


|
Hammerite posted:words This works out well, doing in about 30 min on 25+million rows. but it highlighted data issue i was not aware of before: code:The ultimate goal is to, when asked for the best address for a given UID, only one rowID is returned every time. God drat it devs get some data integrity going. especially since this process wouldn't even be needed if you did stuff properly.
|
 #
?
Feb 26, 2016 16:50
#
?
Feb 26, 2016 16:50
|
|

|

|
| # ? Jun 7, 2024 16:53 |
|
|
Roundboy posted:This works out well, doing in about 30 min on 25+million rows. but it highlighted data issue i was not aware of before: That sounds like quite a long time even if you do have on the order of tens of millions of rows. Are you missing indexes that would help this? I'm rusty on exactly what MySQL can do with indexes, but tell us what indexes this table has.
|
|
#
?
Feb 26, 2016 17:11
|
|

|
Hammerite posted:That sounds like quite a long time even if you do have on the order of tens of millions of rows. Are you missing indexes that would help this? I'm rusty on exactly what MySQL can do with indexes, but tell us what indexes this table has. mySQL indexes are.... weird, but I am by no means an expert. From my explain plan : code:code:idx_best is the index it chose to use, which is uid,rowid. I never paid too much attention to this as its on derived tables, and the left joins & criteria mean I still need to look at every record in the table anyway. Covering indexes are out since I am joining tables.. but I think row 1 with the ALL is the timesink. I am also running on a lower end server and not all the tables fit into memory, but i like to hink I tuned up mySQL enough to run well. I am fully aware I know enoug to be dangerous, but I am in no way knowledgable enough to fix it right away. Aren't left joins pretty much 'shrug' gonna run lng, especially with sub queries ?
|
|
#
?
Feb 26, 2016 19:34
|
|
|
Pardot posted:http://sqlfiddle.com/#!15/d29c7/4 That seems to do the trick, thanks. I'll have to read up on this. All of my tables are named farts-#
|
|
#
?
Feb 26, 2016 22:07
|
|
|
any sql server dba here? things be making no sense with IS and sql server agent and i'm looking for guidance.
abelwingnut fucked around with this message at 02:20 on Feb 27, 2016 |
|
#
?
Feb 27, 2016 01:41
|
|


|

|
|
#
?
Feb 27, 2016 16:25
|
|



|
will do. i'll preface by saying i'm a developer, not a dba. this may be some basic login credential chicanery. running sql server 2012. IT just created the IS catalog this past week. i built a package on my machine locally, debugged it, built it, deployed it to the server. great. runs fine from vs on my local machine in debug mode. when i right-click -> execute it from ssms on my local machine under my active directory-controlled account, it fails. when i right-click -> execute it from ssms on the server under the active directory-controlled, default account for that machine, it runs. when it runs as a job from sql server agent, it fails. when it fails, it errors with 'data flow error: warning: access is denied', file destination subcomponent. the package queries and puts the results in a tab-delimited file on a network share. my account has full access to the share. what is going on here? my account has the same rights as the other account that succeeds. the fact it runs at all tells me it's not the package itself. so yea, there are two aspects here: how can i get it to run from my local machine under my account, and how can i get sql server agent to run it. abelwingnut fucked around with this message at 18:14 on Feb 27, 2016 |
|
#
?
Feb 27, 2016 17:53
|
|
|
If you can, run VS as Admin on your machine (even if you are logged in as an Admin already). I've seen some odd stuff, and running programs as Admin fixes most of them. See if that works, otherwise, what's the default account on the machine itself (the one that works)? Is it a created service account, or is it the NT service default account (account defaulted in the installer)?
|
|
#
?
Feb 28, 2016 01:51
|
|
|
just right-click > run as admin on vs, then deploy from there? the default account on the server is a network account. sql server agent and IS are running under LocalSystem, i think
|
|
#
?
Feb 28, 2016 19:50
|
|
|
Reformatted for later inspection (busy right now)Roundboy posted:
|
|
#
?
Feb 29, 2016 10:58
|
|
|
Roundboy posted:mySQL indexes are.... weird, but I am by no means an expert. From my explain plan : Have you tried experimenting with indexes as follows: (uid, rank, rowid) (uid, status, rank, rowid) (status, uid, rank, rowid) [at most one of these last two would be useful, I don't know which one would be more likely to help] It might not be practical to have several indexes in place due to the limitations of the machine you described, I don't know. I don't really know which (if any) of those possible indexes might help, sorry I can't be of more help.
|
|
#
?
Feb 29, 2016 21:17
|
|
|
I'll post my current solution when I get home, but I turned the problem on its head and I came up with a way that minimizes execution time vs complexity. Indexes could help furrher, but I am testing. That being what it is, what is the general consensus of time vs. Rows? Would parsing 25mil rows into 12mil using joined and nested subqueries really be out if order taking 20-40 min?
|
|
#
?
Mar 1, 2016 00:18
|
|
|
ok, it was oh so 1/2 page ago, but the goal is to take a table of addresses and for a given uid, find the lowest ranked rowid that is active. Or lowest ranked inactive. The addresstable is structured as one uid to many rowid. I came up with this today code:All the records I need are contained in table 'aa' as its all records sorted by uid,rank,modified date. so i am naturally getting at the top the record I want. Then i just left join to only the active ones to see if this will change the rowid returned. Now that I typed this all out, I could probably eliminate the whole left join and just pull from the table ordered by uid, status, rank ASC, modified_date DESC and do the same pull the first iteration. The Active (A) will naturally be placed before the Inactive (I) and in the caseof no active, it will sort properly on rank... AND in the case of duplicate ranks, sort on modified date. it is a much simpler execute plan code:Again i am reading up on proper indexes but its hard to find reading material that is much more then WHERE COL = A add an index to A and U R golden. I am also tying to ignore tuning advice saying to dump the query cache because its acually usefull in my situation (i think) . I write to the main tables once a day for updates.. anywhere from 1 to 10 million updates, and the rest of the day are people selecting from these tables, and making their own subsets. This is exactly the situation the query cache is good for. The real problem is i have 32G of memory, and 90G of data tables. I/O is gonna get used and the server as it was given to me had shittastic settings in my.cnf. I edited them to be either sane or default but I am about to start over with a new, clean cnf and rear end options one at a time to test. EDIt: its using the new index but the explain plan is identical Roundboy fucked around with this message at 02:17 on Mar 1, 2016 |
|
#
?
Mar 1, 2016 02:11
|
|
|
I've got an Oracle 11g problem that looks simple, and a solution that works, but I'm wondering if there's a better way. The issue is figuring out deadlines in working days. I've got a table CALENDAR (not really the name, but for simplicity's sake...) that includes weekdays Monday to Friday and (beside the date itself) a value that codes whether it's a holiday that year and therefore doesn't count for the deadline. (That table has values populated up to 2030 and so contains a couple thousand rows.) Now, say I want to determine the date that is ten working days from now. My approach is like this:code:* = Being off by 1 aside, but that can be tackled by adjusting the deadline value or reworking the criteria inside the subquery. Point is, the principle of it works. ** ** = Don't throw together queries five minutes before you clock out, they'll linger with you when you should be sitting down and watching TV.
|
|
#
?
Mar 1, 2016 17:39
|
|

|
Can you select top in oracle? If so this should workcode:
|
|
#
?
Mar 1, 2016 18:36
|
|


|
No, Oracle doesn't support TOP afaik, it needs a ranking function. Basically my second idea goes like this:code:
|
|
#
?
Mar 1, 2016 19:50
|
|
|
Roundboy posted:ok, it was oh so 1/2 page ago, but the goal is to take a table of addresses and for a given uid, find the lowest ranked rowid that is active. If you can't find improvements with Describe, start ripping apart the subqueries to analyze their individual runtime. Use faked results (select 1,2,3) as placeholders, and determine how the runtime changes as you add back each piece. You'll probably find one or two issues, and that's where indexing should be considered. Otherwise you'll just be creating a bunch of indexes that will be taking up space in your short supply of memory, and won't be helping much.
|
|
#
?
Mar 2, 2016 00:45
|
|

|
PhantomOfTheCopier posted:You might find something by changing optimizer_search_depth, but the primary trouble is that you've chosen the wrong tool for the job. Sadly it's notoriously bad at describing its choices, and not real smart with nested subqueries and joins (not this many at least). I've been diving into it pretty much all day. and my current query is acceptable only because the 45m it takes is at 4am code:code:I can either do that work, making it a mess, or just write the script that ends up calling it all do it in parts like i was before. That is the strength of mySQL, doing small queries in parts on large datasets.. but it does make me want to start evaluating postgress posthaste
|
|
#
?
Mar 2, 2016 05:04
|
|
|
Roundboy, feel free to attack this as the total derp response, particularly since I haven't tested this on MySQL so the distinct may fail, but what happens with?code:PhantomOfTheCopier fucked around with this message at 14:50 on Mar 2, 2016 |
|
#
?
Mar 2, 2016 06:05
|
|
|
PhantomOfTheCopier posted:Roundboy, feel free to attack this as the total derp response, particularly since I haven't tested this on MySQL so the distinct may fail, but what happens with? I'm going to call derpy because I don't think its kosher to join to the main table from within the subquery ? syntax accepted but the explain plan puts it as a1 returning all 25mil rows and both tables have a filesort.. which is my killer at the moment. My original above runs in 45-60 min to cull 25mil rows to the distinct 12mil ... when i remove the modified date DESC / ASC switch the same query returns everything in 8 min... which is crazy fast. Again, the only reason i am adding the modified date is because of the situation some other programmer created where a UID can have multiple entries for ROWID where the rank and status are identical, and taking the later modified one is probably the more correct entry.. but that is a guess essentially. The later modified record could have just been touched, not actually be the better data set. My fix at ths point to keep it as is would be to increast the sort_buffer(?) to something absurd to hold 12mil records or the same in the temp mem table to do the same, which has the added bonus of maybe crashing the server depending on mem free vs what this table takes. The stuff I am reading where people are adding columns to tables to fix this sort stuff is making more sense now. Christ I miss oracle or even SQL Server at this point
|
|
#
?
Mar 2, 2016 06:25
|
|
|
Roundboy posted:I'm going to call derpy because I don't think its kosher to join to the main table from within the subquery ? syntax accepted but the explain plan puts it as a1 returning all 25mil rows and both tables have a filesort.. which is my killer at the moment. In any case, I still call slight derpy on the original query. It's so complicated as to "obviously signify that something is amiss". Think about it: You are Required to scan all 25M rows because you don't have DISTINCT ON; even with CTEs, a row number partition would be required. Second, because "MySQL", your query is forced to apply a row number to all 25M rows; that's a lot of extra memory and work just to get the first row. (Oh, I admit it's a classic MySQLism, but it's equivalent to LIMIT 1, so it would sure be nice if LIMIT worked here. After all, you're not asking for the first three or something, so nearly 100% of the row ranking work is wasted.) Third, and foremost, which it sounds like you're approaching, is the notion that this is supposed to be an RDBMS. There is an UPDATE command for a reason. That this report is so difficult is representative of a table that's not representing the data properly. The table currently contains: Status changes, historical row update information, "live" uid information, and probably a few other things that haven't been mentioned. p.s. I'll repeat what I postscripted above: How long does it take to dump every rank/uid/rowid/status/?modifieddate unsorted and do a full hash build of the result in your favorite scripting language? That should only require scanning each row once.
|
|
#
?
Mar 3, 2016 07:05
|
|
|
Abel Wingnut posted:will do. i'll preface by saying i'm a developer, not a dba. this may be some basic login credential chicanery.
|
|
#
?
Mar 3, 2016 16:27
|
|


|
PhantomOfTheCopier posted:One of the troubles with DESCRIBE is that it doesn't necessary accurately report the number of rows that will be returned. If the call to DISTINCT doesn't work, the query will return all UIDs with repeats, but all will show the correct rowid. If distinct behaves, you'll end up with one row per uid. Testing on MySQL will tell the tale. I ran your suggested code anyway, and it still took the 60+ min due to the same filesort issue. I don't think its correctly limiting the subquery to then push to the large sort.. but I can dive into the query a bit better. I leave a lot out of the original table as designed as this is the only relevant data, but the design is a good trade off between function and use. I could see improvements in some areas, but this is technically out of my hands, even though i am basically replicating it on a local server. I can;t rock the boat too much or I lose th ability to easily pull updates, which is paramount. The dump of all data is quick, as would a hash in perl / python, but, this is me being dense, that doesnt get me further ? I specifically want sorting on specifics, and the hash as you describe is more dupe checking ? My brain is a bit fried on things so I may be completely misinterpreting your idea. The data is not exact on modidied_date, which is why it was a order by option The issues are really just : 1) I have bad data that will be remved / fixed eventually, but im trying to be a good boy scout and handle it until then 2) mySQL lacks a ranking function, so I deal with it via the variables and order by 2a) because I am doing this, I can negate the need for any grouping and rejoining 3) mySQL is horrible with mixed order by, using ASC and DESC in the same statement. Forcing the need for a temp table 3a) the temp able is too big for memory, so it goes to a file based temp table 3b ) My server is horrible at this process. i am trying to find out if I am cpu or IO bound and what I can fix here I don't know how big that temp table actually is, but its probably a hell of a lot bigger then I am willing to adjust a temp_table_size variable for.. even temporarily. In reality, modified data is not even the best way to grab the 'better' record, so I might as well dump it. or i can play up the strength of mySQL and do this as a series of quick pulls, and do a join later.. i dunno yet. Either way its a unique issue that has many solutions, i just cant figure out the best way yet. Cliff Notes : Do I have a server problem, do i need to write this query outside the normal bounds of what this 'should' be ?
|
|
#
?
Mar 3, 2016 18:02
|
|
|
Stupid question but did you try an index with the exact asc/desc sorting order as needed?
|
|
#
?
Mar 3, 2016 19:23
|
|
|
BabyFur Denny posted:Stupid question but did you try an index with the exact asc/desc sorting order as needed? mySQL has a feature? bug? where indexes are sorted in a single direction. So if you pull data in an order by that exactly matches the index (which this is) , it will grab it for one direction only. Since i am doing a,b,c ASC, d DESC it must pull all the results to a temp memory table, decide the memory table is going to get too big, dump it all to the disk based table where there are no indexes present, and sorts it there. These sorted results are what are returned. People have solved this by taking the other order column, and adding it in the data but reversed, so it can be sorted in the same direction as the others. This is fine, because I really think the fix is to make the 12m to 25m row disk temp table not sort like rear end. I think this is fixed in Percona 5.7? Im on 5.6 atm. This, and a few other things are why I ultimately want to move to PostgreSQL, but I am competent to know there are other problems with that I dont even know about yet, and i have to convert the rest of my team off of mySQL and they are *drat* attached to Toad. Until I write some nice wrappers for them to load data (essentially a easier way to create tables from a given file) they will revolt because they rely on GUI tools to do so. Sorry that turned into a longer post then needed
|
|
#
?
Mar 3, 2016 20:31
|
|
|
We have an Oracle database. It doesn't maintain reliable history, but we need reliable history for reporting. So we create weekly or daily tables that store the state of assorted views as they were at that date, together with the date and time the table was "frozen," and we use those for historical reporting. Basically every week we run a bunch of statements like "CREATE TABLE butts_03_07_2016 as SELECT sysdate() thedate, butts.* FROM butts;" and so yes, we have a lot of these tables. Thousands. Our DBA probably hates us. This approach has a couple of problems, but it's what I have and I am not in a position to change it. One of these problems is that there's no easy way to do a longitudinal report that summarizes data from (say) four or five years of these weekly tables, because you have to UNION 200-odd of them. So I am attempting to create a single table that concatenates all the historic tables into one. e.g.: code:This can be fixed by identifying the point in time where the column was added, and changing all the earlier select statements to pull in a matching column with a null value. But this is a godawful great pain in the rear end (and the actual scale of the work is at least 10x greater than in this simplified example). Any of you smartymen have any ideas of how I can make this a bit more workable? Or any general strategies for UNIONing tables with extra columns?
|
|
#
?
Mar 7, 2016 16:36
|
|

|
saint gerald posted:We have an Oracle database. It doesn't maintain reliable history, but we need reliable history for reporting. Are the extra columns actually needed for the report? if butts_03_07_2016 has A,B,C and butts_02_29_2016 has A,B,C,D but only A,B,C is needed then you can explicitly select just those coluns for your union. If col 'D' is needed, but not present you can" code:
|
|
#
?
Mar 7, 2016 16:50
|
|
|
Couldn't you summon a super view over the set of tables? I would be surprised if Oracle does not have something nice for this configuration, the MySQL family have been slowly adding multi-partition and multi-table engines so a single query is replicated across each.
|
|
#
?
Mar 7, 2016 17:01
|
|

|
Roundboy posted:Are the extra columns actually needed for the report? Yeah, we need the new columns, unfortunately. quote:you can also create a single history database that holds all columns, and selects the specific columns from each table into one larger table to have you go through this process once, vs each time something changes. This is scriptable but you have to go through some hoops to get a string table name into an actual select statement. There is a trade off between looking at the table values, adding to either a big rear end union all or a new history rollup table vs making it dynamic. I'm not sure exactly what you mean. Something using all_tab_columns? I don't know if my PL-SQL is hot enough to build the big-rear end union completely dynamically. We can go from table name as string to actual select statement easily enough with EXECUTE IMMEDIATE, I think. MrMoo posted:Couldn't you summon a super view over the set of tables? We could but have been reluctant to do so because of performance. The Oracle alternative seems to be a materialized view, which we can index and (I think) partition how we like, but we would have to rebuild the whole shebang every time we add another weekly extract, unless I am missing something. That's probably several hours of DB time every week and I am not sure what it would gain us over a single table.
|
|
#
?
Mar 7, 2016 17:32
|
|
|
A materialized view doesn't have to be full refreshed for every change, in theory (SQL Snippets goes into some detail on MatViews here), but I'm pretty sure changing the view definition (which you would need to do every time you add a new archive table) means fast refresh is out. EDIT: Further Googling suggests that dropping and recreating the view could reuse the materialized view logs on the tables that were previously part of the MatView, which might actually help rebuild it faster and make it so that it only needs to full refresh the new table you added, but frankly this is way over my head. Might be worth checking into, though. Gatac fucked around with this message at 19:06 on Mar 7, 2016 |
|
#
?
Mar 7, 2016 18:59
|
|
|
There are obviously much better ways to handle the actual historical snapshot data tables, but putting all those aside and just working with that tableset as-is: Consider creating Running Total view like butts-2016-03-07-RT that is a view UNION over butts-2016-03-07 and butts-2016-02-29-RT, which is a view UNION over butts-2016-02-29 and 2016-02-22-RT, etc down the rabbit hole. Periodic checkpoints every 6 months or so would keep the total union depth to a sane degree to not make compile times ludicrously long. Make another view butts-current-RT that is just a synonym for the current one, and drop+create it *after* the new materialized view has been created so there's minimal downtime. Only keep the most recent one or two materialized so you don't have hundreds of copies of the same row from 2010 floating around. E: This is very roughly what Partitioning would be doing behind the scenes, with building the new snapshot weekly and then exchanging it in. That is an EE upcharge, though and would require reengineering how you take the snapshots. keseph fucked around with this message at 04:22 on Mar 8, 2016 |
|
#
?
Mar 8, 2016 04:14
|
|

|
another SSIS question i wrote an SSIS package that generates a report. basic flow is declare table variable > fill table variable with select statement that's a union of two other tables > another select statement calling from about eight tables, the table variable included > spit out results to csv. the query takes 40m to run for some reason--i'll post about that later. but it turns out when i was testing the package it locked the tables it was calling from and crashed the client programs. i'm not writing anything to any tables, only to the table variable. when i run the query outside of the package, no such crashing. do IS packages lock tables or something? i've never experienced that in the past, probably because i've never had a query run this long. abelwingnut fucked around with this message at 02:21 on Mar 10, 2016 |
|
#
?
Mar 10, 2016 01:37
|
|
|
Abel Wingnut posted:another SSIS question Depends on how you've defined the table sources. SSIS does not use quite the same isolation level mechanisms as you're used to from SSMS (which is read committed by default). It has isolation level settings that are a superset across a bunch of different data engines which is why it calls them funny names like "chaos", since any given data source might not have a concept of "read uncommitted".
|
|
#
?
Mar 10, 2016 02:37
|
|
|
thanks. i defined them with source assistant, sql server. how should i define them to avoid this apparent locking? i'm googling but not having much luck.
|
|
#
?
Mar 10, 2016 04:36
|
|
|
Using Django's ORM like a baby and have a problem. I need to insert a lot of records all at once and some of them may or may not already exist. I'm sure I need to just use some SQL instead of the ORM for this. I found someones blog describing my problem and their solution, so I'm just going to quote it here instead of describing my problem myself.quote:If you've ever used the Django ORM bulk_create method, possibly you've run into the case where any key conflicts result in an IntegrityError exception that rolls back the whole bulk_create. The obvious fallback is to create each record individually and catch the exception. Or, use update_or_create. Does the solution described at that blog post seem like a reasonable solution? I'm an SQL baby so I'm basically just looking for some reassurance. I mean, it's easy enough to implement on the surface of it, but I've got a few reservations: 1. I'm not quite clear on how those table locks work. I'm worried a little bit about performance...concurrent SELECT's on the non-temporary table will work fine while it's locked? But not INSERT/UPDATEs? 2. My schema is quite a bit more complex than their toy example, and I've got multiple foreign keys to other tables per row, so I need to create (or not if they exist already!) those records and then get their id to add to their parent. I suppose I can handle their creation in the same way I'm creating their "parent" rows...aka, INSERT INTO blah SELECT * FROM blah_temp WHERE NOT EXISTS (SELECT 1 blahblahblah), but...I need to get back all the ids whether they're inserted or already exists so that I can add their newly-created or already-existing id as a foreign key to the parent. Anyway, specific advice or general ideas are appreciated. edit: lol, 1 minute after posting, I came across this: https://wiki.postgresql.org/wiki/What's_new_in_PostgreSQL_9.5#INSERT_..._ON_CONFLICT_DO_NOTHING.2FUPDATE_.28.22UPSERT.22.29 I can run 9.5 no problem, it looks like maybe this is what I need, but I still need to get the ids back from the database when I do the insert (or not if already existing) of the related records... edit2: Yeah, I got it mostly working. SQL code:edit3: And here's the solution: SQL code:I'm sure everyone is really excited about this. Thermopyle fucked around with this message at 21:06 on Mar 10, 2016 |
|
#
?
Mar 10, 2016 18:28
|
|

|
I'm using an Oracle DB. I have Hibernate entities that include joins. I want to paginate my results, but Hibernate generates SQL that uses rowid syntax. This is getting planned with the rowid limit happening AFTER a full-table-wide left-join. Switching to lazy fetch solves the problem for now, but that also means that I have to hammer the database for each row. Is there a better way to do pagination with Hibernate? Or alternately, should I just do a CTE that builds a temporary table where I could use a LIMIT?
|
|
#
?
Mar 11, 2016 20:32
|
|

|
I am using SSIS to import data into SQL Server 2014 and am struggling to import a timestamp. I have a timestamp of the format code:code:Any other combination results in conversion errors. Can anyone help? (What is it with SQL Server and it's lovely handling of time stamps or time strings?  ) )
|
|
#
?
Mar 17, 2016 23:34
|
|

|
Figured it out (it was actually quick to do once I decided a direct import wasn't possible):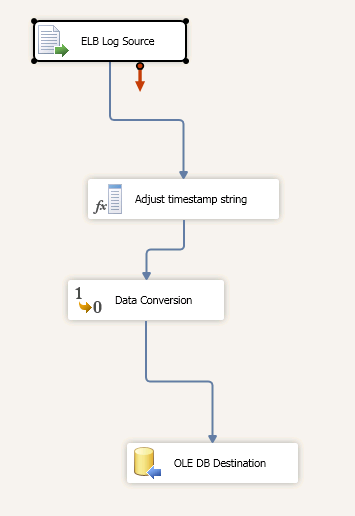 First step was to convert the string into a string readable by SQL Server using a Derived column with the following derivative: LEFT(timestamp,10) + " " + LEFT(RIGHT(timestamp,16),15) Then a data conversion step that converts a DT_STR data type to a database timestamp with precision (DT_DBTIMESTAMP2) with a scale of 6. Then import it into SQL Server as a data type datetime2(6). Goddamn timestamps.Maybe it's time I picked up a NoSQL solution where everything is a string.
|
|
#
?
Mar 18, 2016 00:07
|
|
|
This is bothering me for my 'redundant data' trigger, but what if the redundant data to be normalized -is- the key? I have a database with millions of rows like main_id as the key. Clients have susets of these ids in local instances and I want to create a unifying table to display that "hey, 5 clients all have this same ID, maybe we should prioritze that one vs this other random one" No, this is not queried directly, i need to get a file of these IDs and load them into my DB. client table code:code:code:code:code:The main table is simply : code:code:Am I missing something basic and fundamental in this design ? This will probably hold in the order of 100,000's of main_ids per client x 4-10 clients per quarter. I think with INT and tables really just designed around the key it would be very usable and maintainable ? ALSO I originally used the spec of the DB given to me and in the main tables I will further link to, main_id is varchar(18), and its the main key as well as FK in all tables. Am I really using up too much space and killing my performance on mySQL not converting that to a simple INT ? Row count numbers in the 10-25 million for these. I am told I should be but I am having trouble getting hard numbers until i clone the table and alter the table for myself to check
|
|
#
?
Mar 18, 2016 02:13
|
|
|

|
| # ? Jun 7, 2024 16:53 |
|
|
Agrikk posted:
datetime in generally  e: especially timezones 
|
|
#
?
Mar 18, 2016 04:01
|
|