


|
RIP Syndrome posted:Just guessing since I've barely tried SDXL myself, but it's possible a1111 makes bad assumptions for it if you upscale directly in the txt2img UI. If you're not using latent upscaling anyway, you might as well send to extras and do the upscaling there once you get an 1x image you like. That works for me (tried with 4x-UltraSharp). Didn't have any luck replicating the style, but still had some real bangers anyway:   
|
 #
?
Jul 31, 2023 21:28
#
?
Jul 31, 2023 21:28
|
|



|

|
| # ? May 29, 2024 17:03 |
|
|
Those look great!       
|
|
#
?
Jul 31, 2023 21:59
|
|

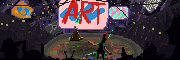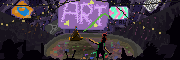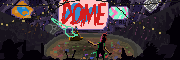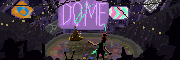
|
hydroceramics posted:Didn't have any luck replicating the style, but still had some real bangers anyway: I used the DreamshaperXL10 alpha2 model from CivitAI with a mashup of style prompts I'd stored. img2img overwrites the metadata from the initial txt2img, but I think "retro anime, pastels, by moebius" should get you most of the way there. If it doesn't come out Moebius enough you can insist on 2d, flat cel shading, etc. quote:Wow. Are you using the vanilla SDXL model? I tried doing cityscapes with 1.5 models, but couldn't touch that level of detail at all. Ended up chasing flatter styles. Fan of this, it looks almost like a photo/image collage, and the light is great.
|
|
#
?
Jul 31, 2023 23:11
|
|

|
For people using SDXL under Automatic1111, what settings are you using for generation? SDXL seems to be very finicky about resolutions; I read that it wants 1024x1024 or something with the same number of pixels? What resolutions have you had luck with? Is HiResFix still required/useful for non-square output sizes? And I remember reading a while back about the newer models requiring far fewer rendering steps. Until this week I'd still been using SD 1.5 with Euler A and 20-40 steps. Is there guidance on what to use with SDXL?
|
|
#
?
Jul 31, 2023 23:43
|
|

|
RIP Syndrome posted:Fan of this, it looks almost like a photo/image collage, and the light is great. Thanks! Prompt was (wildflowers), Baphomet, mountain climbing, (cyberpunk), diffuse lighting, gothic, detailed, intricate, geometric, elegant, highly detailed, lifelike, photorealistic, digital painting, artstation, illustration, concept art, smooth, sharp focus, sci-fi, hyper realistic, oversaturate, dramatic lighting, colorful 1024x1024 is a good spot. I find 800x1000 works fine. 512x512 comes out like this.   prompt "something super cool" in SDXL at 5, 10 and 25 steps. I've generally stuck with 25. 5 step   10 step   25 step   
|
|
#
?
Aug 1, 2023 00:00
|
|
|
WhiteHowler posted:For people using SDXL under Automatic1111, what settings are you using for generation? I saw somewhere the ratio chart that SEEMS to work, though I'll typically get something then render out resolutions in an editing program so I'm atypical anyway. Here is the ratio chart for Stable Diffusion XL 1.0: 640 x 1536 768 x 1344 832 x 1216 896 x 1152 1024 x 1024 1152 x 896 1216 x 832 1344 x 768 1536 x 640
|
|
#
?
Aug 1, 2023 00:23
|
|



|
        
|
|
#
?
Aug 1, 2023 00:49
|
|

|

|
|
#
?
Aug 1, 2023 00:59
|
|
|
RIP Syndrome posted:I used the DreamshaperXL10 alpha2 model from CivitAI with a mashup of style prompts I'd stored. img2img overwrites the metadata from the initial txt2img, but I think "retro anime, pastels, by moebius" should get you most of the way there. If it doesn't come out Moebius enough you can insist on 2d, flat cel shading, etc. Just using midjourney 5.2. Don't have the time/computing power to do anything else well.
|
|
#
?
Aug 1, 2023 01:24
|
|
|
 
|
|
#
?
Aug 1, 2023 02:02
|
|
|
https://www.youtube.com/watch?v=Ok7GVnNP_Fg
|
|
#
?
Aug 1, 2023 06:19
|
|


|
More beginner questions. How do I go about getting bigger outputs? (There has been a bit of talk in the last couple of pages but it goes right over my head). I'm using Stable Diffusion. 1.5 maybe? Just checked - it's A1111 The maximum size I can generate is 512 by 768 otherwise I get vram errors (6 gig card). Was there a start-up setting mentioned a while ago that would allow slower generation to avoid the errors? Failing that, or anything else within SD itself, what's a recommended upscaling tool(?) to try, ideally with a tutorial available? Here's my launcher settings, for what it's worth. 
Clarence fucked around with this message at 09:08 on Aug 1, 2023 |
|
#
?
Aug 1, 2023 08:56
|
|

|
I was going to suggest the low vram setting but looks like you already got it. Google around a bit for your specific video card and auto1111 and you might find a solution, everything moves like lightning so its a bit tough to nail anything specific down. If it errors out a bunch make sure you reset everything to default and relaunch from the batch file. I had a few instances where trying out different settings broke the whole thing until a restart, so it might not be the resolution specifically rather than a combination of things. On my 6GB card I was doing 800x600 and sometimes larger so it should be possible. Have a goat that ate the special flowers. He's very very chill. 
|
|
#
?
Aug 1, 2023 13:58
|
|
|
Clarence posted:More beginner questions. It's hard to get big images that also look nice, even when there's enough vram. SD makes the nicest images when you generate at the size it's trained with (for SD 1.5 that's 512x512. For SDXL it's 1024x1024). You can go higher, but the higher you go the more confused the output will be. It'll show up as repeated subjects, weird anatomy, people (or just y'know, body parts) floating in the air and so on. If you're making something that's inherently repetitive, like machinery or isometric cityscapes, you can make it work for you, though. So the "proper" way to do it is to generate at 512x512 or close to it, and then use an upscaler. You can do this directly by enabling the Hires.fix checkbox. There's a special kind of upscaler called "latent" that will embellish the image with more details, but it tends to change the style of the whole image (often for the worse). You can get around it by reducing the "denoise" factor, but if you reduce it too much it'll leave noise in the image. Usually you can walk it down to 0.51 or so before things go bad. When you see something you like, it's a good idea to save the seed (hit the ♻️ icon next to the seed number) and do repeat runs to experiment with CFG, denoise factor and upscalers. When doing latent upscaling it's easier to preserve the image style when upscaling by less. I use 2x at most, but you can go lower, to 1.5 for instance. Finally there are upscalers that don't add any details but are mostly about leaving smooth edges and preserving the micro-style of the image. You can use those in Hires.fix, but there's not really any point, since you can "send to extras" and do the upscaling there when you're done with the hard part. I think these upscalers are pretty lightweight. Out of the stock ones I've gotten good performance out of SwinIR, but there's a whole ton of them to try. Download more here and place in the models\ESRGAN\ directory. I don't really know which ones are good, but 4x-UltraSharp seems ok. There are many specialized ones like, for instance, 2x_Loyaldk-SuperPony which is trained to upscale MLP episodes only. Have fun. To sum up the process I've used: * Start small, increase until you hit vram/quality limits. Heavyweight step. * Enable the latent upscaler, don't go too hard with it (1.5x-2.0x and as low a denoise as you can get away with). Regenerate. * Send to extras and do a basic upscale with SwinIR or whatever looks best (2x-4x). This should be lightweight. That should get you into the 2048x2048 range at least. Though I haven't tested this on 6 gigs of vram, so there may be hard limits I don't know about. Maybe try some of the official optimizations. --lowvram and --xformers seem like the obvious ones. There are also more complicated ways to get more detail and higher resolution by taking an initial image and upscaling/embellishing it in parts. Manual in/outpainting is one way, and there are promising-looking extensions like this one that automate the process. That one doesn't seem to work with the most recent auto1111, though. It seems popular, so maybe it'll get fixed. You can also download different models/checkpoints from CivitAI. Some are better at details than others. I've gotten good results from Dreamshaper and Juggernaut. 
|
|
#
?
Aug 1, 2023 14:21
|
|
|
If you lock the seed you can usually also use tile diffusion with 1.5 (i don't think it worked with 2.x so probably doesn't work with XL). This will let you add more details, You'll need to play with the settings and sometimes some images just don't want to upscale well with tiles and *must* make a mess these I just normal upscale. You do need to play with the tiled upscales like a normal image gen a bit to get good results. I've posted this before but this was made without leaving A1111 in 1.5 and tile diffusion. I did some sub regions to vary the prompt in different places and you can see the hard lines for them if you look for them, that is not an effect of tiling unless you do no overlap. This was done on a 3070 Mobile with 8GB VRAM. (that final 3k upscale was a good 90 minutes though!) 
|
|
#
?
Aug 1, 2023 14:28
|
|


|
Sometimes there're also system tasks competing for GPU resources. Once when I hit Win+Shift+Ctrl+B after a GPU crash, some nvidia display popped up showing a task list with some stuff, like the thing that thumbnails your images and sends them to Microsoft or whatever. Dunno how much vram it uses at peak, but I killed it and moved its exe to a quarantine zone.
|
|
#
?
Aug 1, 2023 14:40
|
|
|
By the way, I just noticed it says "Low VRAM (medvram)" and it's turned into --medvram. Try unchecking that and instead adding --lowvram to the additional options.  Post your spookiest posting stations!
|
|
#
?
Aug 1, 2023 18:57
|
|
|
I was thinking about Bioshock recently and this image is a great fit that that creepy vibe.
|
|
#
?
Aug 1, 2023 19:04
|
|

|
RIP Syndrome posted:By the way, I just noticed it says "Low VRAM (medvram)" and it's turned into --medvram. Try unchecking that and instead adding --lowvram to the additional options. I think that's done the trick. Before if I checked hires.fix it would error quite quickly. This time I've tried a 768 x 512 with --lowvram and it's gone all the way through. Thanks for the help everyone!
|
|
#
?
Aug 1, 2023 19:57
|
|
|
Hadlock posted:Yeah well for one, it's possible to compile a binary from python code so you don't need to install python, python on windows is getting better but it's still a pain in the dick. The distributable copy of automatic1111 should be a self contained binary, period ComfyUI is fantastic and has a --cpu flag I got it working in about 2 minutes on my no GPU poverty grade 8gb ram thinkpad. Was like 260 s/itr but I was able to generate a good image from it  https://github.com/comfyanonymous/ComfyUI code:xformers version: 0.0.20 Set vram state to: DISABLED Device: cpu Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention Starting server To see the GUI go to: http://127.0.0.1:8188 got prompt model_type EPS adm 2816 making attention of type 'vanilla' with 512 in_channels Working with z of shape (1, 4, 32, 32) = 4096 dimensions. making attention of type 'vanilla' with 512 in_channels left over keys: dict_keys(['cond_stage_model.clip_l.transformer.text_model.embeddings.position_ids']) 0%| | 0/20 [00:00<?, ?it/s] 5%|████▊ | 1/20 [04:24<1:23:35, 263.99s/it] 25%|███████████████████████▊ | 5/20 [21:46<1:05:04, 260.29s/it] 50%|████████████████████████████████████████████████ | 10/20 [43:03<42:49, 256.92s/it] 95%|█████████████████████████████████████████████████████████████████████████████████████████▎ | 19/20 [2:45:33<05:46, 346.28s/it] 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [2:53:53<00:00, 521.66s/it] Prompt executed in 5586.78 seconds ^C Stopped server Hadlock fucked around with this message at 21:07 on Aug 1, 2023 |
|
#
?
Aug 1, 2023 21:03
|
|
|
RIP Syndrome posted:By the way, I just noticed it says "Low VRAM (medvram)" and it's turned into --medvram. Try unchecking that and instead adding --lowvram to the additional options. zoom calls  
|
|
#
?
Aug 1, 2023 21:54
|
|
|
KakerMix posted:zoom calls Don't dox my boss, haha... er hang on, someone's at the door 
|
|
#
?
Aug 1, 2023 23:59
|
|
|
angry Donald Trump as a baseball pitcher throwing a hamburger like a ball, ((television in the background showing news of "criminal indictment")), ((ketchup stains on the walls)), in Mar-A-Lago, realistic angry and crying Donald Trump holding a hamburger as a baseball pitcher, (throwing the hamburger like a baseball) at a wall in Mar-A-Lago, (ketchup stains on walls), screen in the background with ((news program)) ((ticker text "criminal indictment")), realistic 
|
|
#
?
Aug 2, 2023 04:05
|
|

|
This is possibly one of the best images posted in this thread, fantastic 
|
|
#
?
Aug 2, 2023 08:41
|
|
|
Which 1.5 models have been trained to handle higher resolutions? I know wyvernmix can do 768x1024
|
|
#
?
Aug 2, 2023 09:01
|
|

|
I like the one that says WS CRIIMMAL INDUDUICENT UP! with the burger-shaped head crab.    
|
|
#
?
Aug 2, 2023 13:20
|
|
|
I did some messing around with comfyUI and SDXL on my laptop last night was very easy to setup. Is the base 1.0_0.9VAE just the 1.0 with a baked in VAE for 0.9? it's huge for a VAE! I think I got comfy UI running in colab too (it boots, waiting on checkpoints to upload)
|
|
#
?
Aug 2, 2023 16:03
|
|
|
pixaal posted:I did some messing around with comfyUI and SDXL on my laptop last night was very easy to setup. Is the base 1.0_0.9VAE just the 1.0 with a baked in VAE for 0.9? it's huge for a VAE! Yes, I'm pretty sure it's the whole thing including the VAE. I think they reverted to an older VAE because the 1.0 one had some bad artifacting. GH issue: https://github.com/huggingface/diffusers/issues/4310 RIP Syndrome fucked around with this message at 17:15 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 16:28
|
|
|

|
|
#
?
Aug 2, 2023 17:51
|
|

|
That chair's gonna give you a bad back.  I tried inpainting the hood area and sort of hosed it up. Can't find a surefire way to do it in a1111 without leaving halos.
|
|
#
?
Aug 2, 2023 18:35
|
|
|
I'm playing with SDXL 1.0 with the 1.0 VAE because that's what I was uploading earlier and then had to troubleshoot some errors did some known figure and upscaler testing figuring out the Comfy UI I layout I found this one is something I've seen from no model, Trump was given facial hair (and it's even unprompted unless tired and haggard count)   This handles prompts a bit differently need to figure out why his hand is in 4 pieces  Based off the Danny prompt (it still includes his name horrifyingly enough)  okay I think I needed more supporting terms it's figuring it out  It really keeps trying to go back to this comicbook look, not that I don't like it but I don't always want it.  maybe someone has an idea   I'm sure it's in the mess of settings still at default pixaal fucked around with this message at 18:53 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 18:51
|
|
|
pixaal posted:It really keeps trying to go back to this comicbook look, not that I don't like it but I don't always want it. It usually helps to specify the style you want, e.g. "photo". Otherwise you get whatever. You can be more specific about the imaging tech, for instance try "35mm", "kodachrome", camera models and so on. E.g. "hdr polaroid" (nonsensical combinations can work):  When making a negative prompt, you can check if you're on the right track by pasting it by itself in the positive prompt.  The above is from 1.5 with the following in the positive: quote:lowres, low resolution, thumbnail, preview, template, deformed, distorted, beginner, amateur, low quality, bad quality, worst quality, overexposed, underexposed, aberration, video game, screenshot, captcha, forum, watermark, meme, text, signature, blurry, cropped, poorly drawn, glitch, aliasing, censored
|
|
#
?
Aug 2, 2023 19:32
|
|
|
RIP Syndrome posted:It usually helps to specify the style you want, e.g. "photo". Otherwise you get whatever. You can be more specific about the imaging tech, for instance try "35mm", "kodachrome", camera models and so on. E.g. "hdr polaroid" (nonsensical combinations can work): I haven't had problems with 1.5, 2.1 or Bing, this is specifically an SDXL issue or whatever the hell that workflow on comfyUI is. Like it generally leans really hard into realistic that you don't need to add more realism words. Maybe SDXL is just more balanced?
|
|
#
?
Aug 2, 2023 19:39
|
|
|
pixaal posted:I'm playing with SDXL 1.0 with the 1.0 VAE because that's what I was uploading earlier and then had to troubleshoot some errors What does ComfyUI's "settings" or "config" export format layout look like. Would be neat if they had a QR code export option for that. These workflows look like they can/will get complex fast Maybe in your negative prompts add "jack kirby" and "Sam Kieth" and "Todd McFarlane" who are all comic book artists; also "marvel comics" and "dc comics"
|
|
#
?
Aug 2, 2023 19:46
|
|
|
Two other things that give me bad results (often naive sketch/comic styles) with SDXL and a1111: - Generating at less than 1024x1024. - Trying to upscale with the refiner. I've only gotten it to work well at 1:1. But I don't know about ComfyUI. Maybe there's some implicit resampling step going wrong. I'd leave the refiner out altogether while looking for the cause, as it's not really critical.
|
|
#
?
Aug 2, 2023 19:50
|
|
|
Hadlock posted:What does ComfyUI's "settings" or "config" export format layout look like. Would be neat if they had a QR code export option for that. These workflows look like they can/will get complex fast it's a Json that workflow is the 1.0 from here https://github.com/SytanSD/Sytan-SDXL-ComfyUI It's not even the most complicated one I looked at, but that one needed an addon I couldn't get installed in colo and will have to take a look at on hardware tonight. This guy has a ton of weird ones this is their example not mine: https://github.com/wyrde/wyrde-comfyui-workflows/tree/main  e: What the one I'm using is doing is 20 steps with the base one then passing that off to the refiner for the final 10 steps then it makes the image on the left then it passes that off to an upscaler and makes the image on the right e2: getting kind of busy with actual stuff I need to do but photo does seem to be what was missing. XL seems much more neutral than previous models. I've just been able to apply so much to both 1.5 and 2.1 I didn't think XL would be this different (or maybe it's an artifact of how comfy is working) pixaal fucked around with this message at 20:04 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 19:51
|
|
|
Silly simple prompts in DucHaiten-Journey. satan's own chihuahua, yapping at the gates of hell   satan's best buddy, waiting at the gates of hell for him to get off work:    I get a 1990s adventure game vibe from the second, and 2010s HD remake from the third.
|
|
#
?
Aug 2, 2023 21:12
|
|


|
   
Sedgr fucked around with this message at 21:40 on Aug 2, 2023 |
|
#
?
Aug 2, 2023 21:17
|
|
|
Weeks ago when Meta's music AI was being talked about someone mentioned a sound effects maker would be cool. Well: https://ai.meta.com/blog/audiocraft-musicgen-audiogen-encodec-generative-ai-audio/  The picture itself isn't too wildly special, but it is the result of me loving around with the [url=https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin#how-to-install]photoshop plugin[./url] using Stable Diffusion XL to figure out how to use it. Lots better than the previous one with Krita. Not only because it's Photoshop and I'm far more familiar with it, but also in how it handles using SD inside an image editing suite. KakerMix fucked around with this message at 00:17 on Aug 3, 2023 |
|
#
?
Aug 3, 2023 00:12
|
|
|

|
| # ? May 29, 2024 17:03 |
|
|
okay I think I'm getting the hang of XL the key phrase for realistic is "live action" no quotes with space photograph  live action  neither 
pixaal fucked around with this message at 01:33 on Aug 3, 2023 |
|
#
?
Aug 3, 2023 00:59
|
|