- Adbot
-
ADBOT LOVES YOU
|

|
|
#
¿
May 10, 2024 06:41
|
|
- mobby_6kl
- Aug 9, 2009
-

by Fluffdaddy
|
This is what I dont get about this argument. Maybe I don't understand existing copyright law properly. I probably don't!
But viewing copyright work is not a violation of copyright anywhere that I know of. Only making things that could qualify as copies of it - and specifically only a subset of that, or the internet would be fundamentally illegal for far more obvious reasons than an AI system trained on copyright work would be. I mean I guess you could argue the internet at large IS illegal even within those constraints but we just don't enforce it because it's too useful, but then I don't see how we won't end up coming to the same conclusion for AI.
Where is the actual violation that these AIs are doing being committed, and would removing those actual violations actually have any real impact on the development of AI?
As you say, the models use a lot of copyrighted data for training. So the first question is whether or not this counts as fair use.
The models also retain some of the training data, in compressed form, in a way that can be reproduced fairly close to the original, e.g.:


Does storing and distributing this count? How much is the company vs the user's responsibility? I dunno. There's a pretty good article on this here:
https://arstechnica.com/tech-policy/2023/04/stable-diffusion-copyright-lawsuits-could-be-a-legal-earthquake-for-ai/
which also has an interesting comment about contributory infringement that I'm not going to try summarizing:
quote:
The Betamax ruling is actually illustrative for why these AI toolsspecifically ones that are trained to reproduce (reproduce?) identifiable Mickey Mouse and McDonalds IPmight be contributory infringement. Its a good contrast ruling.
What do I mean?
The Betamax case found that Sony wasnt liable for contributory infringement, which is a real thing on its own, liability for knowingly inducing or facilitating copyright infringement by someone else. Sony was accused of inducing infringement by making and selling a device specifically intended for making copies of (recording) copyrighted audiovisual material (broadcast TV) with knowledge of this infringing use.
The SCOTUS ruling in the Betamax case didnt eliminate or diminish contributory infringement. Instead it found that the alleged direct infringement that Sony was supposedly inducing, wasnt infringement at all. The activity Sony was inducing was just an individual person recording broadcast TV contentwhich they were permitted and even encouraged to watch, for freeso they could enjoy it for free later. This is called time-shifting.
And the Betamax ruling said time-shifting by VCR owners was fair use.
So core of what let Sony off the hook, was that what Sony was trying to induce, was a significant non-infringing use. And it was non-infringing because the allegedly infringing use was just a mere time-shift of a use that the public was permitted and encouraged to use for free.
The closest valid analog I can think to this is, Google image search. You put in what youre searching for, it shows you thumbnails of images on a site similar to what youre looking for, with a link to the site / page where its located. Its helping you find images that people want you to directly view on their own website anyway. And making small thumbnails demonstrates their intent is to direct people to the copyright holders site to enjoy the content. So making thumbnails of Getty Images should be fair use, if its just helping people find the page on Getty Images where that image is displayed. Thats similar to Betamax, theoretically.
Butand heres the differenceGetty Images has images on its website for the purpose of selling you access rights to the image. Those images are heavily watermarked and limited in resolution, and shown to people to give them an idea of what they can license, and the ability to buy a license. They are not meant to be viewable for free just to enjoy the full original image, let alone to make copies from, or integrate those copies into art youre making.
But thats what these AI tools do. They enable people to create (relatively) high-resolution artwork that substantially incorporates and reproduces Getty Images or other copyright owners material. And it removes any watermarks or attribution in the process. And it can reproduce copies that are drat close derivatives to copyrighted works.
Unlike Betamax VCRs, this is doing far more than reproductions of something that people were encouraged to watch and enjoy for free. Unlike Google image search, this is not just helping people find images they can go access and enjoy in the manner the original copyright holder intended.
This is knowingly consuming copyrighted material with the knowledge it could be used to create derivatives of copyrighted works. And that is its primary use offeringif theyre offering something trained on copyrighted works, theyre literally offering to help you make derivatives of those copyrights. And while they put a lot of effort into making this AI model able to do that, it sounds like some of these AI creators arent putting much care or effort into teaching it how to not create blatantly infringing derivatives.
That sounds like it could easily be contributory infringement to me. 
|
 #
¿
Apr 9, 2023 19:30
#
¿
Apr 9, 2023 19:30
|
|
- mobby_6kl
- Aug 9, 2009
-
by Fluffdaddy
|
I don't think it "retaining" some of the training data is true in any meaningful way, but I think the meaningful component this is that it can clearly reproduce it.
But... I don't know, that argument doesn't seem to hold much weight. The betamax players could also be used to infringe copyright - Sony wasn't found guilty of inducement because the device was not "specifically intended for making copies of (recording) copyrighted audiovisual material" but rather to be used for a legal purpose. Intent seems to matter, then, and I don't think there's any real argument to be had that the "intent" of these AI tools is to allow users to recreate specific copyrighted works - you can, in the same way a betamax player could, but in the same way that wasn't sufficient to find it was inducement, I don't see how it could be here?
I got a good chuckle out of this, so thanks.

https://arstechnica.com/information-technology/2022/09/better-than-jpeg-researcher-discovers-that-stable-diffusion-can-compress-images/
Is it different if SD can immediately give me "Ann Graham Lotz" but requires five kb of data for the alpaca? Is one "retained" while the other is "reproduced"? 
I don't really have an answer or even a particularly strong opinion, and also IANAL obviously.
In any case though, the whole thing could obviously be avoided by only using public domain or licensed data, for images or text. Though I feel it'd be more of a limitation for the language models.
|
|
#
¿
Apr 9, 2023 21:22
|
|
- mobby_6kl
- Aug 9, 2009
-
by Fluffdaddy
|
It'd be pretty trivial to have the drone find and shoot targets by itself, you don't need any fancy AI for that. Just a basic neural net to classify the potential targets (like a consumer DJI drone can track a person). Then just have it go from target to target and shoot/drop a grenade on it.
|
|
#
¿
Dec 25, 2023 04:13
|
|
- mobby_6kl
- Aug 9, 2009
-
by Fluffdaddy
|
Is it just me, or is this less of an "AI grifting story" and more of a "grifters who happened to use AI" story? Like, maybe it lowered the amount of effort required, but all of the grifting elements could've easily been done before ChatGPT existed. They would've had to do a GIS/Pinterest search for the picture instead of entering an AI prompt.
That said the generative AI stuff will make it easier and cheaper. You could GIS but you'd need to find a bunch of images that show what you want to grift, are consistent, are not recognizably an existing thing, or reverse-searchable. One could also subtly or not so subtly enhance images of the real location/product so when people do show up, it's vaguely similar to what they expected, just a bit (much) shittier.
Same with the scripts, you could write that stuff yourself or steal it somewhere of course, but you could more easily generate the specific scripts you need by asking ChatGPT.
|
|
#
¿
Mar 1, 2024 19:32
|
|
- mobby_6kl
- Aug 9, 2009
-
by Fluffdaddy
|
I finally had a reason to try ChatGPT for code. Told it to replace a function that printed sensor values over serial with one that saves it in a database using the SimplePgSQL library and it came up with this:
C++ code:void store_temperature(float temperature){
SimplePgSQL pgsql;
pgsql.setHost("192.168.0.1");
pgsql.setUser("temp_user");
pgsql.setPassword("Pass123");
pgsql.setDatabase("temp_log");
if(!pgsql.connect()) {
ESP_LOGE(TAG, "Failed to connect to PostgreSQL server");
return;
}
char query[100];
snprintf(query, sizeof(query), "INSERT INTO temps (temperature) VALUES (%.2f)", temperature);
if(!pgsql.query(query)) {
ESP_LOGE(TAG, "Failed to execute SQL query");
pgsql.close();
return;
}
pgsql.close();
}
The problem is that this isn't how the library works, like at all. Looking at the example, it's supposed to be configured like this:
C++ code:WiFiClient client;
char buffer[1024];
PGconnection conn(&client, 0, 1024, buffer);
conn.setDbLogin(PGIP,
user,
passwordDB,
database,
"utf8");
if (conn.status() == CONNECTION_OK) {
//stuff
}

E:
Claude 3 is out, claims to be better than everything in every way, several times by exactly 0.1%
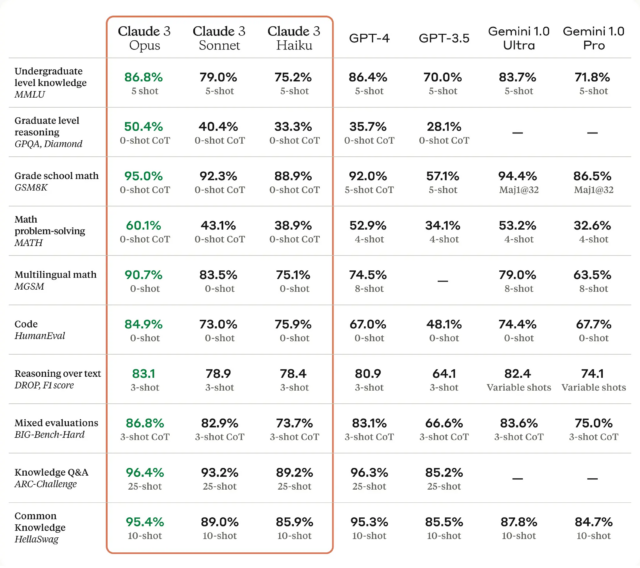
https://arstechnica.com/information-technology/2024/03/the-ai-wars-heat-up-with-claude-3-claimed-to-have-near-human-abilities/
Whether or not that's really true is another matter of course.
mobby_6kl fucked around with this message at 22:38 on Mar 4, 2024
|
|
#
¿
Mar 4, 2024 19:03
|
|
- mobby_6kl
- Aug 9, 2009
-
by Fluffdaddy
|
It's real as in it's a real demo aimed at bringing in VC money.
The robotics are by far the most impressive thing. Everything on top is stuff we've been seeing for a while.
Speech to speech "reasoning" is actually trivial now with LLMs, just take any off the shelf speech to text, slap the text into the prompt, do the reverse on the way out.
Their previous demos on their channel are all more impressive from a technical stand point, but a talking robot captures peoples imaginations.
Somehow I missed that OpenAI was doing robotics, I think this would explain Musky's sudden obsession with making a Tesla robot.
|
|
#
¿
Mar 14, 2024 12:15
|
|
- Adbot
-
ADBOT LOVES YOU
|

|
|
#
¿
May 10, 2024 06:41
|
|
- mobby_6kl
- Aug 9, 2009
-
by Fluffdaddy
|
How good are the LLMs at being multilingual, like how a person raised in a multilingual household would be?
Been thinking about this because the other day I was watching TV and there was a random scene where the language switched to [non-English language]. I understand and speak this language, but there was a word I didn't know.
I said "Siri, what does [foreign word] mean in English?" and Siri couldn't understand that I was switching language for that word. I would have accepted an explanation in English.
I tried "Siri, [in foreign language: what does this word mean in English]?" and Siri transcribed my words into the closest approximate English syllables I guess, which was gibberish. I would have accepted an explanation in the foreign language.
I asked about this in the iPhone thread since it was a Siri question and I know Siri isn't a LLM (right?) but it's spurred some additional discussion about how Siri sometimes can't distinguish perfectly between numbers like "15" and "50" for some people.
This is just an example. But in real life real world, when I talk to my family or some friends we do switch language like that and it's completely natural/normal.
Should clarify that this is in the context of voice assistants.
Here's chatgpt 3.5:
quote:
Q: What does "ernðhrungswissenschaftler" in German mean?
A: "Ernðhrungswissenschaftler" is a German word that translates to "nutritionist" in English. It refers to a person who specializes in the study of nutrition and its effects on human health. Ernðhrungswissenschaftler typically work in various fields related to nutrition, including research, education, counseling, and public health.
This is something I typed like that though. I think one issue with Siri might be that it's doing voice recognition and of course tries to match it to the most likely English word.
|
|
#
¿
Mar 14, 2024 13:52
|
|



")
 #
¿
Apr 6, 2023 16:29
#
¿
Apr 6, 2023 16:29



