


|
Skylake X refresh is weird: https://youtu.be/DQWp7Ppz0_o I�ll wait for benchmarks, but I really can�t see any reason to go with these over Threadripper based on specs alone.
|
 #
?
Oct 11, 2018 01:32
#
?
Oct 11, 2018 01:32
|
|



|

|
| # ? May 15, 2024 03:49 |
|
|
im surprised that this is all Skylake X Refresh and not Cascade Lake. wonder if that was a name change or if they got delayed or what.
|
|
#
?
Oct 11, 2018 01:50
|
|


|
EmpyreanFlux posted:Interesting test done, not sure about the rigorousness of it though.
|
|
#
?
Oct 11, 2018 14:55
|
|

|
That opens up some interesting options for the desktop replacement/sff workstation niche. Most people will probably keep running them in desktops at max TDP though.
|
|
#
?
Oct 11, 2018 15:13
|
|



|
I know it is a bit early to ask, but has there been any whispers of new motherboard features exclusive to zen 2 like the xfr2 stuff is for Zen+?
|
|
#
?
Oct 14, 2018 00:18
|
|

|
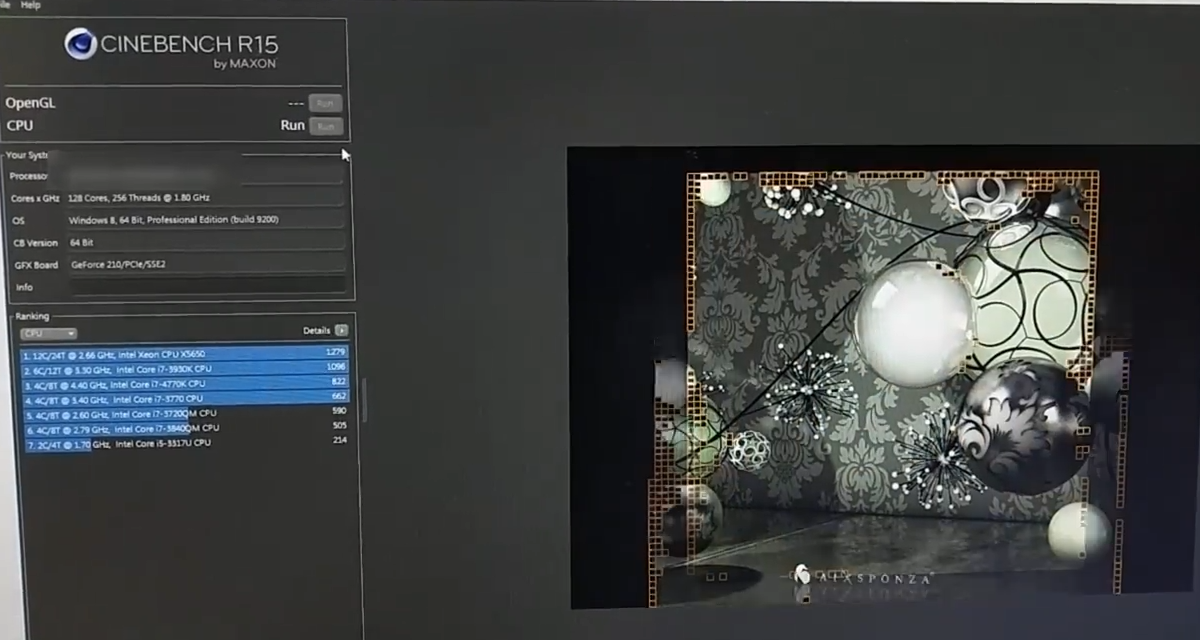
SwissArmyDruid posted:Someone out there appears to have access to Rome: That's the same one I posted a month ago when WCCF got wind of it, I think. Numbers and core counts look identical. I pointed out the world record cinebench then, too. E: It is the exact same leak, they just reposted a new article with another screenshot of the same setup. E2: That post was from the 8th, not yesterday. *sigh* I'm bad at forums. Harik fucked around with this message at 02:55 on Oct 14, 2018 |
|
#
?
Oct 14, 2018 02:47
|
|



|
Broose posted:I know it is a bit early to ask, but has there been any whispers of new motherboard features exclusive to zen 2 like the xfr2 stuff is for Zen+? Not at the moment. Being socket compatible with AM4, and assuming they will wanna release APU style SoCs for that socket, i wouldnt expect anything wild. PCIe 4 and DDR5 will need a new socket, and what I've read suggests 2020 for that stuff. If I were gonna guess, thats where we would get 10gbe too. This is me just guessing out my rear end, but I don't think is going to be much (if anything) radically architecturally different with Zen2 on the CPU or chipset side. 2020 seems to be aligning as the time to ball out.
|
|
#
?
Oct 14, 2018 08:05
|
|
|
I think Zen 2 will do PCIe 4 regardless, not sure why it'd require a new socket. Since IF is based on PCIe, IF would apparently get as speed boost, which is a nice thing for Zen.
|
|
#
?
Oct 14, 2018 13:22
|
|

|
DDR5 will require a new socket, PCIe4 can get away with just another series of traces and backwards compatibility.
|
|
#
?
Oct 14, 2018 17:53
|
|

|
PCIe4 needs more traces and more pins from what I�ve read. I guess it�s possible there are enough spare pins in AM4 to do it, and maybe you get an AM4+ situation, but I sorta doubt AMD will go that route.
|
|
#
?
Oct 14, 2018 18:49
|
|
|
Its possible they go with PCIe 4.0 for TR/Epyc (which is where the real benefit and need would be) and leave AM4 with PCIe 3.0 which is still pretty good for what it needs to do.
|
|
#
?
Oct 14, 2018 23:50
|
|
|
Does AMD have good linux support specifically for hevc encoding and decoding acceleration? As in not having to compile and load kernel modules.
|
|
#
?
Oct 14, 2018 23:54
|
|
|
lostleaf posted:Does AMD have good linux support specifically for hevc encoding and decoding acceleration? As in not having to compile and load kernel modules. It's Linux. So it'll range anywhere from just working, to needing a daily sacrifice.
|
|
#
?
Oct 15, 2018 00:40
|
|

|
Cygni posted:PCIe4 needs more traces and more pins from what I�ve read. The only loose reference I could find about more traces was speculation of the spec requiring 300-500W of power delivery on the slot, which seems conjecture since there's no new slot. --edit: Maximum trace length is 10-12" in PCIe 4.0. Anything beyond requires components called retimers. This is going to be interesting on how it'll affect cost on EATX mainboards. Combat Pretzel fucked around with this message at 00:55 on Oct 15, 2018 |
|
#
?
Oct 15, 2018 00:46
|
|
|
I went back and reread it, and it wasn�t more traces, but different (probably more expensive) design. I guess PCIe 4 signal degradation is crazy high at the new speeds, to the point that runs of more than a few inches cause some people issues. The max trace length is like 10in without retimers, and 3.0 designs aren�t usable for 4.0 implementations. https://community.keysight.com/community/keysight-blogs/oscilloscopes/blog/2017/02/08/pcie-40-is-not-simply-an-extension-of-pcie-30 Anyway I�m just googling around and probably wrong anyway so yeah!
|
|
#
?
Oct 15, 2018 01:16
|
|
|
Stanley Pain posted:It's Linux. So it'll range anywhere from just working, to needing a daily sacrifice. I was wondering if anyone had any experience because on Intel side, quicksync is working by installing vaapi thru apt sources. I'm hoping it's the same on AMD but Google didn't give me a consistent answer.
|
|
#
?
Oct 15, 2018 06:52
|
|
|
Stanley Pain posted:It's Linux. So it'll range anywhere from just working, to needing a daily sacrifice. At least when it does work, it will probably keep working. ")
|
|
#
?
Oct 15, 2018 09:25
|
|

|
Combat Pretzel posted:Again, why? The physical PCIe connectors are still the same. The extra traces might be induction compensating ground planes and other fun bits you use in high speed signaling to keep EMI to a minimum. And yeah, whoever makes the retimers and PLX chips is gonna make a killing on PCIe 4 boards.
|
|
#
?
Oct 15, 2018 09:26
|
|

|
lostleaf posted:Does AMD have good linux support specifically for hevc encoding and decoding acceleration? As in not having to compile and load kernel modules. You know, this seems like the kind of thing that Phoronix would have. https://www.phoronix.com/scan.php?page=article&item=22-systems-linux418&num=3
|
|
#
?
Oct 15, 2018 09:34
|
|
|
lostleaf posted:Does AMD have good linux support specifically for hevc encoding and decoding acceleration? As in not having to compile and load kernel modules. It sort of depends on what your hardware is. Raven Ridge requires newer kernels and versions of mesa than ship with most distros until next year, and as of this summer when last I looked only the 2400G is likely to work and the 2200G just doesn�t accelerate and sometimes needs multiple bootups to reach desktop. Your average Ubuntu user can figure out how to go to a pre-release kernel as soon as they learn ukuu exists, but moving from mainline mesa to somebody�s compiled beta without loving up your installation takes real knowledge. If you�re on dGPU+CPU, you�re probably fine. Craptacular! fucked around with this message at 10:05 on Oct 15, 2018 |
|
#
?
Oct 15, 2018 09:56
|
|

|
SwissArmyDruid posted:You know, this seems like the kind of thing that Phoronix would have. E: More thread related, is x265 really tied to single-thread performance? Since the 32-core is beaten by the 16-core and both are trounced by Intel I would have to guess so. It seems really shortsighted to design a modern codec that's tied to a single-thread as core counts explode. Harik fucked around with this message at 10:53 on Oct 15, 2018 |
|
#
?
Oct 15, 2018 10:46
|
|
|
Harik posted:That's pure CPU performance on the encoding tests, not APU acceleration. They didn't specify. I figured if they wanted APU perf, they'd have specified that, and if they wanted GPU perf, they'd have asked in the video card thread. So, strictly CPU. But on the off chance that they wanted APU, here, scroll all the way to the bottom, Windows-based, though. https://www.anandtech.com/show/12425/marrying-vega-and-zen-the-amd-ryzen-5-2400g-review/10
|
|
#
?
Oct 15, 2018 13:31
|
|
|
Harik posted:E: More thread related, is x265 really tied to single-thread performance? Since the 32-core is beaten by the 16-core and both are trounced by Intel I would have to guess so. It seems really shortsighted to design a modern codec that's tied to a single-thread as core counts explode. No that's Zen being very mediocre at workloads that make heavy use of AVX.
|
|
#
?
Oct 15, 2018 23:33
|
|

|
sauer kraut posted:No that's Zen being very mediocre at workloads that make heavy use of AVX. Something's not right with the x265 encoder on threadripper. SwissArmyDruid posted:They didn't specify. I figured if they wanted APU perf, they'd have specified that, and if they wanted GPU perf, they'd have asked in the video card thread. So, strictly CPU.
|
|
#
?
Oct 16, 2018 03:08
|
|
|
Harik posted:A 32-core going slower than a 16-core of the same architecture still doesn't make any sense. That's saying that using AVX causes it to downclock more than 50%. x264 uses AVX as well, but there AMD clearly has the lead due to more cores.
|
|
#
?
Oct 16, 2018 04:07
|
|
|
Anime Schoolgirl posted:The scheduling may just be hosed on x265, similarly to GPU performance being cut in half in some APIs when using the 2990WX. That's entirely possible, it would be interesting to see if there's an "Aha!" moment in the video encoding space where they figure out why it's so low. You're right about 265 being AVX heavy. I guess because it was a greenfield project when AVX was more available it was designed around that in a way that 264 wasn't. That surprised me and was not at all what I expected. 2x256bit AVX per core for Intel means it really plays to their strengths. Tough to tell what the 2990WX hit is, since apparently nobody has done H265 benchmarks on the epyc 7501. That would give an idea of what performance would be with proper memory bandwidth to all cores.
|
|
#
?
Oct 16, 2018 05:55
|
|
|
A cursory glance at the x265 website says two things - it's threading has accounting for NUMA nodes, likely because H.265 is quite memory intensive - it does not multithread as cleanly as older codecs because apparently macroblocks have dependencies on previous ones within a single frame Both of those together I could see giving Intel the edge. Possibly x265 doesn't have the NUMA stuff for the new big threadrippers, in which case it could improve a fair bit later. But maybe between AVX, Intel's memory controller having a bandwidth advantage over Ryzen, and HEVC not scaling to 32 cores as well, the threadripper just won't be the best CPU for ripping x265 videos.
|
|
#
?
Oct 16, 2018 07:25
|
|

|
Bits & Chips is reporting a rumor from a previously-reliable source on Zen 2 IPC: https://mobile.twitter.com/BitsAndChipsEng/status/1052194745647165441 Apparently this is on a "mixed" server workload with EPYC 2 chips.
|
|
#
?
Oct 16, 2018 23:06
|
|


|
Mr.Radar posted:Bits & Chips is reporting a rumor from a previously-reliable source on Zen 2 IPC: Khorne fucked around with this message at 23:24 on Oct 16, 2018 |
|
#
?
Oct 16, 2018 23:21
|
|
|
Mr.Radar posted:Bits & Chips is reporting a rumor from a previously-reliable source on Zen 2 IPC: isnt that the dude who posted a bunch of vega hype and then got burned? 15% would put Zen2 beyond Skylake SP in IPC (assuming this isnt an AVX specific thing), but would also take a huge change in the design of... everything. im gonna stay on team conservative on this one tbh.
|
|
#
?
Oct 16, 2018 23:29
|
|
|
He also says that TSMC 7nm N7 isn't promising a huge change in core clock as well, but if Zen2 hits 4.7ghz it'll reach max single core throughput parity with Skylake. 7nm N7+ isn't promising much better it seems, just even better power characteristics and cheaper cost. I think for Zen to clock much higher they'd have have to lengthen the pipeline and AMD seems way more inclined to make Zen wider instead.
|
|
#
?
Oct 17, 2018 00:06
|
|

|
Wider?? There have been no rumors of AMD adding more pipelines to Zen2 so I'd be kinda doubtful of that. TSMC has said their 7nm is supposed to give either 30% more clocks OR 60% power reduction (for same level of complexity) + 70% reduction to die size (all vs their 16nm process) which does actually sound pretty good. Its possible AMD focused more on power reduction if they're not getting to ~5Ghz but it could also be the leaker's CPU is a pre-release engineering sample that doesn't clock as well as the retail ones will too.
|
|
#
?
Oct 17, 2018 00:56
|
|
|
PC LOAD LETTER posted:Wider?? There have been no rumors of AMD adding more pipelines to Zen2 so I'd be kinda doubtful of that. More and better seems like a safe bet for a architecture iteration so why not go wider? 5ghz is a pipe dream anyways.
|
|
#
?
Oct 17, 2018 11:57
|
|
|
Yeah the Apple A12 went with the crazy wide and massive caches approach on the same process and I would assume that Zen 2 would do something like that as well since rumors are not pointing to much in the way of clock speed bumps, that's a guess though. I have not heard any specific rumors about the Zen 2 uarch other than that it will have wider AVX.
MaxxBot fucked around with this message at 16:20 on Oct 17, 2018 |
|
#
?
Oct 17, 2018 16:14
|
|

|
Arzachel posted:More and better seems like a safe bet for a architecture iteration so why not go wider? 5ghz is a pipe dream anyways. The relatively poor ILP of x86 was part of the reason why Intel decided to try and double down so hard with a new ISA that was supposed to have insane ILP scaling with EPIC (Itanium) back in the late 90's. They failed of course but the goals were admirable even if the implementation turned out to be a bust. ARM is supposed to scale better by going wide vs x86 (again I don't know why, I'm not a CPU architect but I've read comments by some people who seem to know their stuff and that seems to be the general opinion for quite a while now) but there are other trade offs with that ISA (IIRC worse cache usage efficiency vs x86) .
|
|
#
?
Oct 17, 2018 20:07
|
|
|
PC LOAD LETTER posted:I can't remember why exactly but x86 isn't a ISA that is inherently good at instruction level parallelism and so scaling by adding more pipelines gets hit HARD with diminishing returns after 2 pipelines or so. And both AMD and Intel have had more than that for a long time now so anything from Sandybridge era onwards is probably already about as wide as is practical anyways. Itanium depended on a magical compiler that could find parallelism when compiling an application. The uarch was laid out to take advantage of that in better ways than x86 can, but without that compiler support, it wasn't able to gain anything. If you are thinking some sort of magical compiler would also help x86 (or any uarch) multi-core then yes, it would. Also, despite spending a good chunk of change of it, neither intel nor anybody else was able to produce such a compiler. Nobody was surprised.
|
|
#
?
Oct 17, 2018 20:29
|
|

|
True but that wasn't how Intel pitched it initially (you saw where I mentioned "goals" or "supposed" and not "worked" or "actual performance" right?) and I also said it was a bust too. Yes I think a magical compiler would help x86 or any other ISA for that matter but I never said I believed one would or could ever exist either. I think you misread my post incredibly thoroughly or something if you think I believe EPIC was a good and successful idea man. edit: I also didn't say he was being harsh. The tone of his comment doesn't read that way to me. Just that he seems to be grossly misinterpreting what I said there.\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/ PC LOAD LETTER fucked around with this message at 21:32 on Oct 17, 2018 |
|
#
?
Oct 17, 2018 20:38
|
|
|
I don't think he was being overly harsh (if at all) with his comment.
|
|
#
?
Oct 17, 2018 21:15
|
|
|
PC LOAD LETTER posted:I can't remember why exactly but x86 isn't a ISA that is inherently good at instruction level parallelism and so scaling by adding more pipelines gets hit HARD with diminishing returns after 2 pipelines or so. And both AMD and Intel have had more than that for a long time now so anything from Sandybridge era onwards is probably already about as wide as is practical anyways. Modern x86 CPUs all crack instructions into micro ops and run on a RISC instruction set internally.
|
|
#
?
Oct 17, 2018 23:00
|
|
|

|
| # ? May 15, 2024 03:49 |
|
|
True but the x86 "front end" is what will dictate what those "back end" RISC-y execution units get to work on and when so that is what you're essentially forced to judge things by.
|
|
#
?
Oct 17, 2018 23:20
|
|