


|
TheFluff posted:[snip] That said, I use exists pretty much 100% of the time. Mostly because I got most of my SQL training from someone who did most of their learning when that could make a huge difference.
|
 #
?
Oct 1, 2019 15:29
#
?
Oct 1, 2019 15:29
|
|


|

|
| # ? Jun 1, 2024 17:00 |
|
|
EXISTS is safer than IN as well. Try writing a NOT IN statement and throw in a NULL....
|
|
#
?
Oct 1, 2019 16:19
|
|



|
NOT IN(subquery) is also far harder for the query planner to optimize than NOT EXISTS IIRC, although that might be Postgres-specific? Don't remember. e: right, at least it used to be that if you selected a nullable column in the subquery the query planner would go bananas. Not sure if that's the case anymore, but as mentioned you gotta make sure you don't get nulls in a NOT IN anyway. TheFluff fucked around with this message at 21:51 on Oct 1, 2019 |
|
#
?
Oct 1, 2019 21:43
|
|

|
TheFluff posted:NOT IN(subquery) is also far harder for the query planner to optimize than NOT EXISTS IIRC, although that might be Postgres-specific? Don't remember. this is true in ms-sql as well.
|
|
#
?
Oct 1, 2019 22:23
|
|


|
That was a really old version of PostgreSQL, probably 7.4. I had queries hanging on a server because of that and went thru a complete analysis and rewrite. We're talking ten orders of magnitude difference between the "obvious" solution and the eventual gyration I used to permit "not x" in a user interface. I've analyzed since then and things went from 8hr runtime to 8ms, so yeah I think they fixed it. ")
|
|
#
?
Oct 1, 2019 23:00
|
|

|
Can someone help me untangle this WHERE clause? I have daily batches of data loading into a database and in this process a new batch is loaded into a current table T1 and the current data gets moved to a previous table T2. I then do a difference between the two tables to determine activity. An issue I have is that sometimes the data are days or weeks apart and a the difference becomes artificially inflated due to the extended period between the two sequential data samples, so I'm trying to solve that by checking for the delta between two time stamps: what I'd like to happen is that if the elapsed time between two sequential files is greater than 45 hours, return zero for ppd and wupd. code:[username, team, stamp, 0, 0] Clearly there is something wrong with my logic in the WHERE clause, but I can't figure out how to rephrase it. I'd thought about adding CASE statements for the calculation of ppd and wupd, but that seems kludgy and inefficient.
|
|
#
?
Oct 2, 2019 06:22
|
|

|
Quick question about combining left and right joins. Let�s say I write this: SELECT something FROM a LEFT JOIN b ON a.id = b.id RIGHT JOIN c ON b.id = c.id Am I right to say a and b will be joined first, then the results of that gets joined with c?
|
|
#
?
Oct 2, 2019 08:35
|
|

|
Vegetable posted:Quick question about combining left and right joins. Let�s say I write this: I don't know off the top of my head. RIGHT JOINs aren't very commonly used. Is this an academic question or do you have an actual problem you want to solve (in which case you'd be better off describing what the actual problem is) My inclination was that it should work the way you described, but I tried it out: http://sqlfiddle.com/#!17/b2041f/4 and that doesn't appear to be correct, nor can I see that it follows any rule based on simple left- or right-associativity. But I haven't spent time trying to figure it out.
|
|
#
?
Oct 2, 2019 09:17
|
|

|
Basically, I want all rows from c, and I want to attach to them (some set of columns that combines a and b). The logical thing is to start with c and left join to a subquery of a & b, but I figured if I can write the whole thing without a subquery it�s neater.
|
|
#
?
Oct 2, 2019 09:19
|
|
|
I think it gets transformed into (something equivalent to) the following query involving only LEFT JOINs.code:
|
|
#
?
Oct 2, 2019 09:25
|
|
|
Agrikk posted:Can someone help me untangle this WHERE clause? code:Alternatively you could come up with a round-the-houses way of avoiding repeating that logic by using a subquery... but that would be weird and less readable IMO. Hammerite fucked around with this message at 10:12 on Oct 2, 2019 |
|
#
?
Oct 2, 2019 10:06
|
|
|
Yeah, don't complain about your query not returning rows with an elapsed time >= 45 hours when you explicitly write the query to only include rows where the time is < 45 hours. Also, as written, the query will also exclude rows where there is no previous data, defeating the left outer join you presumably used for a reason. Also, why are you using a subquery in the where condition? Either the time stamps are all the same, in which case just use t2.stamp > (t1.stamp - interval '45 hours'), or they're not all the same and the subquery will return multiple values which your DB will (should?) complain about. If the previous results are too old, can the previous column be empty (as if there were no previous results)? If so, just put the condition in the join. SQL code:
|
|
#
?
Oct 2, 2019 14:57
|
|
|
Vegetable posted:Quick question about combining left and right joins. Let’s say I write this: https://www.postgresql.org/docs/9.0/sql-select.html posted:A JOIN clause combines two FROM items. Use parentheses if necessary to determine the order of nesting. In the absence of parentheses, JOINs nest left-to-right. My question would be, If the subselect is easier to read and understand, why don't you trust your query planner and use it? Premature optimization etc.
|
|
#
?
Oct 2, 2019 15:35
|
|
|
I've been out of the database loop for a while, but have I missed a memory or is it right to be a little concerned that brand spanking new SQL stuff at work is relying very heavily on CURSOR?
|
|
#
?
Oct 2, 2019 17:58
|
|

|
Cuntpunch posted:I've been out of the database loop for a while, but have I missed a memory or is it right to be a little concerned that brand spanking new SQL stuff at work is relying very heavily on CURSOR? I'd say you'd be right to be concerned.
|
|
#
?
Oct 2, 2019 20:03
|
|



|
Nth Doctor posted:I'd say you'd be right to be concerned. Maybe? The alternatives don't seem to have gotten much better since last I checked. tyool 2019 and still no "for each row in query" loop method in TSQL, smdh.
|
|
#
?
Oct 2, 2019 20:10
|
|

|
Just-In-Timeberlake posted:Maybe? The alternatives don't seem to have gotten much better since last I checked. The problem isn't cursors, specifically. The problem is looping in SQL. Don't do it.
|
|
#
?
Oct 2, 2019 20:16
|
|

|
Tax Oddity posted:The problem isn't cursors, specifically. The problem is looping in SQL. Don't do it.  I've only had to do a few loops in SQL and in those cases, I would always generate a temp table with the data to process and then run the cursor on the pre-gathered data. Typically for sproc executions per row. Cursors can have locks maintained on the underlying data for the entire duration of the cursor.
|
|
#
?
Oct 2, 2019 20:37
|
|
|
Nth Doctor posted:
Yeah, that's my usual method, but it's still poo poo.
|
|
#
?
Oct 2, 2019 20:43
|
|
|
Jethro posted:Yeah, don't complain about your query not returning rows with an elapsed time >= 45 hours when you explicitly write the query to only include rows where the time is < 45 hours. Also, as written, the query will also exclude rows where there is no previous data, defeating the left outer join you presumably used for a reason. Also, why are you using a subquery in the where condition? Either the time stamps are all the same, in which case just use t2.stamp > (t1.stamp - interval '45 hours'), or they're not all the same and the subquery will return multiple values which your DB will (should?) complain about. This makes perfect sense, and yeah my thinking was flawed. I ended up going with the two cases statements (one for each column) and chucking the subquery. The load time and subsequent processing increased by about 60 seconds after loading 100 files (of 2300) and hopefully it won't creep up incrementally much more than that over the whole data set, but the data is "right" and that's the important thing. Thanks for your help!
|
|
#
?
Oct 3, 2019 02:28
|
|
|
n/m
Mycroft Holmes fucked around with this message at 22:09 on Oct 7, 2019 |
|
#
?
Oct 7, 2019 21:37
|
|

|
new question. I've got three problems i can't get to work. 3. Write a query to display empno column and ename column data from emp table. Display all employees who work in the same deptno with any employee whose ename contains at least one T. 5. Create a query to display empno column, ename column, sal column, and the dept�s average sal data from emp table. Display all employees who have earned more than the same deptno�s average sal. 8. Create a query to display empno column, ename column, and sal column data from emp table. Display all employees whose ename contain at least one T and have earned less than the average sal of the same job. I can't seem to get the first problem to work Select empno, ename from emp where deptno = (select deptno from emp where ename = '%T%'); this doesn't work. I can't seem to figure out how to do the dept avg salary instead of the avg of all salaries. Can't do 8 without 3 and 5
|
|
#
?
Oct 15, 2019 00:37
|
|
|
Mycroft Holmes posted:new question. I've got three problems i can't get to work. These look like homework problems. If they are, have you covered JOINs yet? Because you need to JOIN emp back to itself on deptno so you can get both the T named employees, along with their departmental Co-workers in separate columns in the same data set.
|
|
#
?
Oct 15, 2019 01:37
|
|
|
Nth Doctor posted:These look like homework problems. can't do joins, that was last lesson, we have to do subquiries.
|
|
#
?
Oct 15, 2019 02:23
|
|
|
Your example is almost right. Change where deptno = (select ...) to where deptno in(select ...) and you should be in business. A select statement doesn't return a single value so you can't use the equality operator. There was also some discussion the other week further up the page about WHERE IN() vs WHERE EXISTS() if you're curious.
|
|
#
?
Oct 15, 2019 02:42
|
|
|
cursed_schema.sql
|
|
#
?
Oct 15, 2019 07:05
|
|

|
Mycroft Holmes posted:new question. I've got three problems i can't get to work. Keep in mind you need to use the LIKE operator to do wildcard matches, the = operator will do straight equals comparison.
|
|
#
?
Oct 15, 2019 11:23
|
|




|
Like the others mentioned you have two issues: 1. Use like instead of = for wildcard comparisons (empname like �%T%�). 2. Use in instead of = for multi-list filtering. For #2 specifically you should also learn to filter via inner joined subquery (select... group by...) or (select distinct...) instead of in (select...). That will come in handy for some of your other problems.
|
|
#
?
Oct 15, 2019 15:04
|
|


|
Why would you inflict this on us?
|
|
#
?
Oct 15, 2019 17:59
|
|
|
Nth Doctor posted:Why would you inflict this on us? Why would someone even admit to doing such a thing let alone blog about it...
|
|
#
?
Oct 15, 2019 19:53
|
|



|
Bundy posted:Why would someone even admit to doing such a thing let alone blog about it... I mean, lots of people fail to understand normalization and how to apply it in an RDBMS. That isn't newsworthy. I once got in a protracted discussion with a friend of a friend who was convinced that the way to maintain last read links in forums is to have a comma delimited list of post ids in the user table. Even after I drew the diagrams out, and pointed out the maximum lengths that could fit in a column.  : well I guess the forum should stop keeping track at that point : well I guess the forum should stop keeping track at that point
|
|
#
?
Oct 15, 2019 19:57
|
|
|
Nth Doctor posted:I mean, lots of people fail to understand normalization and how to apply it in an RDBMS. That isn't newsworthy. Some people don't understand that computers are actually very good at keeping track of thousands or millions of very similar-looking data rows. They can't imagine themselves doing it/doing it in an Excel sheet, so it can't possibly be a good idea to do it in an RDBMS either.
|
|
#
?
Oct 15, 2019 20:05
|
|
|
They say that one of their goals is "avoid the need for joins as much as possible". Why do you suppose they have that as a goal? Given that they are working from seemingly bizarre premises, it is not that surprising that they have created something bizarre.
|
|
#
?
Oct 15, 2019 20:18
|
|
|
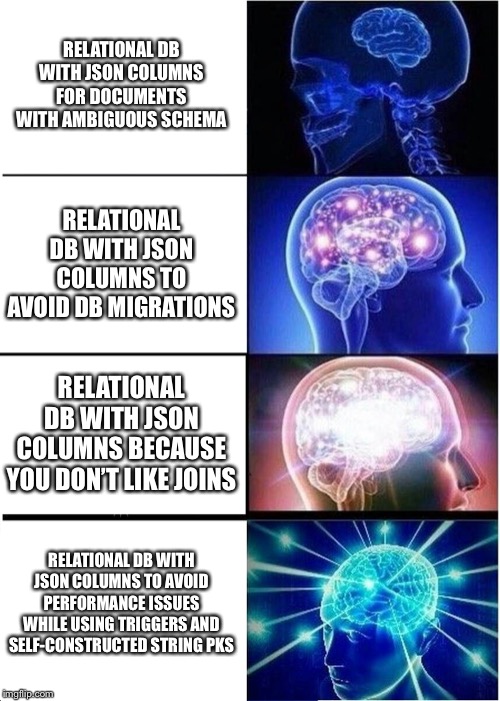
|
|
#
?
Oct 15, 2019 20:21
|
|
|
Hammerite posted:They say that one of their goals is "avoid the need for joins as much as possible". Why do you suppose they have that as a goal? Given that they are working from seemingly bizarre premises, it is not that surprising that they have created something bizarre. quote:Avoid the need for joins as much as pos- 
|
|
#
?
Oct 15, 2019 20:55
|
|
|
yeah, when it got to the part where they were rolling their own PKs I had to make sure I wasn't reading the Onion
|
|
#
?
Oct 15, 2019 20:58
|
|
|
Okay I skimmed it but had to go back and read it.quote:custom JSON.NET Contract Resolver to ensure that properties that are already saved in other columns of the table aren't duplicated in the JSON quote:For a many-to-many, we do something a bit naughty: we store the values with | characters between each value: quote:Each time the row is written, we split the values, and use the MERGEstatement to keep a join table up to date: (trigger is delete then insert cross apply) quote:
 Why didn't they just use Access? Or Excel? quote:SQL Server 2016 is introducing support for JSON,... it'll take a while before we can rely on these features. Well thanks for sharing an article demonstrating how not to do many things. I'm gonna need a drink now.
|
|
#
?
Oct 15, 2019 23:21
|
|

|
I realize this is an old post of theirs, but I'm most angry that I've used Octopus Deploy, though we're in the middle of phasing it out. I should share this around the office because every single one of our devs knows better.
|
|
#
?
Oct 15, 2019 23:44
|
|
|
Hammerite posted:They say that one of their goals is "avoid the need for joins as much as possible". Why do you suppose they have that as a goal? Given that they are working from seemingly bizarre premises, it is not that surprising that they have created something bizarre. a lot of devs are really, really scared of joins for some reason. they often say "performance!" but i think they're really just nervous and intimidated by sql
|
|
#
?
Oct 16, 2019 02:23
|
|
|

|
| # ? Jun 1, 2024 17:00 |
|
|
redleader posted:a lot of devs are really, really scared of joins for some reason. they often say "performance!" but i think they're really just nervous and intimidated by sql It's this and never making indices
|
|
#
?
Oct 16, 2019 02:27
|
|