

|
In general, it allows you to use the type-checker as a more general theorem prover - using the same principles of checking if a value will always be an Int, you can extend that to check if a value will always be an Int that is between 0 and 255. It's basically using types as specifications of what the program actually means (the idea is that you can encode arbitrary amounts of information in types to asymptotically approach a compile-time check that verifies literally all the features you want from your program. Obviously, we're no where near there, and it's not likely that's a reachable goal, but dependent types let you opt in to compile time checking of interesting guarantees.) In some arguments, this is meant to take the place of unit tests - instead of writing tests that run a function and check, for some set of inputs, that the outputs are the ones you expect, you can use dependent types to encode in the type of the function that the function will only ever return types you expect (like the type of (++) on Vect embedding the length, ensuring that the Vect you get back is of the correct length.) Theoretically, you could, instead of unit tests of some abstract property, use dependent typing to create functions that express proofs of properties of your system (like the associativity of operations, or invariants of functions.)
|
 #
?
Dec 2, 2016 04:01
#
?
Dec 2, 2016 04:01
|
|


|

|
| # ? May 13, 2024 21:56 |
|
|
It's an attempt to further increase our ability to "Make invalid values unrepresentable."
|
|
#
?
Dec 2, 2016 04:06
|
|


|
Right - we're trying to reduce the domain of our functions to exactly the ones we're interested in, where traditional typed programming makes us write functions that accept a whole bunch of stuff that we don't care about and don't ever want as input, but have to acknowledge because we need to have total functions over whatever input type we use. To some extent, what these dependent types let us do is move specification from the output of a function, where we weaken the image of the function to allow for more inputs, to a function where we've strengthened the domain instead (for example - Haskell List head operates on all Lists, but will error on an empty list; Idris Vects operate only on non-empty lists, and guarantee that they don't error.) This does sometimes constitute a burden when calling a function (having to provide proof of a non-empty list), but allows us to use the result of functions much more easily (not having to care about errors; we can also get rid of a lot of functions that return Maybe a by restricting the input type to only inputs that would allow defined outputs, which means when we call those functions, we can assume that we have valid output.)
|
|
#
?
Dec 2, 2016 04:15
|
|
|
Asymmetrikon posted:...we can also get rid of a lot of functions that return Maybe a by restricting the input type to only inputs that would allow defined outputs... I've been munging some nested data structure in Elm and I want this so bad!!! This point should be in the marketing of dependent type langs.
|
|
#
?
Dec 2, 2016 04:30
|
|

|
Shinku ABOOKEN posted:Genuine question: What's the real world utility of dependent types? e: Whoops, this has already been answered thoroughly. Oh well.
|
|
#
?
Dec 2, 2016 04:44
|
|

|
Shinku ABOOKEN posted:Genuine question: What's the real world utility of dependent types? this is a really cool talk about using type providers to do type safe aws deployments https://youtu.be/QMPum88xluE
|
|
#
?
Dec 2, 2016 04:46
|
|



|
Ralith posted:e: Whoops, this has already been answered thoroughly. Oh well.
|
|
#
?
Dec 2, 2016 04:47
|
|
|
re: dependent types, https://coq.inria.fr the coq proof assistant is really cool, it uses dependent types.
|
|
#
?
Dec 2, 2016 04:50
|
|
|
Shinku ABOOKEN posted:Genuine question: What's the real world utility of dependent types? Dependent types are p much the best CS invention in my short lifetime. They can theoretically eliminate runtime errors. Making your program total and terminating is sometimes an additional benefit.
|
|
#
?
Dec 2, 2016 05:11
|
|

|
There's an Idris book whose first chapter is available online. It's worth a read if you're interested in what sort of examples Edwin Brady chose to illustrate the power of dependent types, but you won't get a lot of detail.
|
|
#
?
Dec 2, 2016 05:34
|
|




|
Alternatively, Software Foundations is available for free in its entirety. It teaches dependent types using Coq, which has many of the fancy features Idris dreams of, up to and including a smart editor tightly integrated with the compiler. This is the language that CompCert, the proven-correct C compiler, is written in.xtal posted:Dependent types are p much the best CS invention in my short lifetime. They can theoretically eliminate runtime errors. Making your program total and terminating is sometimes an additional benefit. Ralith fucked around with this message at 06:22 on Dec 2, 2016 |
|
#
?
Dec 2, 2016 06:20
|
|
|
If I want to write in Lisp and distribute a binary to my users, is Racket my best option these days?
|
|
#
?
Dec 17, 2016 14:17
|
|

|
rt4 posted:If I want to write in Lisp and distribute a binary to my users, is Racket my best option these days? I don't think that's really an issue for many Common Lisp or Scheme implementations, ie, use whatever.
|
|
#
?
Dec 17, 2016 15:51
|
|
|
Racket requires a runtime be installed so imho you might as well use Clojure. SBCL and Chicken can make static linked binaries from Common Lisp and Scheme code but they are hard to cross compile.
|
|
#
?
Dec 17, 2016 17:47
|
|
|
Athas posted:My experience is that it is terrible to use in practice. As an experiment, I had a module in my compiler that I decided to implement using all this type-level magic. While I got it to work, I ended up spending a ton of time proving arithmetic identities (like x+(y-z)=(x+y)-z) to satisfy the type checker. This is also a serious PITA in real dependently typed languages, but they generally have tooling to generate trivial but tedious proofs. I have since replaced it with dynamic checks that fail if my desired invariants are invalidated. Works fine and is much easier to understand and modify. I did research on a "practical" dependently-typed language for a year in grad school, and yeah, this was my experience: you spend a lot of time proving basically trivial things. And that was for well-known problems like discussing the length of a list; my experience with trying to prove novel things about real programs (this time in Coq) was that even formulating the types in a way that allowed a proof to proceed was just an unending series of major research problems, which is not a surprise to anybody who's ever done real mathematics, but which constantly seems to surprise the CS folks. My takeaway was that you should always strive to write code that you could make a rigorous argument about. Having done that, you should then go write good documentation about your preconditions and check them with assertions.
|
|
#
?
Dec 18, 2016 07:38
|
|

|
I find refinement typing (such as LiquidHaskell) to be a pretty good compromise between power and usability. Just being able to say simple things like "this integer argument is positive and less than 100" without having to pass around a billion proofs between functions is great for me.
Smoke_Max fucked around with this message at 14:32 on Dec 18, 2016 |
|
#
?
Dec 18, 2016 14:19
|
|

|
Does anyone know if Typed Racket or Clojure has support for quasi-dependent types? Gradual types seem like a nice compromise to me since you don't need to type absolutely everything, and you can still statically verify them.
|
|
#
?
Dec 18, 2016 18:51
|
|
|
Another interesting approach to encoding/checking code is Dafny.
|
|
#
?
Dec 18, 2016 19:24
|
|
|
xtal posted:Does anyone know if Typed Racket or Clojure has support for quasi-dependent types? Gradual types seem like a nice compromise to me since you don't need to type absolutely everything, and you can still statically verify them. rjmccall posted:I did research on a "practical" dependently-typed language for a year in grad school, and yeah, this was my experience: you spend a lot of time proving basically trivial things. And that was for well-known problems like discussing the length of a list; my experience with trying to prove novel things about real programs (this time in Coq) was that even formulating the types in a way that allowed a proof to proceed was just an unending series of major research problems, which is not a surprise to anybody who's ever done real mathematics, but which constantly seems to surprise the CS folks.
|
|
#
?
Dec 18, 2016 23:31
|
|
|
Stupid Haskell Newbie Question: I'm working through "Haskell From First Principles" and I'm confused about an exercise. The exercise says to write your own version of squish. All the answers I can find on the net are something like: code:code:
|
|
#
?
Jan 2, 2017 05:10
|
|

|
Not sure I quite understand, but "a ++ b" concatenates two lists. The second clause of squish returns x ++ squish xs, where x is a list and squish xs is also a list. If we apply it to [[1,2,3],[4,5]], we match like:code:Asymmetrikon fucked around with this message at 07:19 on Jan 2, 2017 |
|
#
?
Jan 2, 2017 05:32
|
|
|
Gnumonic posted:The anonymous function and squish2 each return a list, not the first item of a sub-list, and I can't understand why the "correct" version of squish doesn't do the same. (i.e. I can't figure out why the output isn't [[1,2,3],whatever] rather than [1,2,3,4,5]). Am I missing something really obvious?
|
|
#
?
Jan 2, 2017 07:09
|
|
|
Gnumonic posted:The head in all these functions is a list. The anonymous function and squish2 each return a list, not the first item of a sub-list, and I can't understand why the "correct" version of squish doesn't do the same. (i.e. I can't figure out why the output isn't [[1,2,3],whatever] rather than [1,2,3,4,5]). Am I missing something really obvious?
|
|
#
?
Jan 2, 2017 09:39
|
|


|
Gnumonic posted:Stupid Haskell Newbie Question: I'm also a Haskell beginner, but I'm a bit further along with you. This is how I figured this out when I ran into it a bit ago. Using GHCI, you can inspect the types of operators. Compare the types of (:) and (++) code:code:code:code:
|
|
#
?
Jan 3, 2017 14:47
|
|



|
I'm doing some Elixir practice projects and the concept of OTP and functions as processes is definitely interesting, but I'm having a hard time understanding the real world application of it and why you would want to structure a system that way, and what kind of common problems/notable systems and products call for OTP. What is it usually used for? Phoenix always talks about chat apps 'n stuff, but that seems like a different thing to me.
|
|
#
?
Jan 4, 2017 16:22
|
|



|
Pollyanna posted:I'm doing some Elixir practice projects and the concept of OTP and functions as processes is definitely interesting, but I'm having a hard time understanding the real world application of it and why you would want to structure a system that way, and what kind of common problems/notable systems and products call for OTP. What is it usually used for? Phoenix always talks about chat apps 'n stuff, but that seems like a different thing to me. Rather than making a very long post about this from scratch, I'll source a transcript of a talk I gave on 'The Zen of Erlang' that mentions what OTP can bring to system structure: http://ferd.ca/the-zen-of-erlang.html 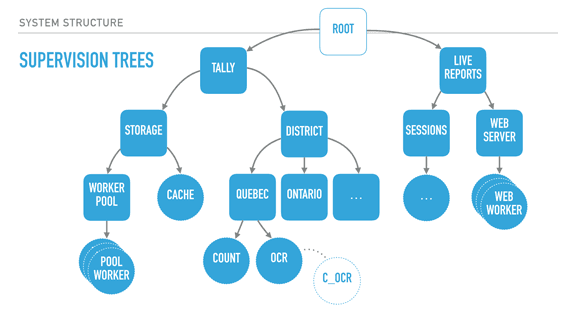 With supervisors (rounded squares), we can start creating deep hierarchies of processes. Here we have a system for elections, with two trees: a tally tree and a live reports tree. The tally tree takes care of counting and storing results, and the live reports tree is about letting people connect to it to see the results. By the order the children are defined, the live reports will not run until the tally tree is booted and functional. The district subtree (about counting results per district) won't run unless the storage layer is available. The storage's cache is only booted if the storage worker pool (which would connect to a database) is operational. The supervision strategies (one-for-one, one-for-all, rest-for-one) let us encode these requirements in the program structure, and they are still respected at run time, not just at boot time. For example, the tally supervisor may be using a one for one strategy, meaning that districts can individually fail without effecting each other's counts. By contrast, each district (Quebec and Ontario's supervisors) could be employing a rest for one strategy. This strategy could therefore ensure that the OCR process can always send its detected vote to the 'count' worker, and it can crash often without impacting it. On the other hand, if the count worker is unable to keep and store state, its demise interrupts the OCR procedure, ensuring nothing breaks. The OCR process itself here could be just monitoring code written in C, as a standalone agent, and be linked to it. This would further isolate the faults of that C code from the VM, for better isolation or parallelisation. Another thing I should point out is that each supervisor has a configurable tolerance to failure; the district supervisor might be very tolerant and deal with 10 failures a minute, whereas the storage layer could be fairly intolerant to failure if expected to be correct, and shut down permanently after 3 crashes an hour if we wanted it to. In this program, critical features are closer to the root of the tree, unmoving and solid. They are unimpacted by their siblings' demise, but their own failure impacts everyone else. The leaves do all the work and can be lost fairly well — once they have absorbed the data and operated their photosynthesis on it, it is allowed to go towards the core. So by defining all of that, we can isolate risky code in a worker with a high tolerance or a process that is being monitored, and move data to stabler process as information matures into the system. If the OCR code in C is dangerous, it can fail and safely be restarted. When it works, it transmits its information to the Erlang OCR process. That process can do validation, maybe crash on its own, maybe not. If the information is solid, it moves it to the Count process, whose job is to maintain very simple state, and eventually flush that state to the database via the storage subtree, safely independent. If the OCR process dies, it gets restarted. If it dies too often, it takes its own supervisor down, and that bit of the subtree is restarted too — without affecting the rest of the system. If that fixes things, great. If not, the process is repeated upwards until it works, or until the whole system is taken down as something is clearly wrong and we can't cope with it through restarts. There's enormous value in structuring the system this way because error handling is baked into its structure. This means I can stop writing outrageously defensive code in the edge nodes — if something goes wrong, let someone else (or the program's structure) dictate how to react. If I know how to handle an error, fine, I can do that for that specific error. Otherwise, just let it crash! This tends to transform your code. Slowly you notice that it no longer contains these tons of if/else or switches or try/catch expressions. Instead, it contains legible code explaining what the code should do when everything goes right. It stops containing many forms of second guessing, and your software becomes much more readable. 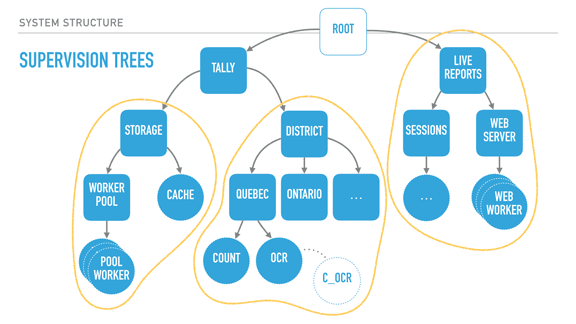 When taking a step back and looking at our program structure, we may in fact find that each of the subtrees encircled in yellow seem to be mostly independent from each other in terms of what they do; their dependency is mostly logical: the reporting system needs a storage layer to query, for example. It would also be great if I could, for example, swap my storage implementation or use it independently in other systems. It could be neat, too, to isolate the live reports system into a different node or to start providing alternative means (such as SMS for example). What we now need is to find a way to break up these subtrees and turn them into logical units that we can compose, reuse together, and that we can otherwise configure, restart, or develop independently. 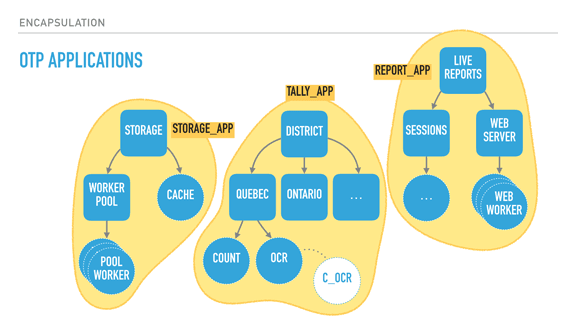 OTP applications are what Erlang uses as a solution here. OTP applications are pretty much the code to construct such a subtree, along with some metadata. This metadata contains basic stuff like version numbers and descriptions of what the app does, but also ways to specify dependencies between applications. This is useful because it lets me keep my storage app independent from the rest of the system, but still encode the tally app's need for it to be there when it runs. I can keep all the information I had encoded in my system, but now it is built out of independent blocks that are easier to reason about. In fact, OTP applications are what people consider to be libraries in Erlang. If your code base isn't an OTP application, it isn't reusable in other systems. [Sidenote: there are ways to specify OTP libraries that do not actually contain subtrees, just modules to be reused by other libraries] With all of this done, our Erlang system now has all of the following properties defined:
In a nutshell, the Zen of Erlang and 'let it crash' is really all about figuring out how components interact with each other, figuring out what is critical and what is not, what state can be saved, kept, recomputed, or lost. In all cases, you have to come up with a worst-case scenario and how to survive it. By using fail-fast mechanisms with isolation, links & monitors, and supervisors to give boundaries to all of these worst-case scenarios' scale and propagation, you make it a really well-understood regular failure case. That sounds simple, but it's surprisingly good; if you feel that your well-understood regular failure case is viable, then all your error handling can fall-through to that case. You no longer need to worry or write defensive code. You write what the code should do and let the program's structure dictate the rest. Let it crash. OTP is pretty much instrumental to that.
|
|
#
?
Jan 4, 2017 16:31
|
|

|
MononcQc posted:Rather than making a very long post about this from scratch, I'll source a transcript of a talk I gave on 'The Zen of Erlang' that mentions what OTP can bring to system structure: http://ferd.ca/the-zen-of-erlang.html Any chance you have a recording of this?
|
|
#
?
Jan 4, 2017 22:21
|
|

|
Ochowie posted:Any chance you have a recording of this? First conference was a private corporate one. I made a second presentation at reactive summit in austin earlier this year which was recorded though. https://www.youtube.com/watch?v=4ZIPijEqrNI The matching slide copies are at http://www.slideshare.net/Reactivesummit/the-zen-of-erlang
|
|
#
?
Jan 5, 2017 02:09
|
|
|
Good talk, loved the notorious bsd cameo.
|
|
#
?
Jan 6, 2017 22:52
|
|
|
What is the best language to use on a Raspberry Pi? Haskell runs fine but lens has been compiling for over a day
|
|
#
?
Jan 8, 2017 16:40
|
|
|
xtal posted:What is the best language to use on a Raspberry Pi? Haskell runs fine but lens has been compiling for over a day How is this different from normal? 
|
|
#
?
Jan 8, 2017 17:49
|
|

|
xtal posted:What is the best language to use on a Raspberry Pi? Haskell runs fine but lens has been compiling for over a day How is ghc cross-compilation? Could you compile it on a different machine and then just move the binaries over?
|
|
#
?
Jan 8, 2017 19:03
|
|



|
VikingofRock posted:How is ghc cross-compilation? Could you compile it on a different machine and then just move the binaries over? It 's awful, but maybe I can compile to C or an intermediate LLVM code and finish the process on the pi. The problem is that my build pipeline doesn't really support that.
|
|
#
?
Jan 8, 2017 19:05
|
|
|
MononcQc posted:First conference was a private corporate one. I made a second presentation at reactive summit in austin earlier this year which was recorded though. Informative and entertaining. You got multiple laughs out of me, so I assume the audience's silence was from awe at your sheer presence.
|
|
#
?
Jan 8, 2017 21:46
|
|



|
xtal posted:What is the best language to use on a Raspberry Pi? Haskell runs fine but lens has been compiling for over a day
|
|
#
?
Jan 8, 2017 22:06
|
|
|
xtal posted:It 's awful, but maybe I can compile to C or an intermediate LLVM code and finish the process on the pi. The problem is that my build pipeline doesn't really support that. You could rent some time on a fast ARM machine from Packet for 50 cents an hour, but I'm not familiar enough with GHC on ARM to tell you if you can make it work any better than full-on cross-compilation since it's going to be 64-bit.
|
|
#
?
Jan 9, 2017 00:02
|
|

|
Doc Hawkins posted:Informative and entertaining. You got multiple laughs out of me, so I assume the audience's silence was from awe at your sheer presence. Thanks. Audience was pretty sparse (was much more of a scala+kafka crowd, didn't get a lot of ears there) and without having listened to the recording, I'm guessing a directional microphone wouldn't help either.
|
|
#
?
Jan 9, 2017 00:33
|
|
|
Pollyanna posted:I'm doing some Elixir practice projects and the concept of OTP and functions as processes is definitely interesting, but I'm having a hard time understanding the real world application of it and why you would want to structure a system that way, and what kind of common problems/notable systems and products call for OTP. What is it usually used for? Phoenix always talks about chat apps 'n stuff, but that seems like a different thing to me. I enjoyed Elixir In Action. Some sections in the print version regarding data structures are a little outdated, but the author keeps the sample code up to date on a GitHub.
|
|
#
?
Jan 13, 2017 01:45
|
|
|
Any R gurus around these parts?
|
|
#
?
Jan 13, 2017 10:39
|
|
|

|
| # ? May 13, 2024 21:56 |
|
|
jynn posted:Any R gurus around these parts? I would try the Scientific/Math(s) Computing: numerical/statistical analysis tools and CASs thread over at Ask / Tell › Science, Academics and Languages.
|
|
#
?
Jan 13, 2017 13:29
|
|

