


|
I'm happy to talk about async design! Thanks for the comments, Malcolm and others. I love the chance to talk about language design. Looking back, I think we made the right calls at the time, and right now I'd make mostly the same calls again...Malcolm XML posted:Stupid things like configure await and having to manually spill variables (!!!!) to reduce allocations is just tedious ConfigureAwait? There's a straightforward choice: either optimize the design for app authors (by returning to the original thread/context after an await), or optimize the design for library authors (by continuing after the await on whichever thread/context you happen to be). We chose to make things easier for the app authors, because there are more of them and because they're less expert. Within the .NET framework, they use .ConfigureAwait(false) everywhere. Using the new "Roslyn Diagnostics" feature (as in Dev14 CTP1) you can add custom rules to your project, including e.g. enforcing that every await has a .ConfigureAwait() after it. Within VS, actually, they don't enforce this... the people there came up with a different pattern they think is more robust. They're still refining it. Maybe in a month or so I'll be able to post what they've done. Manually spill variables to reduce allocations? There's a straightforward choice: either allow await in arbitrary places e.g. "using (var x = await GetFileAsync())" and deal with the consequences, or do what F# did and only allow it in two places "do!" and "let!". We chose to allow it everywhere because this was the biggest complaint in F#. We can still optimize the compiler further to make it more efficient when you use await in weird places, e.g. "myStructArray[await i].f(await j)", and indeed we've already made improvements in await codegen for Dev14 CTP1, but it's a case of diminishing returns. Is it tedious to write awaits in a way that don't involve spilling? Not really. You can still write "var x = await <expr>" and "await <expr>" and "using (var x = await <expr>)". It really is only the more esoteric code patterns, ones that usually don't pass code review, that involve spilling. quote:Also it conflates a CPS rewriting sugar (await) with parallelism which honestly is more confusing. Something along the lines of haskell async or parallel might have been cleaner Conflate CPS with parallelism makes it more confusing? I strongly disagree. The whole world has been on a stupid mistaken bender over the past decades, stemming from the mistaken belief that asynchrony means multiple threads. I know... I suffered through it for my undergrad, PhD and postdoc, and saw countless research careers stupidly wasted on this misconception. About half the people still don't get it, and write bad (inefficient) code as a consequence. Look, if you're in a restaurant and need to serve two tables, do you hire TWO waiters? No. You use the same one cooperatively for the two tables. It's an easy enough concept in real life. It should be easy in code. It will be easy to people who are brought up thinking this way (including node.js developers!) quote:I just don't think it's at all clear how async await works behind the scenes and how much control you have over it: the actual generated code is not even CPS it's a funky state machine with a bunch of gotchas. The semantics of await are precisely "CPS with a one-shot continuation", no more, no less. The "funky state machine" is as funky as it needs to be to optimize performance, no more, no less. The only gotcha I can think of is if you write a custom awaiter that's a mutable struct, but mutable structs are always dodgy. Here are two blogs I've written with more information about "behind-the-scenes". They're on my blog not part of official cleaned-up MSDN documentation because honestly they're needed by almost no one except Jon Skeet to set brainteasers about. http://blogs.msdn.com/b/lucian/archive/2012/12/12/how-to-write-a-custom-awaiter.aspx http://blogs.msdn.com/b/lucian/archive/2013/11/12/talk-async-codegen.aspx quote:It needs some nicer combinators and good spec of its semantics Combinators? Here I think you're way off the mark ") You should compare "await" to "callbacks". Awaits are COMPOSITIONAL with respect to the other operators of the language in a way that callbacks are not. The word "compositional" comes from computer science theory... what it boils down to in practice is that with callbacks you can't continue to use your familiar try/catch blocks, or while loops, or for loops, or even the goddam SEMICOLON operator. You have to figure out other weird ways to encode them. Callbacks are not compositional with respect to most of the language operators. By contrast, await is compositional with respect to them. You should compare "await" to "callbacks". Awaits are COMPOSITIONAL with respect to the other operators of the language in a way that callbacks are not. The word "compositional" comes from computer science theory... what it boils down to in practice is that with callbacks you can't continue to use your familiar try/catch blocks, or while loops, or for loops, or even the goddam SEMICOLON operator. You have to figure out other weird ways to encode them. Callbacks are not compositional with respect to most of the language operators. By contrast, await is compositional with respect to them.As for the combinators? They're all present in Task.WhenAll / Task.WhenAny / Task.Delay / ... Indeed the whole great thing about async/await is that, through the Task type, it has such a plethora of great combinators! TPL Dataflow! All of them! As for a spec of semantics? With Neal Gafter's help (of Java fame) I wrote the VB language spec for async+await and I think I did a pretty good job. Mads wrote the C# spec for it and also did a pretty good job. Please let us know if you think it's underspecified. Bognar posted:I really like what async/await gives you, but I do agree that there are some nasty hidden gotchas. My main complaint is that you're not able to easily call an async method synchronously. Doing that is basically a recipe for deadlocks, but what option do I have if I'm not running in an async ready context (e.g. console app)? This forces most libraries to expose both synchronous and asynchronous method calls which just pollutes their APIs. If calling asynchronous methods synchronously was easy then we could get rid of this silly *Async duplicate method convention and just expose async methods. What you're seeing is an underlying "gotcha", that async+await makes more manifest. In the case of a console app, I personally just do this: code:http://blogs.msdn.com/b/pfxteam/archive/2012/04/13/10293638.aspx We discussed whether or not to make async console apps easier to write, by providing that message-loop by default, but there's no good consensus on how exactly it should behave, so we didn't. Libraries should not generally go around offering both sync and async versions of their APIs, and indeed most don't... http://channel9.msdn.com/Series/Three-Essential-Tips-for-Async/Async-Library-Methods-Shouldn-t-Lie Malcolm XML posted:They tried to get monads in the language with linq and it was ok but I have rarely seen generators (and the difference between Ienumerator and ienumerable is subtle and almost always you actually want the former) Now they've gotten a monad that isn't really a container and in order to sneak it in without the ability to have do-notation they put in await which manually performs CPS and then optimizes it out by using a state machine analogous to yield return Exposing monads to programmers never makes their lives easier! No matter how many times Erik Meijer says it! Same goes for the rest of category theory! (I spent many hours struggling through Benjamin Pierce's book "Category Theory Made Simple So That Even Dumb Computer Scientists Can Understand It", and attended category theory seminars at college, and roomed with a category theory PhD friend, and I still don't buy it...) quote:And then there's synch context which is really goddamned subtle and even Jon loving skeet says he doesn't really understand it so how do you expect workaday devs to diagnose why deadlocks are happening in something they were sold as the best asynchronous pattern? It's really not hard to avoid deadlocks. Just stop using .Wait() and .Result. Heck, write a Dev14 CTP1 analyzer plugin to enforce this if you want! Deadlocks aren't a significant problem in the wild. In my opinion the more significant problems are (1) re-entrancy bugs, (2) people failing to understand the difference between CPU- and IO-bound code. quote:I wanna say if they dropped the async void compat layer and made it so that async behaved more like Haskell async by using speculative parallelism it might be better Speculative parallelism? A huge dead end, based on the misconception that having lots of your codebase be multicore-able is somehow worthwhile. Turns out it's not. We also pursued other similar approaches, e.g. doing memory heap shape analysis to discover which methods can be executed in parallel. Wasted a good dev for a whole year on it. In the end, you actually get the bulk of your parallelization benefit from just the small computational inner-loops in your code, the ones that iterate over large datasets. And these are best expressed in domain-specific ways and coded by experts, e.g. PLINQ, or calling into a lock-free sorting algorithm, or similar. Trying to put multithreading (implicit or explicit or "hinted at") into the rest of your code gives negligible performance benefits, but at huge cost in terms of bugs and race conditions and mental complexity. Not worth pursuing. Malcolm XML posted:F# had async workflows, which are really nice and much better for a lot of async stuff than the TAP :http://tomasp.net/blog/csharp-async-gotchas.aspx/ We started from F# async workflows, fixed up the chief complaints with them, aggressively improved their performance to within an inch of their lives, and then made the concessions needed to bring async into the mainstream. VB/C# async is the result. From Tomas' blog... Gotcha #1: This is the point that C# async methods don't yield control until they hit their first not-yet-completed await, while F# async methods yield immediately. We did this very deliberately because it makes await vastly cheaper: http://channel9.msdn.com/Series/Three-Essential-Tips-for-Async/Async-libraries-APIs-should-be-chunky In any case, both the F# and the C# code are ugly for mixing blocking and async stuff in them. This isn't the way anyone should be writing code, and Tomas is wrong to call it out as a benefit of F#. Gotcha #2: Out of date. The C# and VB compilers both warn about the failure to await. Gotcha #3: The fact that we allow async void. Tomas trumpets it as an achievement that you have to write 8 extra lines of pointless boilerplate to use async in real-world code. I don't think that's an advantage. The right solution is (as we did) allow async void as a painful concession to back-compaq. On a project-by-project basis you might want to opt in to more aggressive compile-time warnings about it; that's what Dev14 CTP1 diagnostics are all about. Gotcha #4 and #5: The problem that in C# an async lambda might be a void-returning async, if it's passed to a parameter of type Action. Yes this is a shame, but it's an unavoidable consequence of earlier design decisions in C#. And in any case, like he shows with Task.Run instead of TaskFactory.StartNew, the solution is always simply to use the more modern APIs whose overloads are designed to be async-friendly. (alas this doesn't work with WinRT which isn't technically able to have such async-friendly overloads for irritating reasons). Gotcha #6: The fact that we used the Task type, which has blocking Wait method on it. Sure. But the advantages were huge of buying into the whole Task ecosystem, and its many powerful combinators, and these benefits were TOTALLY worth it.
|
 #
?
Jun 26, 2014 06:34
#
?
Jun 26, 2014 06:34
|
|

|

|
| # ? May 3, 2024 00:46 |
|
|
Deus Rex posted:Let's be clear about what you're saying here - TFS is free up to 5 developers until you have to purchase a support contract from some TFS consultant to figure out how to make it work. TFS once it's set up is really straightforward. What you need to make sure is that you're 100% confident with how you want to work with it prior to setup. We changed work item templates recently, and that was a BITCH and meant we had to create a new project collection and lose all of our source control history. Why, why, why is source control so indelibly matted into work item tracking. I understand losing all of the work items (which have been easily exported and remapped via Excel) but we had to super tediously recreate all our branches and do a fuckton of baseless merges to get us back working again. Also, branches. Creating feature branches in TFS is a real tedious experience, I wish it did them properly like Git. In short, don't get a support contract, hire a guy who knows what the gently caress he's doing for a couple of days before you set yourself up in an environment you will not *ever* be able to change unless you want to scrap the whole thing and start again.
|
|
#
?
Jun 26, 2014 12:14
|
|

|
ljw1004 posted:I'm happy to talk about async design! Thanks for the comments, Malcolm and others. I love the chance to talk about language design. Looking back, I think we made the right calls at the time, and right now I'd make mostly the same calls again... My main issue is that this should all be automated, by default. I dont have the bandwidth to keep up w/ the latest in async/await (this is like the 3rd time we tried this right?) AND also update all my code. Like it's a huge investment to asyncify existing code. As far as "write your own roslyn diagnostic" that's basically the equivalent of "write your own distributed mapreduce function in erlang" : a glib gently caress-you, not that you intended it as such. Best practices must be embedded within the tools y'all provide! It's why resharper annoys the poo poo out of me--I pay $14k for VS ultimate and intellisense can't compete w/ a plugin done by some dudes who have no access to the compiler or platform. Ok now to some specific stuff: 1) the mystruct[await foo].bar(await baz) issue is basically the thing applicative monads solve and with the joinad extension it's very naturally done (as with idiom brackets); having do! and let! and use! (fwiw the use/use! is significantly nicer than the using statement in C# since it doesnt force you to nest afaik) is pretty ok otherwise though 2) Category theory is just a framework for naming stuff. I have a degree in math and i do not give a poo poo about higher categories but i do care about 3-4: Functor (can you run Select in a context?); Applicative (Can you lift a value & tuple them inside a context) and Monad (can you thread results in a context?) + Traversable (not category theory!) which gives you extremely nice internal iterators F# got it right in this context w/ workflows. I certainly do not care for exposing natural transformations and commutative diagrams but the CLR is simply unable to express even the Functor pattern. 3) The speculative parallelism ends up being nice because although one would never hire a waitress per table it's really really nice to work as if you had one waitress per table! Cooperative multitasking sucks to work through, I mean The really slick part of the async package is that it allows neat ways of creating sparks (lazy futures) that are multiplexed onto Haskell green threads that are multiplexed onto OS threads which are multiplexed onto cores by the kernel as needed. This means that you can spawn a bazillion sparks and not really care about running out of memory. 4) Maybe roslyn will solve some of these problems but that's like a year away and even though cadence has stepped up to quarterly I'm surprised that a lot of these diagnostics/analyses were not shipped when async/await shipped If Simon Marlowe was not heavily involved w/ async await I will be very disappointed, that guy figured out a very natural pattern to handle multicore scaling + io multiplexing and FB poached him.
|
|
#
?
Jun 26, 2014 12:55
|
|

|
I've got a list of items, and I wish to configure sub-lists of of these items based on users configurations. I've got this idea for the moment, but I'd like an opinion on it. This will have to run when generating an ASP.NET page, and I'm worried that it'll get slow as more and more predicates are added.code:
|
|
#
?
Jun 26, 2014 15:04
|
|
|
Going crazy trying to figure this AutoFixture issue out, any ideas would be appreciated! http://stackoverflow.com/questions/24435874/automocking-properties-fails-on-abstract-property
|
|
#
?
Jun 26, 2014 17:38
|
|

|
One issue I see is that even when one predicate approves an item, all other predicates are still run on that item. This is also why you need the HashSet, because if all n predicates approve an item it will be added n times. I suggest reversing the order of your two foreach loops so that the totalItems list is only examined once, and breaking out of the inner predicate loop once a match is found.code:code:
|
|
#
?
Jun 26, 2014 17:55
|
|

|
EkardNT posted:
I had realized the first part of your post more or less immediately after posting. The return line above though is what I was really missing though - I was sure that it was possible to syntax my way out of writing the nested loops. I'm a little impressed that it went all the way down to one line though! Thanks edit: Here's a followup that I maybe should have considered beforehand. Is it possible now to serialize instances of my CustomList class? At first glance, it doesn't look trivial to serialize predicates that are defined in run-time. But since my predicates are relatively simple, I could probably wrap them in a class that is easily serializable. eg, code:Newf fucked around with this message at 19:46 on Jun 26, 2014 |
|
#
?
Jun 26, 2014 19:02
|
|
|
Hey guys, nice shiny new thread. Let's get it dirty with some idiot posting. The problem: I'm using StringBuilder to concatenate a whole biggo bunch of strings, converting that StringBuilder.tostring, and then writing the resultant string to an XML file. I'm sure many of you know what's coming next since I said "biggo" and "StringBuilder"; that's right, the dreaded 'System.OutOfMemoryException' caused by StringBuilder over-allocating contiguous memory. So the first question is obviously, any sneaky ways around this? The file is about 94mb raw text, but it can also fail randomly on smaller files (around 50mb), so 94mb is not a 'magic number' to stay under by any means. I've tried assigning double that to the StringBuilder when instantiating, but all that does is give me the memory error right up front at variable declaration instead of at the end when trying to convert to string. Based on what I can figure out it's a Bad Idea to even use StringBuilder this way anyway, and most of the workarounds are pretty dodgy. So assuming the answer to the first question is "no", my second question is advice on chunking up this monster. Right now things are structured like so (this is not real code): code:The obvious chunking candidate is the big SQL query, but that's kind of a pain because A)it's not my query and B)it's reused to generate OTHER files. However, on the other hand, I can't chunk the XML itself too much, because the publisher only accepts (x) amount of connections at once, dumps the ones over that, and this is relatively timely information that has to be generated twice a day. The last thing I thought of is to chunk the stringbuilder itself before converting to string (and being able to go xml = string1 & string2 & string3), but by the time the stringbuilder is 'done' it's too big to modify since anything I've found to modify it either implicitly converts it to string, or explicitly requires it done. I'm not looking to you guys to 'solve' the stringbuilder memory problem; I'm fully aware it's the result of bad design on my part. More trying to pick brains for possible workarounds. EDIT-I also looked into splitting the datatable itself and then passing the table chunks in MakeXML, but the ways I've seen to do that seem pretty inefficient: http://stackoverflow.com/questions/8132208/c-how-to-partitioning-or-splitting-datatable Scaramouche fucked around with this message at 03:55 on Jun 27, 2014 |
|
#
?
Jun 27, 2014 03:40
|
|


|
Deus Rex posted:Let's be clear about what you're saying here - TFS is free up to 5 developers until you have to purchase a support contract from some TFS consultant to figure out how to make it work. "You should use TFS" - a TFS consultant
|
|
#
?
Jun 27, 2014 04:22
|
|
|
Scaramouche posted:Based on what I can figure out it's a Bad Idea to even use StringBuilder this way anyway, and most of the workarounds are pretty dodgy.
|
|
#
?
Jun 27, 2014 05:35
|
|
|
Scaramouche posted:I'm using StringBuilder to concatenate a whole biggo bunch of strings, converting that StringBuilder.tostring, and then writing the resultant string to an XML file. I'm sure many of you know what's coming next since I said "biggo" and "StringBuilder"; that's right, the dreaded 'System.OutOfMemoryException' caused by StringBuilder over-allocating contiguous memory. I think you should change it to using streams throughout. code:code:
|
|
#
?
Jun 27, 2014 06:02
|
|
|
hirvox posted:If you are certain that your code will output valid XML, you should just write each line to the file as soon as you have generated each snippet. That way you'll only need to have one copy of the data (the DataTable) in memory at any time. The way you're doing it now you'll have at least four copies: The DataTable, the StringBuilder, the String itself and finally the XmlDocument. Yep, a stringbuilder with a textwriter and append each line to a new file. Read the file afterwards if you need it again. ^^ Nevermind
|
|
#
?
Jun 27, 2014 09:47
|
|
|
Scaramouche posted:Hey guys, nice shiny new thread. Let's get it dirty with some idiot posting. Sounds like an ideal case for System.Xml.XmlWriter! Plus, using an XmlWriter means you aren't building up XML by artisanal hand-crafted string concatenation, which is a bit gross
|
|
#
?
Jun 27, 2014 10:41
|
|

|
code:2000 lines/ 80k times? Refactor that poo poo, stat. Unless you're being hyperbolic but even then goddamn Also use xmlwriter or schematize it and reflect it into a class via xsd.exe. But there be dragons.
|
|
#
?
Jun 27, 2014 10:45
|
|
|
presenting: casual basic. imagine this everyday scenario: you'd love to use Microsoft Visual Basic .NET but just cant bring yourself to reach for the shift key. if only it was Microsoft visual basic .NET. case-preserving case-insensitivity? there has to be a better way. now there is a better way. 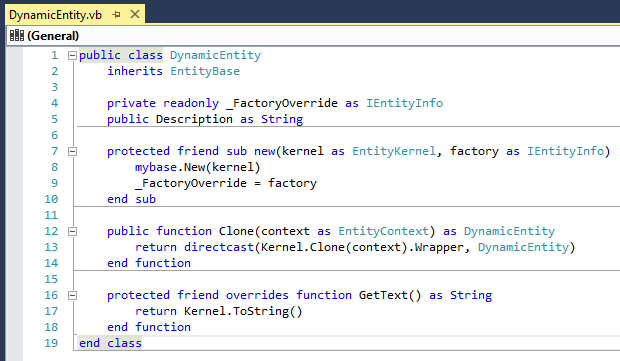 license: anybody can use it for anything
|
|
#
?
Jun 27, 2014 13:20
|
|
|
It's amazing how much better vb looks without stupid capitalization all over the place.
|
|
#
?
Jun 27, 2014 13:54
|
|

|
I would avoid hand building XML like the plague. If you need to build it iteratively I'd take a hard look at using xml text writer -- you will create invalid XML at some point. As for the OP, there really should be some other SCM options. Here is my rewrite: quote:Should I be using source control?
|
|
#
?
Jun 27, 2014 14:49
|
|

|
Gul Banana posted:presenting: casual basic. imagine this everyday scenario: you'd love to use Microsoft Visual Basic .NET but just cant bring yourself to reach for the shift key. if only it was Microsoft visual basic .NET. case-preserving case-insensitivity? there has to be a better way. rejected! look at the inconsistent capitalisation of sub new/mybase.New
|
|
#
?
Jun 27, 2014 16:02
|
|

|
wwb posted:As for the OP, there really should be some other SCM options. Here is my rewrite: Thanks, I'll update the OP tonight. I was focusing on Microsoft tooling because this is the catch-all Microsoft development thread. Come to think of it, I'll add a build and release section while I'm at it, and a cloud section.
|
|
#
?
Jun 27, 2014 16:45
|
|

|
Here's a real easy ASP.NET question for everyone. I'm trying to display a list of strings in a ListView, but the examples I'm working from all work from all bind to properties of the bound objects rather than the objects themselves. EG, the //what goes here line is expressed using something like <% #Eval("PropertyX") %>. How do I display the bound object itself (they're just strings!).code:Newf fucked around with this message at 17:50 on Jun 27, 2014 |
|
#
?
Jun 27, 2014 17:38
|
|
|
Newf posted:Here's a real easy ASP.NET question for everyone. I'm trying to display a list of strings in a ListView, but the examples I'm working from all work from all bind to properties of the bound objects rather than the objects themselves. EG, the //what goes here line is expressed using something like <% #Eval("PropertyX") %>. How do I display the bound object itself (they're just strings!). Should just be able to use <%# Container.DataItem %>
|
|
#
?
Jun 27, 2014 17:57
|
|

|
hirvox posted:If you are certain that your code will output valid XML, you should just write each line to the file as soon as you have generated each snippet. That way you'll only need to have one copy of the data (the DataTable) in memory at any time. The way you're doing it now you'll have at least four copies: The DataTable, the StringBuilder, the String itself and finally the XmlDocument. ljw1004 posted:I think you should change it to using streams throughout. Thanks guys, that's basically what I did: code:Pros: - Entire string is never in memory at once while building it - Not passing string between subs any more; the only time it's fully loaded is when I'm getting it from drive - Generated File size is actually about 15% smaller for some reason (I think from white space introduced by LoadXML/SaveXML) - Faster; for the 94mb file it actually takes longer to upload than create now Cons: - String isn't loaded into XML doc anymore for quick/dirty validation check - Drive thrashing? I have no idea if there'll be eventual performance concerns of going to drive iteratively instead of all at once Malcolm XML posted:what the gently caress Those 2000 lines don't 'live' in the MakeXML sub, about 90% are in external abstracted functions (e.g. GetColor, GetLength, GetBrand, that kind of thing). I'm parsing data from about 30 different suppliers, and need to convert their values into numeric codes. E.g. "Red" = 87550701, with the resulting XML being "<Color>87550701</Color>". Except I have to parse "Red","Cherry","Blood","Redd",etc. I realize the 'real' solution is make a rockin hardcore XSD translation but man, this data is so all over the place it's currently 'easier' to add cases to GetColor. Thanks again guys! Why this forum rocks as usual.
|
|
#
?
Jun 27, 2014 20:05
|
|
|
Scaramouche posted:Thanks guys, that's basically what I did: why are you writing to a file on disk first (do you need to keep it around?). you could just stream it all the way out to the connection (if you must keep the file around and read from it at least stream it out via file.openread)
|
|
#
?
Jun 27, 2014 20:46
|
|
|
Ithaqua posted:Thanks, I'll update the OP tonight. I was focusing on Microsoft tooling because this is the catch-all Microsoft development thread. Sounds good. I contemplated tacking a CI section on but I thought that was a bit beyond scope. Lots of interesting cloud options popping up. The other thing I think we are missing is a bit more flesh on the xarminian / non-MS platform stuff. Especially now that Nardella has made that a 1st class citizen in the ecosystem. quote:big xml dumping issues A bit late to the party but why not use an XmlTextWriter -- that will let you guarantee well formedness while also letting you stream the results quickly. PS: for content -- actually have a greenfield project. Basically a CMS feeding a web API that will feed lots of other stuff. Looking at options for IoC containers it seems like the cool kids like autofac whereas we've been a structuremap shop for a while. Any good reason to make the switch? And any other shiny new toys we should look at while I'm at it? wwb fucked around with this message at 22:44 on Jun 27, 2014 |
|
#
?
Jun 27, 2014 21:26
|
|
|
Does anyone have any idea why VS 2013 might start hanging whenever I try to open or add an F# library project? Right after I do it I get that "Visual Studio is doing something or waiting for user input" pop up whenever I click anywhere, and attempting to end the process gives me the "Visual Studio is waiting for modal input" dialog box, except it doesn't look like it is. This is kind of a problem... e: Update 2 fixed it, whatever "it" was. raminasi fucked around with this message at 20:01 on Jun 29, 2014 |
|
#
?
Jun 29, 2014 18:51
|
|

|
Holy poo poo why does build time on the Hosted Build Controller cost $.05 a minute?
|
|
#
?
Jun 30, 2014 15:29
|
|
|
Dietrich posted:Holy poo poo why does build time on the Hosted Build Controller cost $.05 a minute? If you're doing true CI, I strongly recommend hooking up an on-prem CI solution. Team Build will of course work just peachy with VSO, as will Jenkins and TeamCity.
|
|
#
?
Jun 30, 2014 16:28
|
|
|
Ithaqua posted:If you're doing true CI, I strongly recommend hooking up an on-prem CI solution. Team Build will of course work just peachy with VSO, as will Jenkins and TeamCity.
|
|
#
?
Jun 30, 2014 16:38
|
|

|
Since we're talking CI I'll say I've had a pretty good experience using the free offering version of AppVeyor and since I use GitHub as my auth account the integration is pretty easy and great.
|
|
#
?
Jun 30, 2014 18:45
|
|


|
Maybe we could also add something about publishing your programs or what to use if you want product key activation in your app/program? I have used Cryptolicensing in the past because it's cheap but, looking at Intellilock and Elipter. Is there a MS library for this to aid in roll-your-own? edit: probably too much of a tangent discussion for the OP now that I think about it
|
|
#
?
Jun 30, 2014 22:38
|
|
|
Malcolm XML posted:why are you writing to a file on disk first (do you need to keep it around?). you could just stream it all the way out to the connection (if you must keep the file around and read from it at least stream it out via file.openread) Hmm you might be right on some of this. I keep the file around because it's for an Amazon product feed, and Amazon is constantly changing the specification in strange ways so I need to be able to refer back to the original when a 'error cvc complex blah blah line 54615 column 132' pops up. The changes I've made have improved the situation, but not solved them. Now I'm getting OutOfMemory errors in a different place, when submitting my XML here: code:
|
|
#
?
Jul 1, 2014 22:24
|
|
|
Scaramouche posted:Now I'm getting OutOfMemory errors in a different place, when submitting my XML here: Streams give you a way to read and write bytes from/to some other location. That other location can be (but is not limited to) a file, memory, or a network socket. The Position property on the stream represents the position in the source data from where the stream starts reading from or writing to, and it's automatically updated when you read from or write to the stream. In order to actually calculate the MD5, MarketplaceWebServiceClient.CalculateContentMD5 needs to read all of the data out of the stream. It's not actually storing all this data in memory, it's just doing math on small chunks of it at a time. But in doing so the stream updates its Position to the end of the underlying data, which is why you need to reset the Position to 0 otherwise there would be nothing left for the web service client to send. So if instead you were to do: code:I suspect the examples you're referring to describe the manual process of converting stream data to and from text, which almost nobody ever does because StreamReader and StreamWriter exist and which you don't have to do anyway because you're handing all of the work off to the Amazon library. e: vb may be bogus, I'm a C# guy e2: The using block is important so that you close the file when the Amazon lib is done with it, regardless of stuff otherwise breaking
|
|
#
?
Jul 2, 2014 02:14
|
|

|
Night Shade posted:So if instead you were to do: Huh, I had really hoped you were onto something there, but alas, OutOfMemoryException strikes again when I use the exact code you posted above. code:code:http://blogs.msdn.com/b/johan/archive/2006/11/15/are-you-getting-outofmemoryexceptions-when-uploading-large-files.aspx EDIT-Hmm thought I could mess with MarketplaceWebService.Model.ContentType but the only choice is OctetStream EDIT EDIT-I'm poking around in the ObjectExplorer and I've found a MarketplaceWebService.Attributes.RequestType, which can be Default, Mixed, or Streaming but I think it's an internal book-keeping thing. Scaramouche fucked around with this message at 03:59 on Jul 2, 2014 |
|
#
?
Jul 2, 2014 03:33
|
|
|
Have you tried a bufferedstream? Something like: code:
|
|
#
?
Jul 2, 2014 05:44
|
|
|
Scaramouche posted:The interesting thing is I had stumbled upon a similar solution earlier, with the only difference being mine didn't use the Using... block, but the error is identical, down to ScatterGatherBuffers. I'm not sure what's going on here, other than the stream is obviously being treated as the entire thing instead of streaming. This is an example where someone chunks something too big for webclient, but it looks so specific and so much goes on in the While... loop I can't see how I'd get it to work with the Amazon SubmitFeed(request) model: I found a copy of MarketplaceWebServiceClient posted in a github somewhere and I'm pretty sure the link you found is the problem, MarketplaceWebServiceClient internally is creating an HttpWebClient which is buffering the stream anyway. Unfortunately if you haven't got access to the source I don't think there's a way to fix it. 
|
|
#
?
Jul 2, 2014 07:24
|
|
|
Anyone have experience hosting external applications in WPF? In the simplest case it's pretty trivial (e.g. notepad) but if it's between two complex apps it quickly gets out of control. Buzzwords: HwndHost, COM, OLE(?), Win32, routing message pumps
|
|
#
?
Jul 2, 2014 15:32
|
|
|
What do you guys use for installing and updating distributed/commercial applications? Not huge scale commercial, but installed across 1000's of computers around the world and able to update to the latest version. Here's what I've used: ClickOnce for installing/updating. InstallShield for installing. When the app needs to update it launches an update.exe & closes so update.exe can do it's thing, then update.exe re-launches the app. InstallShield for installing, then a plugin model. When the app detects an update it can download & overwrite the file without having the extra update.exe (and doesn't have to close & re-open). All of those have their pro's and con's but I'm really interested in what you guys have done.
|
|
#
?
Jul 2, 2014 17:02
|
|

|
Mr. Crow posted:Anyone have experience hosting external applications in WPF? In the simplest case it's pretty trivial (e.g. notepad) but if it's between two complex apps it quickly gets out of control. How much control do you have over the external process? If the answer is "none", I'd recommend building your program as a shell which draws itself around the other windows, it sounds like asking for trouble otherwise. Essential posted:What do you guys use for installing and updating distributed/commercial applications? Not huge scale commercial, but installed across 1000's of computers around the world and able to update to the latest version. Here's what I've used: We distribute our products as MSI packages (I think we use WiX), but we have the luxury of our update model being sales emailing the clients and telling them to grab the new MSI when they get around to it. I've toyed around with the idea of using MEF or child AppDomains for reloading code without exiting the process, mostly for services, which seemed promising.
|
|
#
?
Jul 2, 2014 18:55
|
|


|
chmods please posted:We distribute our products as MSI packages (I think we use WiX), but we have the luxury of our update model being sales emailing the clients and telling them to grab the new MSI when they get around to it. I've toyed around with the idea of using MEF or child AppDomains for reloading code without exiting the process, mostly for services, which seemed promising. Child AppDomains is how the 'plugin' update model I'm using was built. MEF was too difficult for me to implement at the time and the child AppDomain was relatively simple to use. It's also proven to be quite effective. I haven't used WiX, I've heard it's really, really powerful and awesome, but has a steep learning curve.
|
|
#
?
Jul 2, 2014 19:44
|
|
|

|
| # ? May 3, 2024 00:46 |
|
|
Essential posted:What do you guys use for installing and updating distributed/commercial applications? Not huge scale commercial, but installed across 1000's of computers around the world and able to update to the latest version.
|
|
#
?
Jul 3, 2014 09:26
|
|