Take Django for example. In settings.py you have a lot of plain variable assignments as key-value assignments. Some examples: Python code:That being said, I've been working on a PR for Django to bring types to settings.py. It's requiring a lot of thought to meet the needs of developers, users, and system admins.
|
|
#
¿
Apr 11, 2020 17:21
|
|
|
Dominoes posted:To me (We're getting far in subjective turf), I think in that Django example, it makes sense to expose the structure as a dict in the config file for the reasons you listed, but validate and manipulate it internally using something more robust. Yeah, definitely. Dominoes posted:That'd be a cool PR - link when it's ready for the +1s? I have literally zero code yet. It's just several pages of notes now. It will be in limbo until/if this DEP gets finalized/accepted and I can work with everyone to see whats exactly going to happen. I'm sure we're talking about many, many months from now.
|
|
#
¿
Apr 11, 2020 20:23
|
|
|
mr_package posted:I have an attrs-based app that groups bits of text together to support multiple languages. So each instance has a 'text' field that is a dictionary e.g. {"en-US": "apple", "fr-FR": "pomme"} type of thing. They might not all have the same keys right now but they are going to converge over time as everything gets translated. I want users to be able to add things at runtime so I don't want to define all the fields and push a new code version and dictionaries support this; just add a new key e.g. "ja-JP" and you have Japanese language support. I might be misunderstanding you both because I'm bad at understanding anyway and also I'm pooped, but...but would a TypedDict help you out?
|
|
#
¿
Apr 14, 2020 00:20
|
|
|
I'm glad to see a solution. Frustratingly, it's been in the back of my mind constantly since you first posted it.
|
|
#
¿
Apr 23, 2020 18:50
|
|
|
The post where I try to explain loggers. Loggers are weirdly hard to understand for something that seems like it should be simple. This stems from the fact that it's made to be very useful to Enterprise Grade applications that have very complicated logging requirements, but this makes it harder to grok if you don't have a lot of experience in that area. Don't let that put you off. Because it has a lot of features, it can be very useful for even small applications...once you learn how to understand it. The logging module is made to handle a stream of message events and each event can have different sorts of metadata assigned to it. When you log a message, it is evaluated at multiple steps to see if it should be outputted, where it should be outputted, and what format it should be outputted in. You can have multiple loggers in your application, each with a different configuration, and you can share parts of that configuration amongst different loggers. The logging module has a basic mode that you access by calling members of the logging module directly: logging.debug('blah blah blah'), logging.info('blah blah blah'), logging.error('blah blah blah'), etc. This basic mode configures a default logger called root with some basic configuration options. You could use this mode like so: Python code:code:I find myself hardly ever using this mode so I'm not going to talk about it anymore. The docs on it are straightforward once you understand the remaining part of this post. A more useful mode is to specifically create a logger like so: Python code:For example, if you have loggers named, my_project.foo.bar.baz, and my_project.foo.dork.face, you can configure the logger called my_project.foo and it will be shared by everything in bar, baz, dork, and face Ok, so now you can use this newly created logger object instead of the basic mode outlined at the beginning. Now what happens when you call logger.info or any of the other log methods? 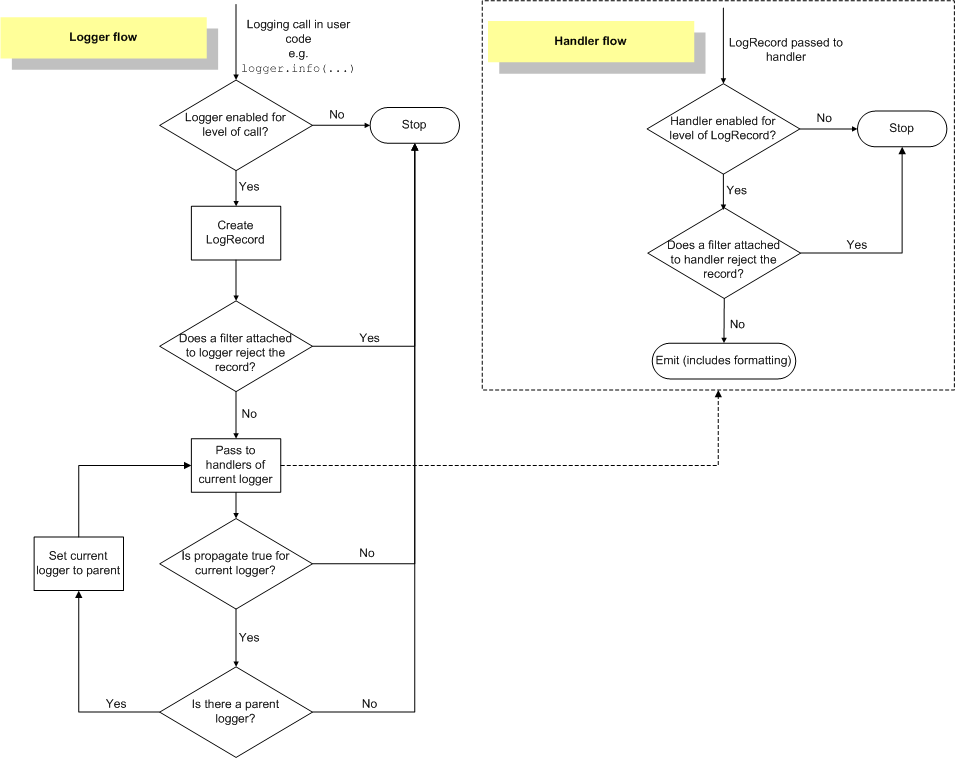 There are four basic things that happen when you log a message:
Your loggers can be configured in different ways. You can use the programmatic API: Python code:code:
|
|
#
¿
Apr 23, 2020 21:06
|
|
|
I've used this simple cached_property snippet for years, and I just noticed 3.8 added one to functools. I like to use it for things that make sense as properties but might be a little expensive to calculate if there's a chance it might be hit in a tight loop. Anyway, thought I'd share my implementation for people who aren't able to use 3.8... Python code:
|
|
#
¿
Apr 26, 2020 23:28
|
|
|
Data Graham posted:That's neat, what about expiration / cache-busting though? I'm thinking about long-lived class instances whose state changes over time, their properties would also need to get refreshed somehow. I don't do that too often, but I think I've done it in the pass with a wrapper around functools.lru_cache. edit: Oh no, wait I remember. You can force a re-calculation by deleting the property like del instance.whatever_property. That will make it re-calc on next access. So you've got to write something that stores the time it's cached and references each time you access... Thermopyle fucked around with this message at 00:27 on Apr 27, 2020 |
|
#
¿
Apr 27, 2020 00:24
|
|
|
1. With no other facts at hand, the advice is to do what is most idiomatic in Python and that's list comprehensions. 2. If you're working in an existing code base or in an organization you should match what is idiomatic in that code base or what the organization's style guides indicate. 3. If no one else is looking at the code except for you, it's tempting to do whatever you want. I'd caution that it's bad to build up habits and preferences at odds with the larger Python universe. 4. Sometimes it's OK to break idioms, conventions, and guides if it makes a big difference in readability for a specific case.
|
|
#
¿
Apr 28, 2020 19:24
|
|
|
OnceIWasAnOstrich posted:I have what is essentially a ~100gb Python dictionary, 200 million 4kb float32 arrays each with a string key. I need to provide this to some people who will be using Python to randomly access these. This is a better plan than having them generate them on-demand because they are costly to generate (~half a second to generate a single array). Would pickle or shelve work for you? I haven't used them for that much data... Both are in the standard library. Of course, the users of your data have to trust you since pickle (and shelve since it uses pickle under the hood) can run arbitrary code when unpickling.
|
|
#
¿
Apr 30, 2020 20:58
|
|
|
pickling is fine if you're using it correctly. I don't think I'd use it for this just because it's so big.
|
|
#
¿
May 1, 2020 02:41
|
|
|
Malcolm XML posted:the valid cases for pickling that don't lead to tears is vanishingly small Really there's technically better ways to do almost everything that pickle does. It's surprisingly often that the betterness of these other ways is trumped by the fact that pickle is in the standard library and takes almost zero time to implement. You should default to the easy, low-cost way and re-evaluate when it becomes apparent you need something more. You've lost almost nothing and quite possibly saved yourself a lot. Of course, this requires knowing what pickle does and it's shortcomings. There's a very wide gray area where it just might work fine.
|
|
#
¿
May 1, 2020 15:55
|
|
|
One offs are surprisingly common. I certainly wouldn't advocate for using it for anything other than that. One offs like distributing a data structure to a handful of known systems is a perfect use case of pickle. Claiming that pickling is bad and dumb isn't really the right way to say it if only because it's obviously wrong depending on the use case. Claiming that pickling is bad and dumb for X, Y, and Z is a much more defensible position. The standard library is an awful mess. However, adding dependencies is quite often worse. A big problem with pickle is that it's so easy to use that 9 times out of 10 that it gets used it's the inappropriate tool. This colors everyone's perception of the thing. Thermopyle fucked around with this message at 18:48 on May 1, 2020 |
|
#
¿
May 1, 2020 18:39
|
|
|
Malcolm XML posted:This is exactly why it's bad and dumb, e.g., if it has to have a giant red box in the docs calling out insecurity it probably shouldn't be shipped in the stdlib. I think that stupid red box is a consequence of the rest of the pickle docs being bad and not a consequence of something bad being included in the stdlib. Anyway... Malcolm XML posted:I think it's completely worth calling it bad and dumb in general. A more accurate description would be "don't use it unless you're very sure of the consequences". I think we'll just have to disagree on this one.
|
|
#
¿
May 1, 2020 23:35
|
|
|
Yeah, having to use PYTHONPATH is a code smell.
|
|
#
¿
May 30, 2020 00:04
|
|
|
QuarkJets posted:If you use venv or conda then you're using PYTHONPATH. By this definition most everything you do on your PC you're setting different environment variables because somewhere in the machinery of the deployment or build something somewhere is setting them. Of course, I'm talking about having to set PYTHONPATH yourself. In most cases where people set it themselves there's a better way to do what they're trying to do. I'm sure there's some valid cases, but they're not usual and typical...which is why I said "code smell" and not "you've hosed up by doing it". Thermopyle fucked around with this message at 02:05 on May 30, 2020 |
|
#
¿
May 30, 2020 02:02
|
|
|
QuarkJets posted:Most things that you do on a computer aren't setting your PYTHONPATH, that would be pretty unusual. I'm not sure how that's relevant? I didn't claim that. QuarkJets posted:But it's pretty normal to set that while you develop stuff, because git repos aren't usually located in the default search path. So setting it as part of an installation step is code smell, but setting it because you haven't installed some code to a standard location yet is pretty normal Yes, it's fairly common but it's also the wrong way to do it. editable packages exist for a reason.
|
|
#
¿
May 30, 2020 06:32
|
|
|
QuarkJets posted:Why does that make using PYTHONPATH wrong? Hmm, calling something a code smell doesn't mean it's wrong, per se. It doesn't mean you've broken something. It means its a warning that others should watch out for wrong things. If someone is commonly telling others to set PYTHONPATH or commonly setting it themselves, it's evidence that they're not careful about what they're doing. There's facilities specifically built for many of the common reasons PYTHONPATH is used and they're almost always better. In many of the cases where these other facilities are not obviously and immediately better, they're better in the long run. For example, there's an extensive history of various python packaging and build tools being broken by users editing their own PYTHONPATH that can be completely avoided by just using the appropriate tools. Now, you might say, "I'll just be very careful" and that might work great! But it's still a smell. We should be writing software that is resilient to failure and also, importantly, signaling this to others. Seeing someone choosing the fragile, brittle course when there are other options should make you wary about what else they've done. It's just a smell. Everything might be (probably is!) fine. It's just an indication. There are certainly times where PYTHONPATH editing is the correct thing to do.
|
|
#
¿
May 30, 2020 07:21
|
|
|
QuarkJets posted:
Like I said, there's nothing wrong with it in the sense that you'll break something immediately and obviously. Phobeste posted:Well, I think the point he's making is "you could do that but there's better ways and not knowing those ways might mean you don't know other best practices" which is true but kind of a dickish thing to snidely assert without actually providing an alternative. Your post basically covers my answer. (Except I did tell him to use editable packages already.) Thermopyle fucked around with this message at 19:38 on May 30, 2020 |
|
#
¿
May 30, 2020 19:35
|
|
|
Rocko Bonaparte posted:My own take is that PYTHONPATH during development is totally fine since your source is God-knows-where, but you should try to deploy in a way that doesn't require it when releasing. Well that's part of it. Why is you source God-knows-where and why can't you pip -e it?
|
|
#
¿
May 31, 2020 00:48
|
|
|
QuarkJets posted:
Addressing that scenario is exactly why editable packages, aka pip -e and the like, exist. Your method works and doesn't break anything...much like using camelCase method names definitely works and doesn't break anything. However, when I see a developer using camelCase it makes me wonder what horrors lie beneath. Maybe there's nothing else and everything is fine. But it's a code smell that makes me wonder.
|
|
#
¿
May 31, 2020 19:01
|
|
|
CarForumPoster posted:I didn't know that camelCase was the name for this. I've had applicants that do this in their Python coding interviews or on their githubs and I noticed the same thing. snake_case is the Python convention! You probably shouldn't use PascalCase or kebab-case either. 
|
|
#
¿
May 31, 2020 19:34
|
|
|
Thermopyle posted:You probably shouldn't use PascalCase Well, except for classes.
|
|
#
¿
May 31, 2020 20:56
|
|
|

|
| # ¿ May 15, 2024 12:28 |
|
|
Because I keep posting about the subject it probably seems like I care more about PYTHONPATH than I do. What I actually do care about is clear communication, so here we are. I just barely care enough about PYTHONPATH to have made the offhanded initial post. I also care a lot about the issue and usefulness of best practices and conventions in general, so, dear reader, if you don't care about PYTHONPATH just pretend I'm talking about any best practice or convention. TLDR: If you accept that good, high-quality code doesn't encourage the usage of PYTHONPATH and If you accept that the ideal project doesn't encourage the usage of PYTHONPATH...then my assertion is that you should signal to other developers that you're delivering good, high-quality code by not using PYTHONPATH (or hiding your usage of it). This is not to show off, but to help them better manage the limited confidence bandwidth they have. QuarkJets posted:You still haven't explained why you feel like using PYTHONPATH is a sin, I feel like I have.  So, I'm not sure how to explain this another way so to me it feels like I'm just saying what I already said, but I'll try again: The reasons to not use PYTHONPATH are like 90% social and 10% technical. (As an aside, I have a feeling that describes a large portion of so-called programming problems) I do not think I'm superior to any developer for using PYTHONPATH. That's ridiculous. I guarantee there's tens of thousands developers telling everyone to use PYTHONPATH who are more competent than me. I'm barely competent. A big thing that keeps me treading water is all the developers around who follow best practices and I don't think you're going to find many project managers for leading projects who are going to say using PYTHONPATH instead of editable packages is a best practice. It's not that I prefer using pip -e instead of PYTHONPATH, it's that most good and well maintained code, projects, project contribution guidelines, workplace guidelines that I've been in contact with recommend editable package approach and most of the times I see PYTHONPATH recommended it's people throwing poo poo at the wall. I mean, maybe my experience is not representative, but that's all anyone can go by. I have spent a lot of time consulting on related issues so my gut tells me I'm exposed to a wider variety of projects than your average developer, but who really knows? This paragraph is only tangentially related to my point, but I think it's probably the information you're looking for: The reason editable packages exist is largely because setuptools/distutils/pip/etc have all had to deal with bugs stemming from people setting PYTHONPATH. That's the technical reason to use editable packages...they're more robust. If you want more details you'll have to go dig through the corresponding mailing lists from years ago when I was a regular on them. I don't remember all the details at this point. Manually setting PYTHONPATH is less than optimal because it's an indication that the author isn't aware of all the built-in facilities and conventions that are out there. It's not similar to choosing datetime instead of arrow or whatever. It's more akin to someone using some a for loop to concatenate each letter of a string instead of just using + without any comments about why they did it that way. I prefer to use the tools python provides...but more importantly I prefer other developers to demonstrate they grasp the environment they're working in because if I have to use their code I'm already accepting a boat load of stuff on faith. Maybe they had a good reason to. Probably their code is fine. Likely their code is better on all dimensions than anything I could write. But, it raises questions from the get-go and that's a disservice to users of your code. Sometimes I use PYTHONPATH because I'm lazy, but I don't tell anyone else to use PYTHONPATH nor will you find it being used by me anywhere another developer might encounter it. You could say that using PYTHONPATH isn't part of my "public API" . APIs that expose unconventional interfaces make me worry about the implementation. (hello half the stdlib...much of which is weird but works fine) And now you've made my expose my laziness on my public API, thanks a lot! FYI, you shouldn't use case conventions because they're written in a PEP, you should use them because they're conventions and conventions are important stuff! PEP8 just codified things that were already convention. In the days prior to PEP8 it was not unreasonable to do a double-take at code using camelCase. There's many things that aren't written in a PEP but are conventions you should avoid breaking without good reason anyway. It's already so hard to work on code. Developers should do a things to signal competence. Increasing the confidence your coworkers can have in your code is valuable. QuarkJets posted:and the answer boiled down to "well it isn't, really, but I prefer it". I mean, in some sense everything you want the world to be is only that way because you prefer it. I prefer it because I think it makes the world work better. QuarkJets posted:Then they came back around and compared using PYTHONPATH to violating PEP8, Like all analogies the comparison only goes so far and I feel like you should've read it more charitably. I probably won't post about PYTHONPATH again, but the utility of best practices and conventions are near and dear to my heart and I can talk about them a lot. Many of my favorite problems nowadays are less technical and more about improving the stuff I talked about in this post.
|
|
#
¿
Jun 1, 2020 02:50
|
|