


|
Ah okay I understand now. Stab #2: use a CTE and partition by the typecode:
|
 #
?
Dec 21, 2017 15:38
#
?
Dec 21, 2017 15:38
|
|



|

|
| # ? Jun 8, 2024 07:25 |
|
|
kumba posted:Ah okay I understand now. Stab #2: use a CTE and partition by the type Thanks a bunch! This looks like a perfect solution ... unfortunately I am using MySQL 5.6 which does not seem to support CTEs and the WITH keyword 
|
|
#
?
Dec 21, 2017 15:42
|
|


|
go play outside Skyler posted:Thanks a bunch! This looks like a perfect solution ... unfortunately I am using MySQL 5.6 which does not seem to support CTEs and the WITH keyword CTEs should be logically equivalent to subqueries (though they may have different performance / caching depending on the vendor). Meaning that that query is the same as: code:
|
|
#
?
Dec 21, 2017 16:12
|
|


|
NihilCredo posted:CTEs should be logically equivalent to subqueries (though they may have different performance / caching depending on the vendor). Meaning that that query is the same as: Can�t skip the sub query. If you want to filter by a windowing function, you�ve got to do that outside of the query creating the windowing function. SELECT * FROM (SELECT ROW_NUMBER() OVER(PARTITION BY CoffeeUsage ORDER BY CoffeeFlavor) AS CoffeeRow, CoffeeFlavor FROM INeedANap) WHERE CoffeeRow > 1 (Silly query bc posting from phone.)
|
|
#
?
Dec 21, 2017 17:07
|
|

|
Just-In-Timeberlake posted:can someone help me out with this pivot, I'm a loving moron when it comes to this This request made me feel like god is dead just in time for Yule. Bravo on that timing. Assuming that you are doing this as part of another, larger, process and you only want *one* row at the end -- SELECT email, [format], [guid], label FROM (SELECT r.* FROM #temptbl r WHERE col = 'value' ) r pivot(MAX([value]) FOR r.name IN ([email],[format],[guid],[label])) p
|
|
#
?
Dec 21, 2017 18:04
|
|
|
meanieface posted:This request made me feel like god is dead just in time for Yule. Bravo on that timing. thanks, I'll give this a shot after the holidays. Just a weird requirement, but sometimes you gotta do dirty things and cash that check.
|
|
#
?
Dec 22, 2017 10:41
|
|

|
meanieface posted:Can�t skip the sub query. this is all immaterial because go play outside Skyler said they are on MySQL v5.6 and windowing functions were added to MySQL in v8.0.
|
|
#
?
Dec 23, 2017 01:32
|
|

|
code:
|
|
#
?
Dec 23, 2017 01:52
|
|
|
Hammerite posted:this is all immaterial because go play outside Skyler said they are on MySQL v5.6 and windowing functions were added to MySQL in v8.0. lmao get rekt idiot, use a real database 
|
|
#
?
Dec 25, 2017 05:43
|
|


|
I'm using http://knexjs.org/ for MySQL manipulation which is fine. But migrations are failing when I use it with MariaDB, the string indexes are the wrong length. Is there a way I can write my migrations so that they set the index length? MariaDB is supposed to be a drop in replacement for MySQL. The node adapter for MariaDB is abandoned for almost 2 years and doesn't compile on some computers using npm install.
|
|
#
?
Dec 25, 2017 21:23
|
|

|
I'm having to deal with SSIS packages for a project and the supposed SME for their team knows absolutely nothing with regards to running in command line (which we need for automation). The problem is that I'm not sure if the package is properly setting all the variables I'm passing in. Is there an easy way to get a list of "current" variables in the log during or post-execution? Currently the variables I'm passing are enough to allow the package to run, but the tables we're expecting to update aren't and it's a bit frustrating working with a blackbox where you're uncertain how the information you're handing a tool is being used internally. I've looked over the XML and ensured that all "evaluate as expression" flags are set to false, and searched over the whole doc to ensure the variables I'm setting are being used in the correct location. The especially frustrating thing is that certain variables are definitely being evaluated, as it's dumping the log file in the location and filename that's only specified by a variable. Edit: nevermind, turns out the bastards had the other variables being used inside a loop with a bad static value (  ). I manually edited their garbage and had to replace a half-dozen static values that they swore they�d updated to variable and now it�s working, at least until they change something again. ). I manually edited their garbage and had to replace a half-dozen static values that they swore they�d updated to variable and now it�s working, at least until they change something again.
PierreTheMime fucked around with this message at 04:00 on Dec 29, 2017 |
|
#
?
Dec 29, 2017 00:56
|
|

|
I'd like to create an "overlay table", where I have some immutable base set of data and then I can create a mask over the top using a second table with the same PK. In other words the view select would be: CREATE VIEW OVERLAY_VW AS SELECT CASE IF OVERLAY_TBL.COL1 IS NOT NULL THEN OVERLAY_TBL.COL1 ELSE BASE_TBL.COL1 END AS COL1 (repeat for each column) FROM BASE_TBL LEFT JOIN OVERLAY_TBL ON BASE_TBL.PK = OVERLAY_TBL.PK Is there a more graceful way to do that? The use-case here is that raw data is periodically imported from a dirty external source and I am doing both scripted and manual cleanup on top of it, so it would be nice to be able to be able to just truncate and reload that table when I get new data, while not losing any cleanup that I've already done. Paul MaudDib fucked around with this message at 03:31 on Dec 29, 2017 |
|
#
?
Dec 29, 2017 03:03
|
|

|
Paul MaudDib posted:I'd like to create an "overlay table", where I have some immutable base set of data and then I can create a mask over the top using a second table with the same PK. In other words the view select would be: COALESCE(OVERLAY_TBL.COL1, BASE_TBL.COL1) or ISNULL if you're on MSSQL.
|
|
#
?
Dec 29, 2017 15:58
|
|


|
meanieface posted:This request made me feel like god is dead just in time for Yule. Bravo on that timing. This worked by the way, so thanks!
|
|
#
?
Dec 29, 2017 19:28
|
|
|
Anyone got suggestions for books on proper relational database design? I'm thinking about starting a new project from scratch, and I want to avoid hitting the coding stage with a flawed design. Amazon says this one's good, but if anyone has a better suggestion I'd appreciate it. Sorry for asking this on page 227, but I saw nothing in the OP or the first few pages on this (just one or two posts on anti-patterns).
|
|
#
?
Dec 31, 2017 01:19
|
|

|
I need to learn how to write SQL queries for work. I just stepped through the free Stanford Relational Algebra videos and they were surprisingly engaging. Next is the SQL section of videos. I know that often times theory can be learned in the classroom but never knowingly utilized in the field. For those who write queries, how often (if ever) do you think about relational algebra? Hughmoris fucked around with this message at 01:55 on Dec 31, 2017 |
|
#
?
Dec 31, 2017 01:52
|
|
|
Hughmoris posted:I need to learn how to write SQL queries for work. I just stepped through the free Stanford Relational Algebra videos and they were surprisingly engaging. Next is the SQL section of videos. Checking this out, thanks.
|
|
#
?
Dec 31, 2017 02:24
|
|
|
Hughmoris posted:For those who write queries, how often (if ever) do you think about relational algebra? Never. Been a SQL developer for 13 years and I do schema design as a mostly intuitive thing, which is a lovely answer, I know, but seriously: never do I think explicitly in terms of the algebra.
|
|
#
?
Dec 31, 2017 05:50
|
|



|
Been a SQL analyst for 3 years, have never thought about algebra once
|
|
#
?
Dec 31, 2017 15:41
|
|
|
olives black posted:Anyone got suggestions for books on proper relational database design? I'm thinking about starting a new project from scratch, and I want to avoid hitting the coding stage with a flawed design. The answer is going to be different for transactional schema design and analytic schema design. For OLAP, The Data Warehouse Toolkit (or most things by Ralph Kimbal) is generally considered the standard. For OLTP, I'd defer to someone else' opinion.
|
|
#
?
Dec 31, 2017 19:17
|
|

|
Nth Doctor posted:Never. Been a SQL developer for 13 years and I do schema design as a mostly intuitive thing, which is a lovely answer, I know, but seriously: never do I think explicitly in terms of the algebra. Relational algebra is irrelevant to query writing and has largely been replaced by convention for schema design. If you want to design a new database, especially the query engine, or understand why the conventions are what they are, understanding the algebra becomes important.
|
|
#
?
Dec 31, 2017 19:19
|
|
|
Is there a recommended formatting/style guide I should adhere to as I start learning to write SQL queries? I'm using SSMS but the computer is pretty locked down and I don't think I'll be able to use plugins to help.
|
|
#
?
Dec 31, 2017 19:37
|
|
|
Hughmoris posted:Is there a recommended formatting/style guide I should adhere to as I start learning to write SQL queries? I'm using SSMS but the computer is pretty locked down and I don't think I'll be able to use plugins to help.
|
|
#
?
Dec 31, 2017 19:47
|
|


|
The only times I've needed to think about relational algebra are when you're trying to read a query plan and figure out what it's doing that is taking so goddamn long, and really only in a tertiary sense. It's something that's hidden "under the hood", you really shouldn't need to think about it unless you are writing a database engine yourself.
|
|
#
?
Dec 31, 2017 19:48
|
|
|
Thanks for the answers. One more beginner question: Should I be spending my time learning how to use the query builder/designer in SSMS, or should I focus instead on writing queries by hand for a while?
|
|
#
?
Dec 31, 2017 21:23
|
|
|
I've never used that particular query building tool, but I've also never wanted one. SQL is usually pretty simple. It's probably much faster just to type everything by hand once you remember all the keywords and concept.
|
|
#
?
Dec 31, 2017 22:33
|
|

|
Virtually without exception, in any type of software development the bottleneck will never be "how fast your fingers can type" and therefore any sort of GUI tool (beyond a basic IDE) is doomed to fail. Schema management tools like PowerDesigner can be really nice for handling boilerplate schema migrations but that's the only "visual" tool I use on any sort of a consistent basis. Otherwise I just use PGadmin and DBeaver.
|
|
#
?
Jan 1, 2018 00:01
|
|
|
Hughmoris posted:Thanks for the answers. One more beginner question: Should I be spending my time learning how to use the query builder/designer in SSMS, or should I focus instead on writing queries by hand for a while? I work in an office full of young support people who use SSMS four out of eight hours a day but who couldn't tell you what a trigger is. I warned them several times that by blindly following wizards and menus, instead of learning the actual SQL commands and how they work, they're practically leaving money on the table (in the form of valuable skills and future job prospects). Please don''t do the same.
|
|
#
?
Jan 1, 2018 00:44
|
|
|
NihilCredo posted:I work in an office full of young support people who use SSMS four out of eight hours a day but who couldn't tell you what a trigger is. I warned them several times that by blindly following wizards and menus, instead of learning the actual SQL commands and how they work, they're practically leaving money on the table (in the form of valuable skills and future job prospects). Please don''t do the same. Thanks for the advice. I'm not interested in taking short cuts if it'll possibly handicap me down the road. I just finished up the Wise Owl: SQL Server Queries series, and am working my way through some practice problems. Are there any SQL rooms in IRC or Discord that people hang out in, to get feedback on some simple queries I'm writing? For this particular problem: I have a Movies DB, and I want to know who the oldest actor is for each movie. My query returns the results but are there any easy improvements to be had?  SQL code:
|
|
#
?
Jan 1, 2018 23:50
|
|
|
Hughmoris posted:For this particular problem: I have a Movies DB, and I want to know who the oldest actor is for each movie. My query returns the results but are there any easy improvements to be had? One mistake: your query will return, for each movie, all the actors that share the same birth date as the oldest actor in the movie, even if those actors didn't appear in the movie.
|
|
#
?
Jan 2, 2018 00:14
|
|
|
NihilCredo posted:One mistake: your query will return, for each movie, all the actors that share the same birth date as the oldest actor in the movie, even if those actors didn't appear in the movie. I've been trying my hand at fixing this for the past 45 minutes, can't figure it out. Any tips? I can explain what I need to do in pseudo code but I'm not sure how to tackle it in SQL. Hughmoris fucked around with this message at 02:58 on Jan 2, 2018 |
|
#
?
Jan 2, 2018 01:27
|
|
|
Hughmoris posted:I've been trying my hand at fixing this for the past 45 minutes, can't figure it out. Any tips? I can explain what I need to do in pseudo code but I'm not sure how to tackle it in SQL. You want to rank the birth dates within each movie, and only select the person with the lowest birthdate for each movie, so I'd use a ranking function in your CTE: SQL code:
|
|
#
?
Jan 2, 2018 03:04
|
|
|
Hughmoris posted:I've been trying my hand at fixing this for the past 45 minutes, can't figure it out. Any tips? I can explain what I need to do in pseudo code but I'm not sure how to tackle it in SQL. The subquery is fine. You don't want to join on all the actors with the same birth date, but on all the actors with the same birth date in that movie. Add a join on tblCast to the main query.
|
|
#
?
Jan 2, 2018 03:13
|
|
|
kumba posted:You want to rank the birth dates within each movie, and only select the person with the lowest birthdate for each movie, so I'd use a ranking function in your CTE: Thank you. I haven't seen ROW_NUMBER() or PARTITION BY in my adventures yet, so I'll do some reading along with the ranking functions. NihilCredo posted:The subquery is fine. I'll give that a try. Thanks!
|
|
#
?
Jan 2, 2018 03:16
|
|
|
Different movies may have the same title as well.
|
|
#
?
Jan 2, 2018 14:58
|
|

|
One problem I haven't found a great solution to is returning nested data structures. Let's say I have two tables: Task and TaskOwner. The relationship is one-to-many, and I'm consuming the output in C# to expose it via a web API endpoint as JSON. In the example below, I'll be returning 10 rows from the Task table and all related TaskOwners. I've used two approaches in the past, and I don't love either of them:
What I'd really like is some way of returning the nested data structure directly from SQL - in a way, composing the object with a single query without returning duplicated data. Maybe this is possible with XML PATH, but that also seems ugly. Any novel approaches people have taken for this?
|
|
#
?
Jan 2, 2018 17:57
|
|


|
The novel approach would be to trust in your ORM's cache. Pull the Task data once, and whenever you access the TaskOwner property your ORM should only actually hit the DB if the TaskOwner is not already cached. Even if not, primary key lookups should be extremely fast in any database. Or if the data is sparse enough that that's a bottleneck, you do the solution with the join. Before you go implementing something crazy, are you sure that this is actually a bottleneck for you? Paul MaudDib fucked around with this message at 18:10 on Jan 2, 2018 |
|
#
?
Jan 2, 2018 18:05
|
|
|
Hughmoris posted:Thank you. I haven't seen ROW_NUMBER() or PARTITION BY in my adventures yet, so I'll do some reading along with the ranking functions. Windowed functions are really awesome and powerful, and I use them a lot. However, you need to be really careful with the window's frame. The frame of a window defines the subset of rows in which the function will work. The default frame is "BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW". That basically means, when analyzing this function across all your returned rows, only analyze rows that are between the beginning of your PARTITION and the row being calculated (not the end of your PARTITION). This can introduce a very problematic "gotchya" where your window function isn't returning the data you'd expect because the frame isn't set appropriately. If you use the LAST_VALUE() function, for example, the last row will always be the current row: 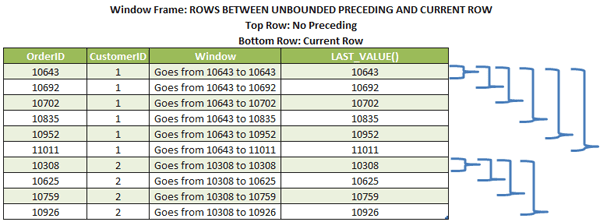 Make sure you read up on windowed functions and frames before you start using code in production. https://www.red-gate.com/simple-talk/sql/learn-sql-server/window-functions-in-sql-server-part-2-the-frame/
|
|
#
?
Jan 2, 2018 18:05
|
|
|
Paul MaudDib posted:The novel approach would be to trust in your ORM's cache. Pull the Task data once, and whenever you access the TaskOwner property your ORM should only actually hit the DB if the TaskOwner is not already cached. Yeah. It's a customer facing site where I work. The tasks are basically todo items that need to be done to complete a project. There are tens of thousands of tasks per project, and about 3 million in our system total. Each of these tasks has multiple one-to-many relationships. TaskOwner is a mapping table between the Tasks and Users table, of which we have about 50k. We currently use Entity Framework, but it imposes a costly overhead, and does not integrate well with version control due to its graphical UI. I personally really dislike EF. It also encourages our developers to tightly couple to our database structure, as they can just hook into tables directly. Due to this tight coupling, I'm nervous to change the database's structure - I'm not sure if I'll inadvertently break some developer's bad code. I'd prefer all web app interaction to go through pre-defined SQL (stored procedures). I want to move us to using something like Dapper, which I use in some personal projects - it's a Micro-ORM most notably in use at StackOverflow. Most of our queries that hit or pull from the database are already encapsulated in stored procedures, which that supports. I can really wring some great performance out of it. All I need to do is codify all the interactions as Stored Procs and force the transition. My biggest holdup is finding a way to represent these complex nested objects while minimizing the amount of data that needs to flow around. I can do it with one of the methods I mentioned, but I wish there was a better way. Ruggan fucked around with this message at 18:20 on Jan 2, 2018 |
|
#
?
Jan 2, 2018 18:17
|
|
|

|
| # ? Jun 8, 2024 07:25 |
|
|
Turns out SQL has a FOR JSON PATH formatter that can be used to make nested outputs:code:code:Anybody have experience with using FOR JSON PATH?
|
|
#
?
Jan 2, 2018 19:14
|
|