- Just-In-Timeberlake
- Aug 18, 2003
-

|
I'll try to make it clear as to what I want to do here. I want to get a result set of all the stores in our system, with their total sales for each month for 2008. This is what I have so far
code:SELECT DISTINCT STORE_NUMBER,
(SELECT SUM(INVOICE.INVOICE_TOTAL_AMOUNT) AS EXPR1
FROM INVOICE
INNER JOIN SITE
ON INVOICE.SITEID = SITE.SITEID
WHERE (MONTH(INVOICE.INVOICE_DATE) = 1)
AND (YEAR(INVOICE.INVOICE_DATE) = 2008)) AS JANUARY08,
(SELECT SUM(INVOICE_1.INVOICE_TOTAL_AMOUNT) AS EXPR2
FROM INVOICE AS INVOICE_1
INNER JOIN SITE AS SITE_2
ON INVOICE_1.SITEID = SITE_2.SITEID
WHERE (MONTH(INVOICE_1.INVOICE_DATE) = 2)
AND (YEAR(INVOICE_1.INVOICE_DATE) = 2008)) AS FEBRUARY2008
FROM SITE AS SITE_1
code:Store January February
00001 125.36 175.36
00002 563.23 600.25
code:Store January February
00001 688.59 775.61
00002 688.59 775.61
etc.
|
 #
¿
Sep 11, 2008 22:26
#
¿
Sep 11, 2008 22:26
|
|
- Adbot
-
ADBOT LOVES YOU
|

|
|
#
¿
May 17, 2024 20:17
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
MoNsTeR posted:
The immediate problem is that the SITE table in your subqueries is a different copy of the table than the one in your outer query. Refer to SITE_1 instead. But, that still might not work properly... I don't understand your data model from what you've shown. Why the DISTINCT? What's the relationship between a store and a site, and why do invoices have a site id but not a store number?
edit:
Maybe this will help... If you wanted to select sites, and each site's sales, you could do:
code:select s.site_id
, sum(case when i.invoice_date >= '01-JAN-2008'
and i.invoice_date < '01-FEB-2008'
then i.invoice_total_amount
else 0
end) as JANUARY_08
, sum(case when i.invoice_date >= '01-FEB-2008'
and i.invoice_date < '01-MAR-2008'
then i.invoice_total_amount
else 0
end) as FEBRUARY_08
from site s
, invoice i
where s.siteid = i1.siteid
group by s.siteid
code:select s.site_id
, (select sum(i.invoice_total_amount)
from invoice i
where i.siteid = s.siteid
and i.invoice_date >= '01-JAN-2008'
and i.invoice_date < '01-FEB-2008') as JANUARY_08
, (select sum(i.invoice_total_amount)
from invoice i
where i.siteid = s.siteid
and i.invoice_date >= '01-FEB-2008'
and i.invoice_date < '01-MAR-2008') as FEBRUARY_08
from site s
I'll give this a try in the morning, but to answer your questions:
The DISTINCT probably isn't necessary, probably typed it in without thinking.
There are 2 tables of interest, SITE and INVOICE. The SITE table holds the store information, ie. Store Number, Address, State, Zip, etc. The INVOICE table joins on the SiteID attaching that invoice to that store/site. Sorry about the confusion, I neither created nor named the SITE table.
|
|
#
¿
Sep 12, 2008 01:08
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Victor posted:
golgo13sf, what RDBMS are you using?
MSSQL.
Also, that solution above worked aces. Thanks.
|
|
#
¿
Sep 12, 2008 02:49
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Victor posted:
If you have SQL2005, this will run faster and be much easier to maintain:
code:select *
from (
select s.store_number,
month = month(i.invoice_date),
total = sum(i.invoice_total_amount)
from invoice i
inner join site s on s.siteid = i.siteid
where i.invoice_date >= '1/1/08' and i.invoice_date <= '1/1/09'
group by s.store_number, month(i.invoice_date)
) by_month
pivot (sum(total) for month in ([1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12])) p
Son of a bitch, this kicks rear end.
|
|
#
¿
Sep 12, 2008 14:46
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I am in the process of cleaning up our website code and moving all the queries from the pages into stored procedures and I'm running into a performance issue for the query on our invoice lookup page. If I run a query like so:
code:SELECT <Field list>
FROM Table
WHERE Table.Invoice_Rule_95 = '12345'
code:DECLARE @filtertype varchar(10);
DECLARE @filtervalue varchar(20);
SET @filtertype = 'purchaseorder';
SET @filtervalue = '12345';
SELECT <Field List>
FROM Table
WHERE
CASE
WHEN @filtertype = 'purchaseorder' THEN
CASE WHEN Table.Invoice_Rule_95 = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'invoicenumber' THEN
CASE WHEN Table.Invoice_Number = @filtervalue THEN 1 ELSE 0 END
END = 1
|
|
#
¿
Feb 12, 2009 23:08
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Xer� posted:
Theoretically, separate procs might be a cleaner solution, but I'd like to see the database design underneath this proc just to see why you need to query like this.
The most flexible solution would probably be Dynamic SQL. It'll perform better than conditional where clauses. Just be sure to use sp_executesql to execute your query and not EXEC. I hate Dynamic SQL as much as any DBA, but sometimes you have to grin and bear it.
Here is a screen shot of the invoice search area on our site
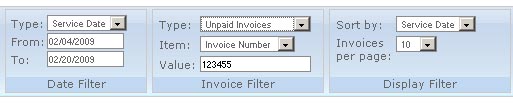
So there are several fields one could use to find an invoice, like say this pseudocode
code:SELECT all invoices
WHERE the invoice date is in January with the a driver's name of "Mike" and the invoice is unpaid
ORDER BY the invoice date in descending order.
Here is the full stored procedure code (sanitized), sorry if it breaks tables
code:ALTER PROCEDURE PROCEDURE_NAME
-- Add the parameters for the stored procedure here
@datesearchtype VARCHAR(10),
@startdate DATETIME = NULL,
@enddate DATETIME = NULL,
@invoicepaidtype VARCHAR(10),
@filtertype VARCHAR(20),
@filtervalue VARCHAR(100),
@sortfield VARCHAR(50),
@dir VARCHAR(4)
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
/*GET THE INVOICES*/
SELECT i.[InvoiceID], i.[Invoice_Number], i.[Invoice_Date], s.[Store_Number], d.[Driver_Name],
v.[Vehicle_Make_Year], v.[Vehicle_Make], v.[Vehicle_Model],
l.[License_Tag_State], l.[License_Tag_Number], i.[Invoice_Total_Amount],
(dbo.i.Invoice_Total_Amount - dbo.i.Prepaid_Total_Amount +
dbo.i.Invoice_TotalDiscounts + dbo.i.Invoice_TotalAdjustments -
dbo.i.Invoice_TotalPaymentsReceived) AS [Invoice_Balance],
(i.[Invoice_TotalDiscounts] + i.[Invoice_TotalAdjustments]) AS Invoice_Discount,
i.Invoice_TotalPaymentsReceived, i.[Invoice_Rule_90], i.[Invoice_Rule_97], i.[Invoice_Rule_95]
FROM dbo.i INNER JOIN
dbo.s ON dbo.i.SiteID = dbo.s.SiteID INNER JOIN
dbo.d ON dbo.i.FleetID = dbo.f.FleetID INNER JOIN
dbo.l ON dbo.i.LicenseID = dbo.l.LicenseID INNER JOIN
dbo.v ON dbo.i.VehicleID = dbo.v.VehicleID INNER JOIN
dbo.d ON dbo.i.DriverID = dbo.d.DriverID LEFT OUTER JOIN
fp ON i.[InvoiceID] = fp.[InvoiceID] LEFT OUTER JOIN
pp ON i.[InvoiceID] = pp.[InvoiceID] LEFT OUTER JOIN
dp ON i.[InvoiceID] = dp.[InvoiceID] LEFT OUTER JOIN
ci ON i.[InvoiceID] = ci.[InvoiceID]
WHERE
CASE --FILTER WHERE CLAUSE
WHEN @filtertype = 'fleetid' THEN CASE WHEN i.[FleetID] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'fleetcode' THEN CASE WHEN f.[Fleet_Code] LIKE '%' + @filtervalue + '%' THEN 1 ELSE 0 END
WHEN @filtertype = 'fleetname' THEN CASE WHEN f.[Fleet_CompanyName] LIKE '%' + @filtervalue + '%' THEN 1 ELSE 0 END
WHEN @filtertype = 'disputedreference' THEN CASE WHEN dp.[DisputedPendingID] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'fleetpaymentnum' THEN CASE WHEN fp.[FleetPaymentID] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'invoicenumber' THEN CASE WHEN i.[Invoice_Number] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'storenumber' THEN CASE WHEN s.[Store_Number] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'driver' THEN CASE WHEN d.[Driver_Name] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'vehiclemake' THEN CASE WHEN v.[Vehicle_Make] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'vehiclemodel' THEN CASE WHEN v.[Vehicle_Model] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'license' THEN CASE WHEN l.[License_Tag_Number] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'ponum' THEN CASE WHEN i.[Invoice_Rule_95] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'authnum' THEN CASE WHEN i.[Invoice_Rule_97] = @filtervalue THEN 1 ELSE 0 END
WHEN @filtertype = 'servicecardnum' THEN CASE WHEN i.[Invoice_Rule_90] = @filtervalue THEN 1 ELSE 0 END
ELSE 1
END = 1
AND
CASE /*INVOICE DATE TYPE WHERE CLAUSE*/
WHEN @datesearchtype = 'service' THEN CASE WHEN i.[Invoice_Date] >= @startdate AND i.[Invoice_Date] <= @enddate THEN 1 ELSE 0 END
WHEN @datesearchtype = 'paid' THEN CASE WHEN i.[Invoice_Paidon] >= @startdate AND i.[Invoice_Paidon] <= @enddate THEN 1 ELSE 0 END
ELSE 1
END = 1
AND
CASE --PAID/UNPAID/ALL INVOICE WHERE CLAUSE
WHEN @invoicepaidtype = 'paid' THEN CASE WHEN i.[Invoice_Paidon] IS NOT NULL THEN 1 ELSE 0 END
WHEN @invoicepaidtype = 'unpaid' THEN CASE WHEN i.[Invoice_Paidon] IS NULL THEN 1 ELSE 0 END
ELSE 1
END = 1
GROUP BY i.[InvoiceID], i.[Invoice_Number], i.[Invoice_Date], s.[Store_Number], d.[Driver_Name],
v.[Vehicle_Make_Year], v.[Vehicle_Make], v.[Vehicle_Model],
l.[License_Tag_State], l.[License_Tag_Number], i.[Invoice_Total_Amount],
(dbo.i.Invoice_Total_Amount - dbo.i.Prepaid_Total_Amount +
dbo.i.Invoice_TotalDiscounts + dbo.i.Invoice_TotalAdjustments -
dbo.i.Invoice_TotalPaymentsReceived),
(i.[Invoice_TotalDiscounts] + i.[Invoice_TotalAdjustments]), i.Invoice_TotalPaymentsReceived,
i.[Invoice_Rule_90], i.[Invoice_Rule_97], i.[Invoice_Rule_95]
ORDER BY
CASE WHEN @sortfield = 'Invoice_Number' AND @dir = 'asc' THEN i.[Invoice_Number] END ASC,
CASE WHEN @sortfield = 'Invoice_Number' AND @dir = 'desc' THEN i.[Invoice_Number] END DESC,
CASE WHEN @sortfield = 'Invoice_Date' AND @dir = 'asc' THEN i.[Invoice_Date] END ASC,
CASE WHEN @sortfield = 'Invoice_Date' AND @dir = 'desc' THEN i.[Invoice_Date] END DESC,
CASE WHEN @sortfield = 'Store_Number' AND @dir = 'asc' THEN s.[Store_Number] END ASC,
CASE WHEN @sortfield = 'Store_Number' AND @dir = 'desc' THEN s.[Store_Number] END DESC,
CASE WHEN @sortfield = 'Driver_Name' AND @dir = 'asc' THEN d.[Driver_Name] END ASC,
CASE WHEN @sortfield = 'Driver_Name' AND @dir = 'desc' THEN d.[Driver_Name] END DESC,
CASE WHEN @sortfield = 'Vehicle_Make' AND @dir = 'asc' THEN v.[Vehicle_Make] END ASC,
CASE WHEN @sortfield = 'Vehicle_Make' AND @dir = 'desc' THEN v.[Vehicle_Make] END DESC,
CASE WHEN @sortfield = 'Vehicle_Model' AND @dir = 'asc' THEN v.[Vehicle_Model] END ASC,
CASE WHEN @sortfield = 'Vehicle_Model' AND @dir = 'desc' THEN v.[Vehicle_Model] END DESC,
CASE WHEN @sortfield = 'License_Tag_Number' AND @dir = 'asc' THEN l.[License_Tag_Number] END ASC,
CASE WHEN @sortfield = 'License_Tag_Number' AND @dir = 'desc' THEN l.[License_Tag_Number] END DESC,
CASE WHEN @sortfield = '' THEN i.[Invoice_Date] END ASC;
END
|
|
#
¿
Feb 13, 2009 00:11
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
The query execution plan shows a clustered index seek on the [i] table of 42%, and 2 clustered index scans of 9% and 12%, which is what I'm sure is the killer. Looks like I'm going to have to go and make sure the indexes are all set up properly, and if that doesn't work, try rewriting with 'ifs' instead of 'case' statements.
On that note, the jackass that did the majority of the work on creating this db went loving nuts setting up indexes, like the same column is defined multiple times on the index screen, the PK is indexed more than once, etc. Is that a performance hit, or is SQL smart enough to only index the column once even though it is defined multiple times?
If anyone else has any solutions, I'm all ears.
|
|
#
¿
Feb 13, 2009 01:22
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
This is very interesting and I think it is what I am going to end up doing, too bad we don't have SQL 2008, as it looks like it would be able to optimize my original query.
edit:
I rewrote the query using the method in the link, and it runs obscenely fast.
Just-In-Timeberlake fucked around with this message at 18:21 on Feb 13, 2009
|
|
#
¿
Feb 13, 2009 15:23
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Edit: Actually found the answer to my question, this link has a nice writeup on how to handle external procedures in transactions.
Quick question about transactions and stored procedures, say I have a transaction like so (SQL 2005):
code:
BEGIN TRY
BEGIN TRANSACTION
/*CALL EXTERNAL STORED PROCEDURE*/
EXEC EXTERN_PROC @var1, @var2;
COMMIT TRANSACTION
END TRY
BEGIN CATCH
/* LOG ERROR, ETC. */
RAISERROR(@errmsg, @errsev, 1);
END CATCH
Just-In-Timeberlake fucked around with this message at 21:52 on Mar 11, 2009
|
|
#
¿
Mar 11, 2009 21:35
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Victor posted:
I'm actually not entirely sure. I've always had the feeling that the error handling/transaction rollback semantics of TSQL were ugly and different depending on who raised the error (whether it was the server or user code). Try/Catch helps some, but I honestly do not know if the transaction will be rolled back if your CATCH block is hit. I advise you to test this stuff. That's how I figure out a lot of things...
If I'm understanding the info in the link I posted, you have to put a RAISERROR() in the CATCH for the calling procedure to know that an error occurred.
Basically (again from what I got from the article, haven't fully tested it yet) your external procedure might be called by itself instead of from another procedure, and conceivably might need to be transactional as well. So you have the external procedure check to see if @@TRANCOUNT > 0, if it is, then the external procedure has no business managing the transaction, just raise an error and let the calling procedure manage the transaction. If @@TRANCOUNT = 0, then start a transaction, since the external procedure was called by itself.
Again, haven't tested the code yet.
|
|
#
¿
Mar 13, 2009 01:43
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I'm just getting into using the CLR to create TSQL procedures and I'm running into a problem with error handling. What I'm doing is creating a TSQL stored procedure that will call a CLR procedure (gets a response from a webpage). The TSQL stored proc will be running in a transactional space in a TRY/CATCH block and will need to catch any errors generated in the CLR proc and rollback the transaction. The problem is when I enlose the call to the CLR proc in a TRY/CATCH I get the following error:
"Msg 0, Level 11, State 0, Line 0
A severe error occurred on the current command. The results, if any, should be discarded."
Here is my TSQL code:
code:SET NOCOUNT ON;
BEGIN TRY
EXEC test;
END TRY
BEGIN CATCH
SELECT @@ERROR;
END CATCH
code:Partial Public Class StoredProcedures
<Microsoft.SqlServer.Server.SqlProcedure()> _
Public Shared Sub test ()
Using conn As New SqlConnection("context connection=true")
Dim cmd As New SqlCommand("Select 1/0", conn)
cmd.CommandTimeout = 6000
cmd.CommandType = CommandType.Text
conn.Open()
SqlContext.Pipe.ExecuteAndSend(cmd)
End Using
End Sub
End Class
Enclosing the offending CLR code in a TRY/CATCH block.
Having no TRY/CATCH in the CLR code (see example)
Built the CLR proc against both the 2.0 and 3.5 NET framework.
I am testing this on a SQL 2008 Dev edition install I have on my computer (No service packs, currently downloading SP2 to see if it helps)
Any ideas?
|
|
#
¿
Dec 6, 2010 22:21
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Well, I've kind of fixed my issue. If the error is in the query (Select 1/0) then it blows up. If the issue is .NET code (Convert.toInt32("abc")) then it handles the error ok.
Really wish there was a way to catch the query error though.
|
|
#
¿
Dec 7, 2010 20:10
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Ugh, I don't know why I have such an absurdly hard time wrapping my head around PIVOT/UNPIVOT, but before I bang my head bloody against my desk anymore, I figured I'd ask for help.
I have a table with a customer ID and a bunch of columns with rules, so it looks like this:
code:CustomerID [101] [102] [103]
--------------------------------------
123 1 0 0
code:[CategoryID] [CatCode] [CatDescription]
--------------------------------------------------
1 101 Some Description
Now, I think the solution is to somehow unpivot the first table with the CatCode in 1 column and the bit value in another, but I'm not seeing a way to do it. This is part of a development project and it's in the beginning stages so I can re-do the tables if necessary, I just figured it'd be better this way instead of a row for each value.
|
|
#
¿
Jan 10, 2011 17:51
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Aredna posted:
You really should change the first table so that you can join without worrying about the pivot/unpivot. There are many reasons, but one big one is that you don't want values as part of your column headers in case that changes.
I'd probably change the first table to be something like:
code:CustomerID CatCode Value
--------------------------------------
123 101 1
123 102 0
123 103 0
Yeah, I'll probably end up doing this, I was just hoping to avoid it. The other way just seemed more efficient to me for some reason.
|
|
#
¿
Jan 11, 2011 06:53
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
can someone help me out with this pivot, I'm a loving moron when it comes to this
I want to take these results:
code:name col value
---------------------------------------
guid name guid
guid value 9e1cb05b-a7ba-4283-abb4-29d0212ee303
label name label
label value Invoice issues
email name email
email value abc<at>abc.com
format name format
format value html
code:guid label email format
------------------------------------------------------
9e1... Invoi.... abc@... html
|
|
#
¿
Dec 20, 2017 20:41
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
i don't see how that's going to work, do you have another column that groups all the rows together? if not, how am i supposed to know that the label 'Invoice issues' goes along with the guid 9e1cb05b-a7ba-4283-abb4-29d0212ee303? but if you do have another column to group them, you can use crosstab or jsonb tricks in postgres, or pivot in sql server, or if you're using oracle or mysql then you get to gently caress yourself arseways
going by this SO post it's doable, I just can't get it to work
I should also clarify that the source data in my example above is the unpivoted data like in the link, I got that far at least.
|
|
#
¿
Dec 21, 2017 14:59
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
This request made me feel like god is dead just in time for Yule. Bravo on that timing.
Assuming that you are doing this as part of another, larger, process and you only want *one* row at the end --
SELECT email, [format], [guid], label
FROM
(SELECT r.*
FROM #temptbl r
WHERE col = 'value'
) r
pivot(MAX([value]) FOR r.name IN ([email],[format],[guid],[label])) p
thanks, I'll give this a shot after the holidays.
Just a weird requirement, but sometimes you gotta do dirty things and cash that check.
|
|
#
¿
Dec 22, 2017 10:41
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
This request made me feel like god is dead just in time for Yule. Bravo on that timing.
Assuming that you are doing this as part of another, larger, process and you only want *one* row at the end --
SELECT email, [format], [guid], label
FROM
(SELECT r.*
FROM #temptbl r
WHERE col = 'value'
) r
pivot(MAX([value]) FOR r.name IN ([email],[format],[guid],[label])) p
This worked by the way, so thanks!
|
|
#
¿
Dec 29, 2017 19:28
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
This is all TSQL
Currently when we make notes on customer accounts the notes are sequential. I'd like to make it so users can respond to a particular note, and respond to that note, etc. I think what I'm looking for is a CTE and recursion to get these all in the right order when queried, but I'm not sure, or if I need another table to handle this.
For this example my table looks something like this for simplicities sake:
code: NoteId | Note | RespondingToNoteId
In the end, I'd like my output to look something like this
code: Note 1
| |---Response to Note 1
| | |---Response to first response
| | |---Response to second response
| |---Second response to Note 1
| |---Third response to Note 1
Note 2
|
|
#
¿
Sep 9, 2019 21:19
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I'm in a car hundreds of miles from home and a pc.
I banged out a recursive CTE that sorta worked but used a string of delimited noteids to help sort the data that likely had problems when sorting lexigraphically vs. numerically so I scrapped it and instead found this:
HIERARCHYID data type
I bet this will get you very far along in solving your problem.
drat, that looks slick as hell, thanks
|
|
#
¿
Sep 10, 2019 20:12
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Cross posting from AWS thread:
I have a client that wants to migrate two MSSQL database servers with 200+ db objects between them to AWS Cloud. Now, up until this point we've been fine using Data Migration Service to move the table data from their on-prem servers into AWS. The problem is that DMS doesn't migrate indexes, users, privileges, stored procedures, and other database changes not directly related to table data. So now we have generate scripts by hand for these 200+, at minimum, objects. What I'm asking is, is there some hacky way to automate this migration or are we just stuck having to do it all by hand over and over again?
a quick Google search uncovered this that might be of help
https://www.mssqltips.com/sqlservertip/4606/generate-tsql-scripts-for-all-sql-server-databases-and-all-objects-using-powershell/
|
|
#
¿
Sep 24, 2019 22:11
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I'd say you'd be right to be concerned.
Maybe? The alternatives don't seem to have gotten much better since last I checked.
tyool 2019 and still no "for each row in query" loop method in TSQL, smdh.
|
|
#
¿
Oct 2, 2019 20:10
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
yeah, when it got to the part where they were rolling their own PKs I had to make sure I wasn't reading the Onion
|
|
#
¿
Oct 15, 2019 20:58
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
it's on this online service snowflake. it's its own thing. https://www.snowflake.com/
its sql language is largely similar to t-sql or mysql, but you're VERY limited beyond basic dml and basic ddl. like i can't create functions or sprocs or anything like that.
man that product name is loving on the nose
|
|
#
¿
Oct 23, 2019 21:46
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Probably a better way to do it, but quick and dirty and works
code: Select users.*
, startTbl.coins `start coins`
, endTbl.coins `end coins`
, startTbl.created_on `start date`
, endTbl.created_on `end date`
, endTbl.coins - startTbl.coins `change`
from users
inner join
(SELECT *
from coin_counts
where coin_counts.created_on <= '2020-01-01'
order by created_on desc
limit 1) endTbl on users.id = endTbl.user_id
inner join
(SELECT *
from coin_counts
where coin_counts.created_on >= '2019-04-01'
order by created_on asc
limit 1) startTbl on users.id = startTbl.user_id
|
|
#
¿
Dec 13, 2019 00:20
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Actually, here's maybe a really dumb question that's only tangentially related. I'm doing this to build a new report for our system that has to select and filter data from lots and lots of tables, some containing millions of rows. At a certain point, is it ever a good idea to build out cached versions of this data in either an SQL table built specifically for this report, or even a separate db like Mongo or DynamoDB or something? Basically imagine this schema I posted except there's several other tables similar to "coin_counts" and also multiple other join tables between "users" and "coin_counts."
Like am I still in the realm of things that SQL was built to handle well or would it be smarter to offload some of this to something else entirely? It feels silly to duplicate the data but at the same time some of the pathways you have to take through the DB to get the right data are pretty daunting, especially because the end user is also supposed to be able to filter this report. i.e. coin_counts don't actually belong directly to users, they belong to purses, and purses are joined in a users_purses table because multiple users can share multiple purses. And the end users of the report want to see totals, but also see those totals broken down by the coin_counts in the users' Gucci purse vs. their Chanel purse, or opt to filter to only get totals from Gucci purses in the first place.
Also just to be clear this isn't some crypto app or dealing with actual money in any way I'm just trying to come up with analogy that works. And maybe the real answer here is hire a DBA.
I'm not a DBA by education, just by being the guy that got hired and learned (and still learning) a bunch of poo poo along the way.
When I got hired most of our reporting was dogshit slow, and the solutions getting suggested were similar, faster hardware, dedicated hardware for reporting, etc. Basically throw money at the problem. Instead I went through all the problem report queries with the query analyzer, got everything indexed properly, rewrote most of the queries to make them more performant, and now reports that used to take 10 minutes to run take under 10 seconds.
So if you gotta start somewhere, I'd start with the query analyzer if things aren't fast.
|
|
#
¿
Dec 13, 2019 16:32
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I'm pretty sure (though it's been a few years since I've done anything outside of Oracle), that you can't do a for each trigger in MS SQL. Unless you did something like create a cursor in the trig...Nope, can't finish that thought.
That is exactly what you have to do.
|
|
#
¿
Jan 25, 2020 16:57
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
they are a pain in the rear end though
Used sanely they are fine and can save you from yourself.
|
|
#
¿
Jan 28, 2020 17:35
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Speaking of which, if you have MSSQL, system-versioned temporal tables are great and I wish I had them in Postgres. You can implement something similar with triggers, but you can't get the query syntax and that's half the fun.
That's slick as gently caress.
|
|
#
¿
Jan 28, 2020 20:30
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Maybe I'll just post some of the classic ASP code and dynamically created SQL queries I inherited when I took on this job a gazillion years ago and drive you all into an alcohol induced coma.
|
|
#
¿
Feb 21, 2020 22:05
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
That is a loving sexy query
that query fucks
|
|
#
¿
Feb 27, 2020 20:36
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
At first glance this looks like a job for a CTE and recursion
|
|
#
¿
Mar 6, 2020 16:32
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I'm a doofus who just spent 30 minutes trying to figure out why a query was returning 65,535 rows before figuring out it was a coincidence.
Don't be like me.
|
|
#
¿
Mar 31, 2020 17:16
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Not sure if this is a SQL solution or something else so asking for opinions.
Say you have 90k+ text files (~3gb), with several different file formats
What would be the best way to store and search them if you couldn't use a simple file search? (I wrote a file search app on steroids to do that and it works aces, but going forward this won't be an option)
I'm considering the following:
- load each file into MSSQL using a FULLTEXT index (either the whole file per record or parse each row into its own record). Pro: I know how to do this already
- Use ElasticSearch or Solr (or something similar). Con: I know gently caress all about these and would have to figure it out
Any opinions? Pros/Cons?
|
|
#
¿
Apr 22, 2020 20:40
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Can anybody suggest a solution for a query running slowly in a stored procedure but fast in a query window? It takes ~7 seconds in a query window and 1-2 minutes in a stored procedure.
I've tried the following:
- parameter sniffing: created local variables and assigned the two date values passed in to them, no change in performance
- OPTION (RECOMPILE) - no change in performance
- OPTION (OPTIMIZE FOR (@startDate UNKNOWN, @endDate UNKNOWN)) - no change in performance
- Made sure SET ANSI_NULLS is set to ON
Those are the major things I know to check for and at least one of them has solved the problem in the past, but not this time.
MSSQL 2014 is the version I'm using.
|
|
#
¿
Aug 17, 2020 21:41
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
Running the actual execution plan for both shows this, which I'm sure is the problem, but I'm not sure how to fix it:
In the query window execution plan, there is an index seek, but in the stored procedure execution plan it becomes an index scan
edit: I found the (FORCESEEK) hint and it works as it should now.
Just-In-Timeberlake fucked around with this message at 15:20 on Aug 18, 2020
|
|
#
¿
Aug 18, 2020 15:14
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
To be honest, access has enough of a learning curve that I'm not sure how much better off you'd be with access over just installing a database like mysql or postgres and using those front end tools like phpmyadmin or pgadmin. I wouldn't say the UIs for pgadmin/phpmyadmin are very good, but access is opaque and using access doesn't translate to any other program.
Nonsense, if they use Access then the next person to deal with it gets to curse their name for all eternity
|
|
#
¿
Oct 14, 2020 18:11
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
I have a table recording IPs and time (among some other things) when a page is hit.
I'd like to be able to run some queries against both the total hits and the unique hits. I had assumed grouping by IPs would do the trick but MySQL doesn't like that anymore and I get an error:
code:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column
I've added a 'unique' boolean column to the table which sets to true each time a new IP is entered. It works fine for now but it feels like this should be a fairly simple query but I'm just drawing a blank on it.
I suppose what I want is to be able to just select a row if it's the first time that IP shows up.
I�m not a MySQL expert by any means but I think
code:set session sql_mode='';
is what you�re looking for
|
|
#
¿
Nov 13, 2020 20:45
|
|
- Adbot
-
ADBOT LOVES YOU
|

|
|
#
¿
May 17, 2024 20:17
|
|
- Just-In-Timeberlake
- Aug 18, 2003
-
|
e: nevermind, figured it out
Is there a way to write a pivot table to pivot on a common value in a column in TSQL? For example, if I have this:
code:
col1 | col 2
----------------------------
0 | value1
0 | value2
1 | value1
1 | value2
code:col1 | col2 | col 3
------------------------------------------------
0 | value1 | value2
1 | value1 | value2
Just-In-Timeberlake fucked around with this message at 14:48 on Dec 10, 2021
|
|
#
¿
Dec 10, 2021 14:02
|
|



 #
¿
Sep 11, 2008 22:26
#
¿
Sep 11, 2008 22:26